 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffBMP: Differentiable Rendering with Bitmap Primitives
Feb 26, 2026We introduce DiffBMP, a scalable and efficient differentiable rendering engine for a collection of bitmap images. Our work addresses a limitation that traditional differentiable renderers are constrained to vector graphics, given that most images in the world are bitmaps. Our core contribution is a highly parallelized rendering pipeline, featuring a custom CUDA implementation for calculating gradients. This system can, for example, optimize the position, rotation, scale, color, and opacity of thousands of bitmap primitives all in under 1 min using a consumer GPU. We employ and validate several techniques to facilitate the optimization: soft rasterization via Gaussian blur, structure-aware initialization, noisy canvas, and specialized losses/heuristics for videos or spatially constrained images. We demonstrate DiffBMP is not just an isolated tool, but a practical one designed to integrate into creative workflows. It supports exporting compositions to a native, layered file format, and the entire framework is publicly accessible via an easy-to-hack Python package.
Monotonic Simultaneous Translation with Chunk-wise Reordering and Refinement
Oct 18, 2021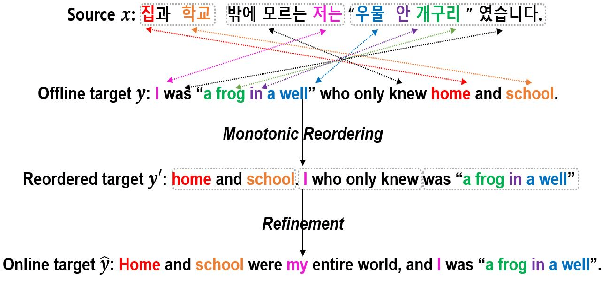
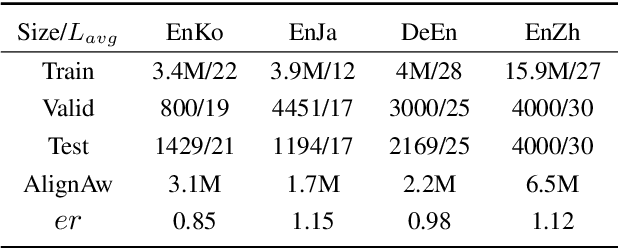
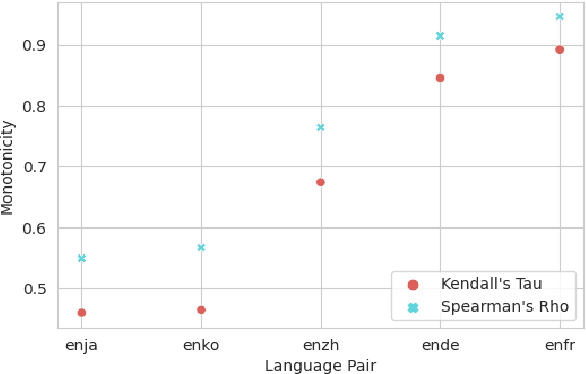
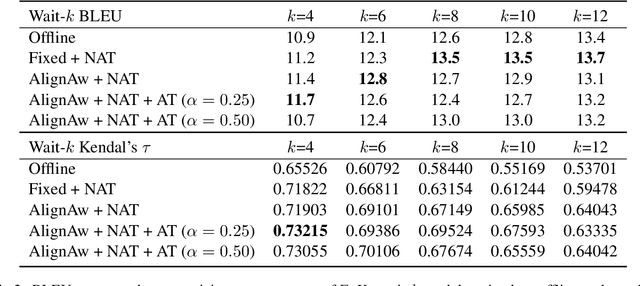
Recent work in simultaneous machine translation is often trained with conventional full sentence translation corpora, leading to either excessive latency or necessity to anticipate as-yet-unarrived words, when dealing with a language pair whose word orders significantly differ. This is unlike human simultaneous interpreters who produce largely monotonic translations at the expense of the grammaticality of a sentence being translated. In this paper, we thus propose an algorithm to reorder and refine the target side of a full sentence translation corpus, so that the words/phrases between the source and target sentences are aligned largely monotonically, using word alignment and non-autoregressive neural machine translation. We then train a widely used wait-k simultaneous translation model on this reordered-and-refined corpus. The proposed approach improves BLEU scores and resulting translations exhibit enhanced monotonicity with source sentences.
Extremely Low Bit Transformer Quantization for On-Device Neural Machine Translation
Oct 13, 2020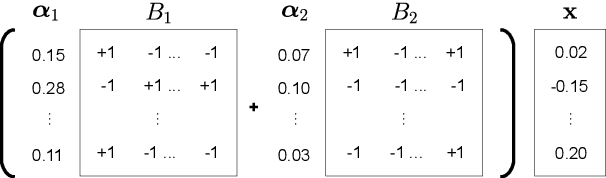
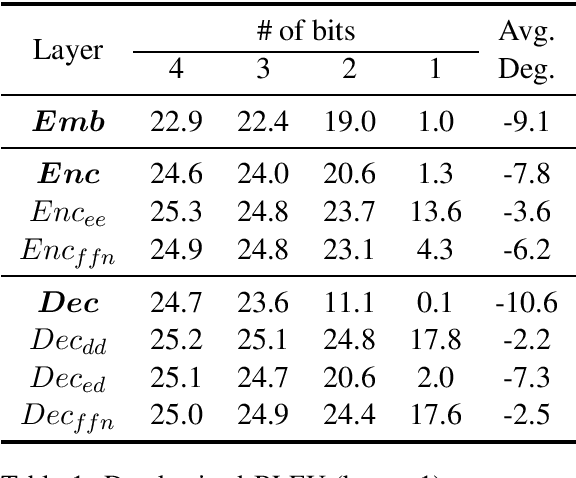
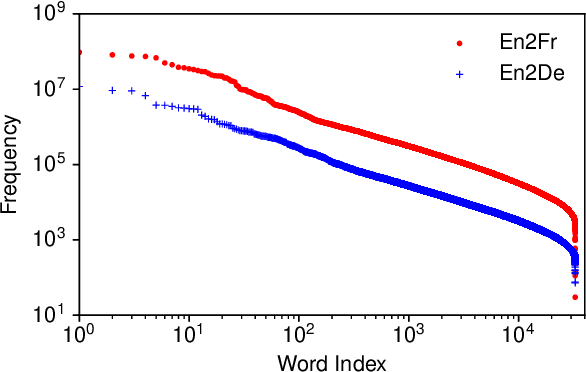
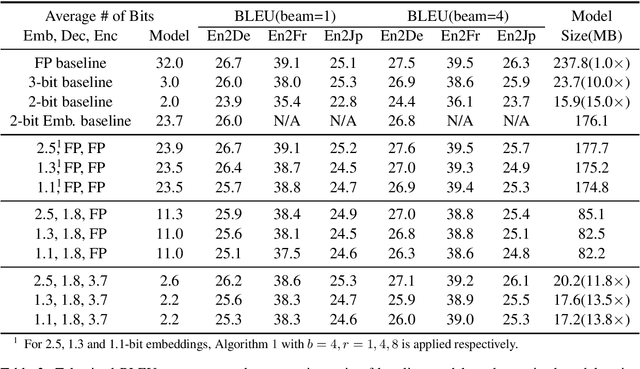
The deployment of widely used Transformer architecture is challenging because of heavy computation load and memory overhead during inference, especially when the target device is limited in computational resources such as mobile or edge devices. Quantization is an effective technique to address such challenges. Our analysis shows that for a given number of quantization bits, each block of Transformer contributes to translation quality and inference computations in different manners. Moreover, even inside an embedding block, each word presents vastly different contributions. Correspondingly, we propose a mixed precision quantization strategy to represent Transformer weights by an extremely low number of bits (e.g., under 3 bits). For example, for each word in an embedding block, we assign different quantization bits based on statistical property. Our quantized Transformer model achieves 11.8$\times$ smaller model size than the baseline model, with less than -0.5 BLEU. We achieve 8.3$\times$ reduction in run-time memory footprints and 3.5$\times$ speed up (Galaxy N10+) such that our proposed compression strategy enables efficient implementation for on-device NMT.
Data Efficient Direct Speech-to-Text Translation with Modality Agnostic Meta-Learning
Nov 11, 2019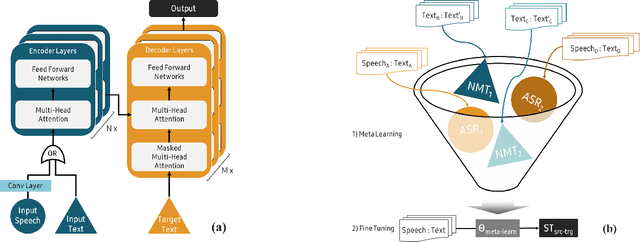

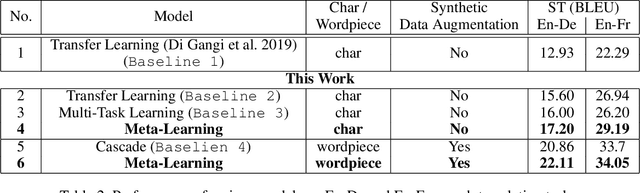
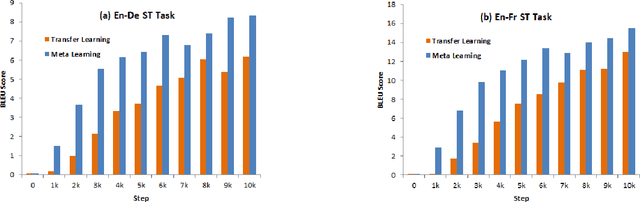
End-to-end Speech Translation (ST) models have several advantages such as lower latency, smaller model size, and less error compounding over conventional pipelines that combine Automatic Speech Recognition (ASR) and text Machine Translation (MT) models. However, collecting large amounts of parallel data for ST task is more difficult compared to the ASR and MT tasks. Previous studies have proposed the use of transfer learning approaches to overcome the above difficulty. These approaches benefit from weakly supervised training data, such as ASR speech-to-transcript or MT text-to-text translation pairs. However, the parameters in these models are updated independently of each task, which may lead to sub-optimal solutions. In this work, we adopt a meta-learning algorithm to train a modality agnostic multi-task model that transfers knowledge from source tasks=ASR+MT to target task=ST where ST task severely lacks data. In the meta-learning phase, the parameters of the model are exposed to vast amounts of speech transcripts (e.g., English ASR) and text translations (e.g., English-German MT). During this phase, parameters are updated in such a way to understand speech, text representations, the relation between them, as well as act as a good initialization point for the target ST task. We evaluate the proposed meta-learning approach for ST tasks on English-German (En-De) and English-French (En-Fr) language pairs from the Multilingual Speech Translation Corpus (MuST-C). Our method outperforms the previous transfer learning approaches and sets new state-of-the-art results for En-De and En-Fr ST tasks by obtaining 9.18, and 11.76 BLEU point improvements, respectively.