 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHILL at SemEval-2025 Task 2: You Can't Just Throw Entities and Hope -- Make Your LLM to Get Them Right
Jun 16, 2025In this paper, we describe our approach for the SemEval 2025 Task 2 on Entity-Aware Machine Translation (EA-MT). Our system aims to improve the accuracy of translating named entities by combining two key approaches: Retrieval Augmented Generation (RAG) and iterative self-refinement techniques using Large Language Models (LLMs). A distinctive feature of our system is its self-evaluation mechanism, where the LLM assesses its own translations based on two key criteria: the accuracy of entity translations and overall translation quality. We demonstrate how these methods work together and effectively improve entity handling while maintaining high-quality translations.
Monotonic Simultaneous Translation with Chunk-wise Reordering and Refinement
Oct 18, 2021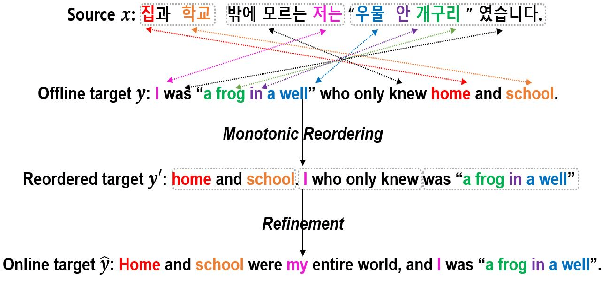
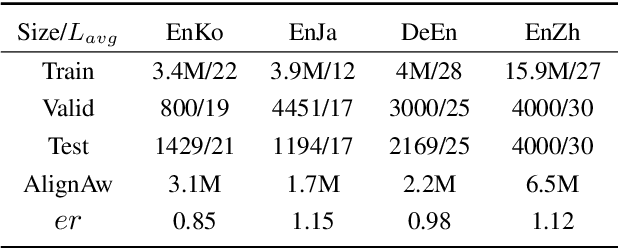
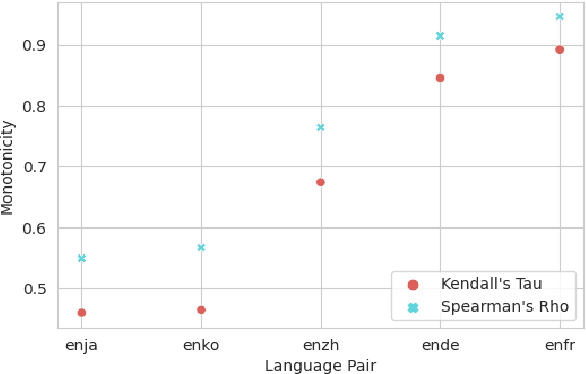
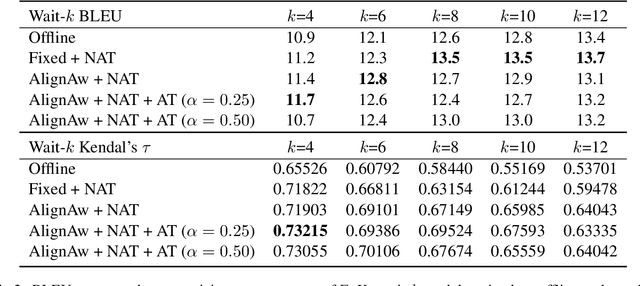
Recent work in simultaneous machine translation is often trained with conventional full sentence translation corpora, leading to either excessive latency or necessity to anticipate as-yet-unarrived words, when dealing with a language pair whose word orders significantly differ. This is unlike human simultaneous interpreters who produce largely monotonic translations at the expense of the grammaticality of a sentence being translated. In this paper, we thus propose an algorithm to reorder and refine the target side of a full sentence translation corpus, so that the words/phrases between the source and target sentences are aligned largely monotonically, using word alignment and non-autoregressive neural machine translation. We then train a widely used wait-k simultaneous translation model on this reordered-and-refined corpus. The proposed approach improves BLEU scores and resulting translations exhibit enhanced monotonicity with source sentences.
Extremely Low Bit Transformer Quantization for On-Device Neural Machine Translation
Oct 13, 2020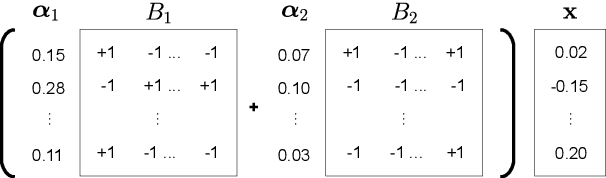
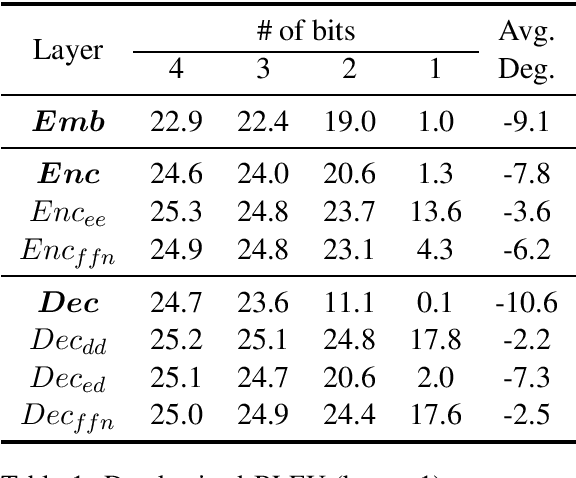
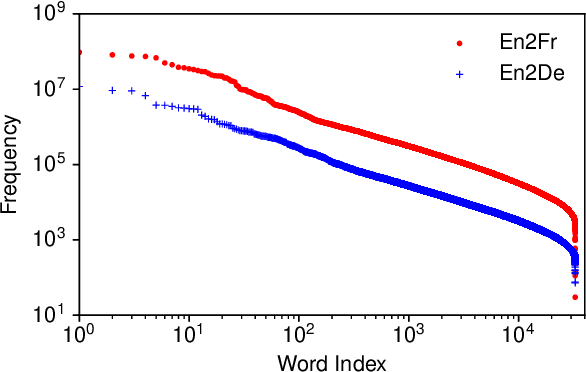
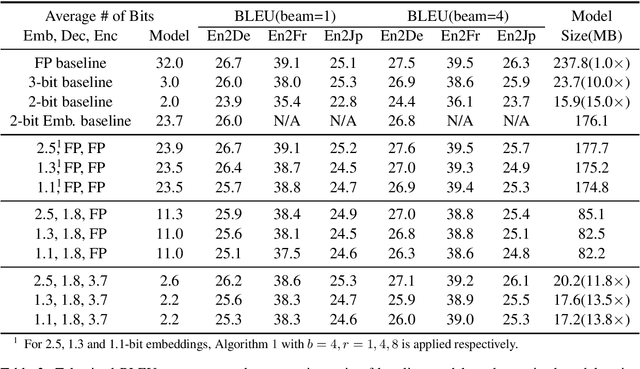
The deployment of widely used Transformer architecture is challenging because of heavy computation load and memory overhead during inference, especially when the target device is limited in computational resources such as mobile or edge devices. Quantization is an effective technique to address such challenges. Our analysis shows that for a given number of quantization bits, each block of Transformer contributes to translation quality and inference computations in different manners. Moreover, even inside an embedding block, each word presents vastly different contributions. Correspondingly, we propose a mixed precision quantization strategy to represent Transformer weights by an extremely low number of bits (e.g., under 3 bits). For example, for each word in an embedding block, we assign different quantization bits based on statistical property. Our quantized Transformer model achieves 11.8$\times$ smaller model size than the baseline model, with less than -0.5 BLEU. We achieve 8.3$\times$ reduction in run-time memory footprints and 3.5$\times$ speed up (Galaxy N10+) such that our proposed compression strategy enables efficient implementation for on-device NMT.