 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Compression by Unstructured Pruning for Sparse Quantized Neural Networks
Paper and Code
May 24, 2019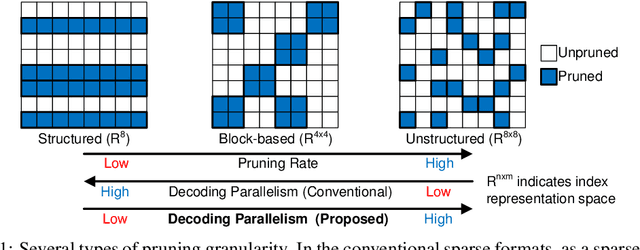
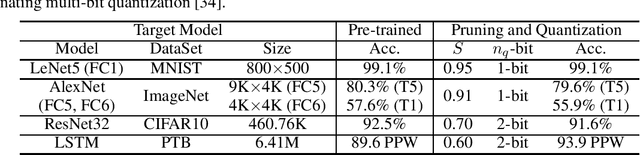
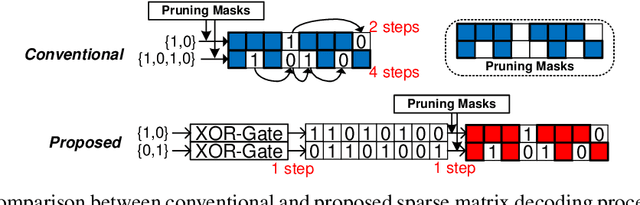
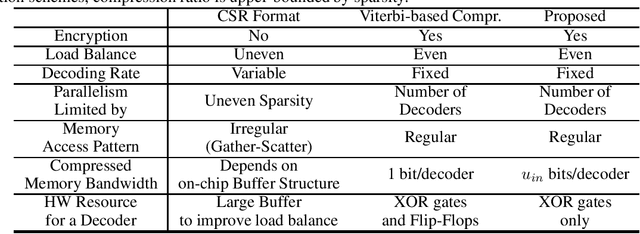
Model compression techniques, such as pruning and quantization, are becoming increasingly important to reduce the memory footprints and the amount of computations. Despite model size reduction, achieving performance enhancement on devices is, however, still challenging mainly due to the irregular representations of sparse matrix formats. This paper proposes a new representation to encode the weights of Sparse Quantized Neural Networks, specifically reduced by find-grained and unstructured pruning method. The representation is encoded in a structured regular format, which can be efficiently decoded through XOR gates during inference in a parallel manner. We demonstrate various deep learning models that can be compressed and represented by our proposed format with fixed and high compression ratio. For example, for fully-connected layers of AlexNet on ImageNet dataset, we can represent the sparse weights by only 0.09 bits/weight for 1-bit quantization and 91\% pruning rate with a fixed decoding rate and full memory bandwidth usage.