 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshVPR: Citywide Visual Place Recognition Using 3D Meshes
Jun 04, 2024



Mesh-based scene representation offers a promising direction for simplifying large-scale hierarchical visual localization pipelines, combining a visual place recognition step based on global features (retrieval) and a visual localization step based on local features. While existing work demonstrates the viability of meshes for visual localization, the impact of using synthetic databases rendered from them in visual place recognition remains largely unexplored. In this work we investigate using dense 3D textured meshes for large-scale Visual Place Recognition (VPR) and identify a significant performance drop when using synthetic mesh-based databases compared to real-world images for retrieval. To address this, we propose MeshVPR, a novel VPR pipeline that utilizes a lightweight features alignment framework to bridge the gap between real-world and synthetic domains. MeshVPR leverages pre-trained VPR models and it is efficient and scalable for city-wide deployments. We introduce novel datasets with freely available 3D meshes and manually collected queries from Berlin, Paris, and Melbourne. Extensive evaluations demonstrate that MeshVPR achieves competitive performance with standard VPR pipelines, paving the way for mesh-based localization systems. Our contributions include the new task of citywide mesh-based VPR, the new benchmark datasets, MeshVPR, and a thorough analysis of open challenges. Data, code, and interactive visualizations are available at https://mesh-vpr.github.io
IVS3D: An Open Source Framework for Intelligent Video Sampling and Preprocessing to Facilitate 3D Reconstruction
Oct 22, 2021


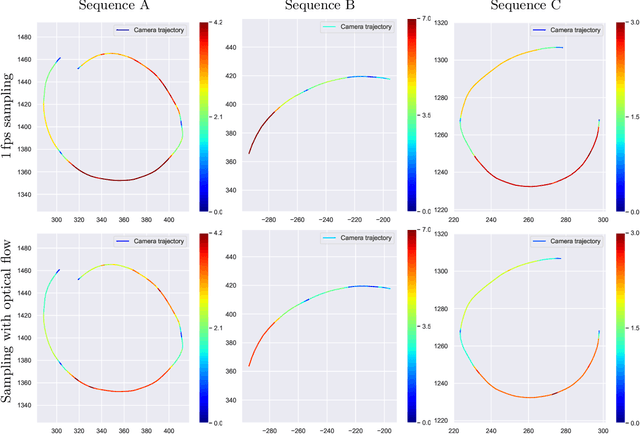
The creation of detailed 3D models is relevant for a wide range of applications such as navigation in three-dimensional space, construction planning or disaster assessment. However, the complex processing and long execution time for detailed 3D reconstructions require the original database to be reduced in order to obtain a result in reasonable time. In this paper we therefore present our framework iVS3D for intelligent pre-processing of image sequences. Our software is able to down sample entire videos to a specific frame rate, as well as to resize and crop the individual images. Furthermore, thanks to our modular architecture, it is easy to develop and integrate plugins with additional algorithms. We provide three plugins as baseline methods that enable an intelligent selection of suitable images and can enrich them with additional information. To filter out images affected by motion blur, we developed a plugin that detects these frames and also searches the spatial neighbourhood for suitable images as replacements. The second plugin uses optical flow to detect redundant images caused by a temporarily stationary camera. In our experiments, we show how this approach leads to a more balanced image sampling if the camera speed varies, and that excluding such redundant images leads to a time saving of 8.1\percent for our sequences. A third plugin makes it possible to exclude challenging image regions from the 3D reconstruction by performing semantic segmentation. As we think that the community can greatly benefit from such an approach, we will publish our framework and the developed plugins open source using the MIT licence to allow co-development and easy extension.
Efficient Surface-Aware Semi-Global Matching with Multi-View Plane-Sweep Sampling
Sep 21, 2019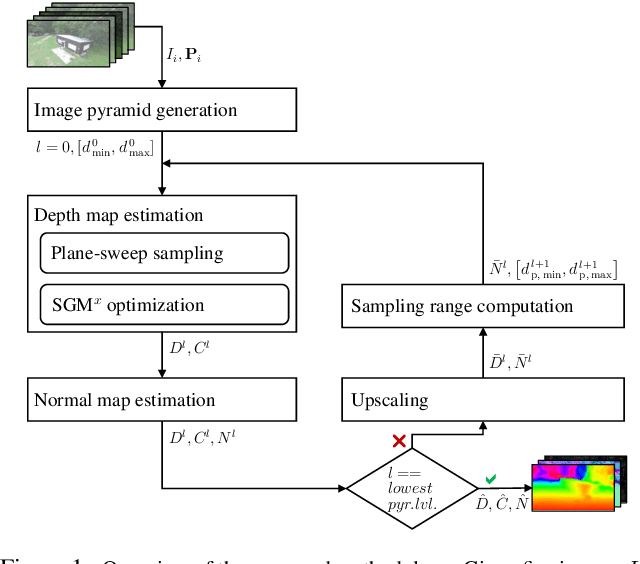
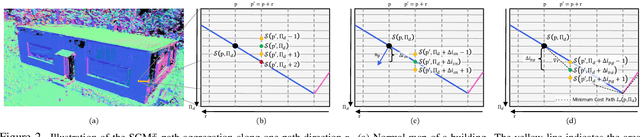
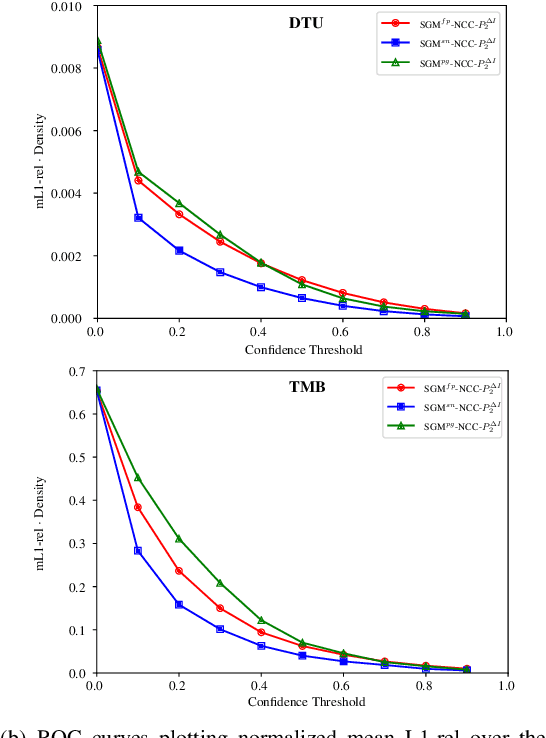
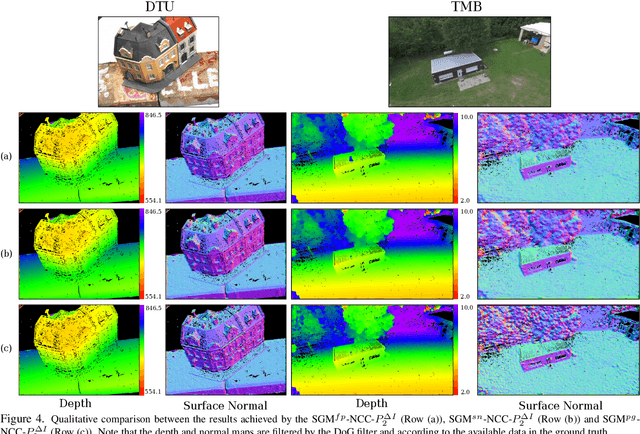
Online augmentation of an oblique aerial image sequence with structural information is an essential aspect in the process of 3D scene interpretation and analysis. One key aspect in this is the efficient dense image matching and depth estimation. Here, the Semi-Global Matching (SGM) approach has proven to be one of the most widely used algorithms for efficient depth estimation, providing a good trade-off between accuracy and computational complexity. However, SGM only models a first-order smoothness assumption, thus favoring fronto-parallel surfaces. In this work, we present a hierarchical algorithm that allows for efficient depth and normal map estimation together with confidence measures for each estimate. Our algorithm relies on a plane-sweep multi-image matching followed by an extended SGM optimization that allows to incorporate local surface orientations, thus achieving more consistent and accurate estimates in areasmade up of slanted surfaces, inherent to oblique aerial imagery. We evaluate numerous configurations of our algorithm on two different datasets using an absolute and relative accuracy measure. In our evaluation, we show that the results of our approach are comparable to the ones achieved by refined Structure-from-Motion (SfM) pipelines, such as COLMAP, which are designed for offline processing. In contrast, however, our approach only considers a confined image bundle of an input sequence, thus allowing to perform an online and incremental computation at 1Hz-2Hz.