 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIVS3D: An Open Source Framework for Intelligent Video Sampling and Preprocessing to Facilitate 3D Reconstruction
Oct 22, 2021


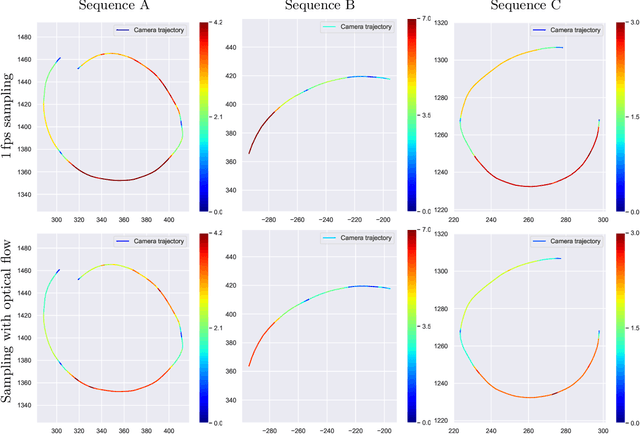
The creation of detailed 3D models is relevant for a wide range of applications such as navigation in three-dimensional space, construction planning or disaster assessment. However, the complex processing and long execution time for detailed 3D reconstructions require the original database to be reduced in order to obtain a result in reasonable time. In this paper we therefore present our framework iVS3D for intelligent pre-processing of image sequences. Our software is able to down sample entire videos to a specific frame rate, as well as to resize and crop the individual images. Furthermore, thanks to our modular architecture, it is easy to develop and integrate plugins with additional algorithms. We provide three plugins as baseline methods that enable an intelligent selection of suitable images and can enrich them with additional information. To filter out images affected by motion blur, we developed a plugin that detects these frames and also searches the spatial neighbourhood for suitable images as replacements. The second plugin uses optical flow to detect redundant images caused by a temporarily stationary camera. In our experiments, we show how this approach leads to a more balanced image sampling if the camera speed varies, and that excluding such redundant images leads to a time saving of 8.1\percent for our sequences. A third plugin makes it possible to exclude challenging image regions from the 3D reconstruction by performing semantic segmentation. As we think that the community can greatly benefit from such an approach, we will publish our framework and the developed plugins open source using the MIT licence to allow co-development and easy extension.
Real-time dense 3D Reconstruction from monocular video data captured by low-cost UAVs
Apr 21, 2021

Real-time 3D reconstruction enables fast dense mapping of the environment which benefits numerous applications, such as navigation or live evaluation of an emergency. In contrast to most real-time capable approaches, our approach does not need an explicit depth sensor. Instead, we only rely on a video stream from a camera and its intrinsic calibration. By exploiting the self-motion of the unmanned aerial vehicle (UAV) flying with oblique view around buildings, we estimate both camera trajectory and depth for selected images with enough novel content. To create a 3D model of the scene, we rely on a three-stage processing chain. First, we estimate the rough camera trajectory using a simultaneous localization and mapping (SLAM) algorithm. Once a suitable constellation is found, we estimate depth for local bundles of images using a Multi-View Stereo (MVS) approach and then fuse this depth into a global surfel-based model. For our evaluation, we use 55 video sequences with diverse settings, consisting of both synthetic and real scenes. We evaluate not only the generated reconstruction but also the intermediate products and achieve competitive results both qualitatively and quantitatively. At the same time, our method can keep up with a 30 fps video for a resolution of 768x448 pixels.
Self-Supervised Learning for Monocular Depth Estimation from Aerial Imagery
Aug 17, 2020
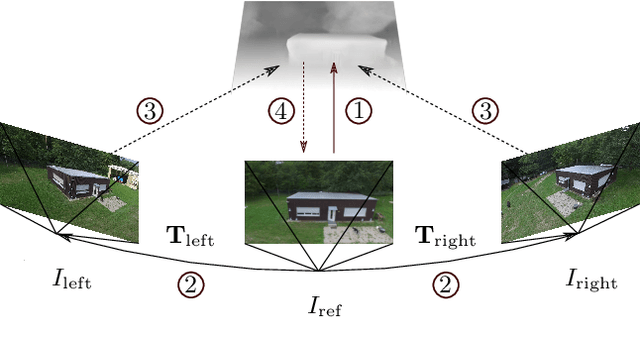

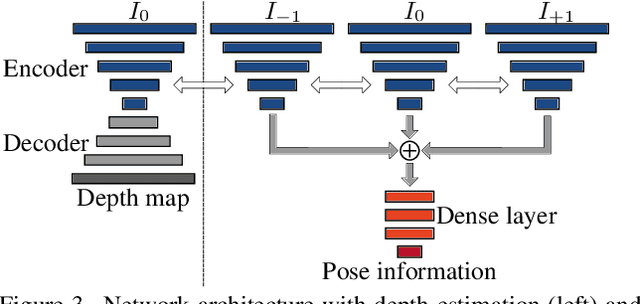
Supervised learning based methods for monocular depth estimation usually require large amounts of extensively annotated training data. In the case of aerial imagery, this ground truth is particularly difficult to acquire. Therefore, in this paper, we present a method for self-supervised learning for monocular depth estimation from aerial imagery that does not require annotated training data. For this, we only use an image sequence from a single moving camera and learn to simultaneously estimate depth and pose information. By sharing the weights between pose and depth estimation, we achieve a relatively small model, which favors real-time application. We evaluate our approach on three diverse datasets and compare the results to conventional methods that estimate depth maps based on multi-view geometry. We achieve an accuracy {\delta}1.25 of up to 93.5 %. In addition, we have paid particular attention to the generalization of a trained model to unknown data and the self-improving capabilities of our approach. We conclude that, even though the results of monocular depth estimation are inferior to those achieved by conventional methods, they are well suited to provide a good initialization for methods that rely on image matching or to provide estimates in regions where image matching fails, e.g. occluded or texture-less regions.