 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaSS-MVS -- Fast Multi-View Stereo with Surface-Aware Semi-Global Matching from UAV-borne Monocular Imagery
Dec 01, 2021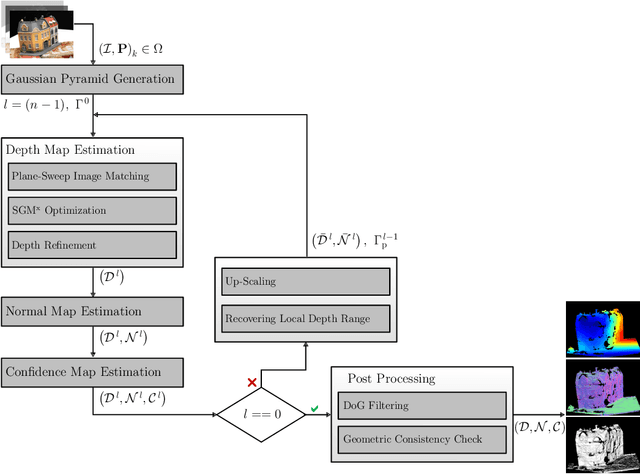

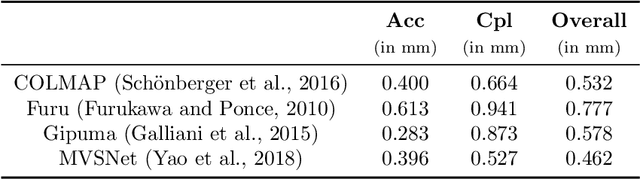
With FaSS-MVS, we present an approach for fast multi-view stereo with surface-aware Semi-Global Matching that allows for rapid depth and normal map estimation from monocular aerial video data captured by UAVs. The data estimated by FaSS-MVS, in turn, facilitates online 3D mapping, meaning that a 3D map of the scene is immediately and incrementally generated while the image data is acquired or being received. FaSS-MVS is comprised of a hierarchical processing scheme in which depth and normal data, as well as corresponding confidence scores, are estimated in a coarse-to-fine manner, allowing to efficiently process large scene depths which are inherent to oblique imagery captured by low-flying UAVs. The actual depth estimation employs a plane-sweep algorithm for dense multi-image matching to produce depth hypotheses from which the actual depth map is extracted by means of a surface-aware semi-global optimization, reducing the fronto-parallel bias of SGM. Given the estimated depth map, the pixel-wise surface normal information is then computed by reprojecting the depth map into a point cloud and calculating the normal vectors within a confined local neighborhood. In a thorough quantitative and ablative study we show that the accuracies of the 3D information calculated by FaSS-MVS is close to that of state-of-the-art approaches for offline multi-view stereo, with the error not even being one magnitude higher than that of COLMAP. At the same time, however, the average run-time of FaSS-MVS to estimate a single depth and normal map is less than 14 % of that of COLMAP, allowing to perform an online and incremental processing of Full-HD imagery at 1-2 Hz.
ReS2tAC -- UAV-Borne Real-Time SGM Stereo Optimized for Embedded ARM and CUDA Devices
Jun 15, 2021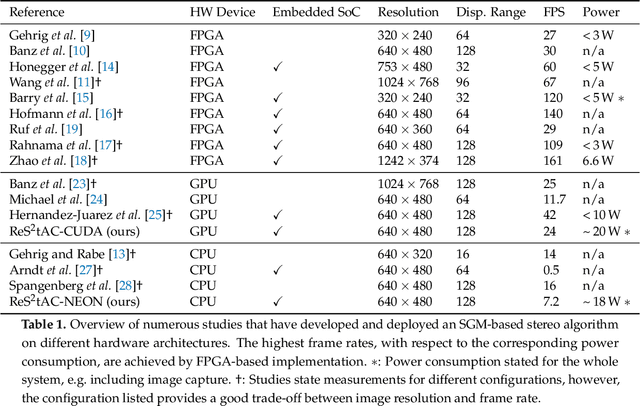



With the emergence of low-cost robotic systems, such as unmanned aerial vehicle, the importance of embedded high-performance image processing has increased. For a long time, FPGAs were the only processing hardware that were capable of high-performance computing, while at the same time preserving a low power consumption, essential for embedded systems. However, the recently increasing availability of embedded GPU-based systems, such as the NVIDIA Jetson series, comprised of an ARM CPU and a NVIDIA Tegra GPU, allows for massively parallel embedded computing on graphics hardware. With this in mind, we propose an approach for real-time embedded stereo processing on ARM and CUDA-enabled devices, which is based on the popular and widely used Semi-Global Matching algorithm. In this, we propose an optimization of the algorithm for embedded CUDA GPUs, by using massively parallel computing, as well as using the NEON intrinsics to optimize the algorithm for vectorized SIMD processing on embedded ARM CPUs. We have evaluated our approach with different configurations on two public stereo benchmark datasets to demonstrate that they can reach an error rate as low as 3.3%. Furthermore, our experiments show that the fastest configuration of our approach reaches up to 46 FPS on VGA image resolution. Finally, in a use-case specific qualitative evaluation, we have evaluated the power consumption of our approach and deployed it on the DJI Manifold 2-G attached to a DJI Matrix 210v2 RTK unmanned aerial vehicle (UAV), demonstrating its suitability for real-time stereo processing onboard a UAV.
Real-time dense 3D Reconstruction from monocular video data captured by low-cost UAVs
Apr 21, 2021

Real-time 3D reconstruction enables fast dense mapping of the environment which benefits numerous applications, such as navigation or live evaluation of an emergency. In contrast to most real-time capable approaches, our approach does not need an explicit depth sensor. Instead, we only rely on a video stream from a camera and its intrinsic calibration. By exploiting the self-motion of the unmanned aerial vehicle (UAV) flying with oblique view around buildings, we estimate both camera trajectory and depth for selected images with enough novel content. To create a 3D model of the scene, we rely on a three-stage processing chain. First, we estimate the rough camera trajectory using a simultaneous localization and mapping (SLAM) algorithm. Once a suitable constellation is found, we estimate depth for local bundles of images using a Multi-View Stereo (MVS) approach and then fuse this depth into a global surfel-based model. For our evaluation, we use 55 video sequences with diverse settings, consisting of both synthetic and real scenes. We evaluate not only the generated reconstruction but also the intermediate products and achieve competitive results both qualitatively and quantitatively. At the same time, our method can keep up with a 30 fps video for a resolution of 768x448 pixels.
Self-Supervised Learning for Monocular Depth Estimation from Aerial Imagery
Aug 17, 2020
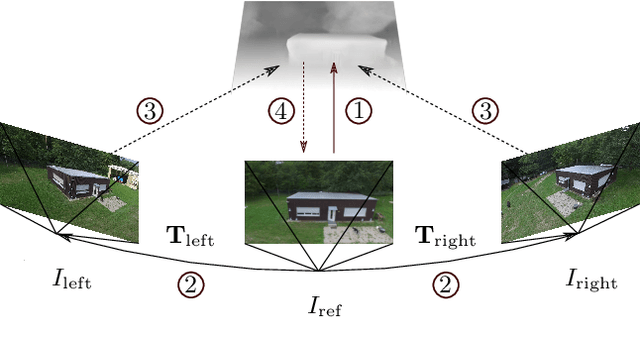

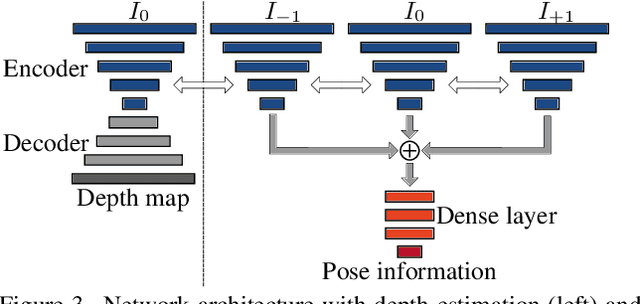
Supervised learning based methods for monocular depth estimation usually require large amounts of extensively annotated training data. In the case of aerial imagery, this ground truth is particularly difficult to acquire. Therefore, in this paper, we present a method for self-supervised learning for monocular depth estimation from aerial imagery that does not require annotated training data. For this, we only use an image sequence from a single moving camera and learn to simultaneously estimate depth and pose information. By sharing the weights between pose and depth estimation, we achieve a relatively small model, which favors real-time application. We evaluate our approach on three diverse datasets and compare the results to conventional methods that estimate depth maps based on multi-view geometry. We achieve an accuracy {\delta}1.25 of up to 93.5 %. In addition, we have paid particular attention to the generalization of a trained model to unknown data and the self-improving capabilities of our approach. We conclude that, even though the results of monocular depth estimation are inferior to those achieved by conventional methods, they are well suited to provide a good initialization for methods that rely on image matching or to provide estimates in regions where image matching fails, e.g. occluded or texture-less regions.
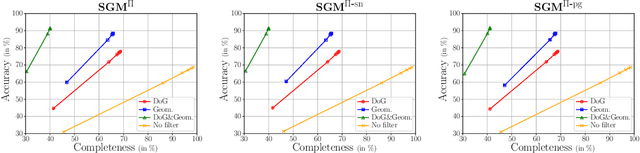
Efficient Surface-Aware Semi-Global Matching with Multi-View Plane-Sweep Sampling
Sep 21, 2019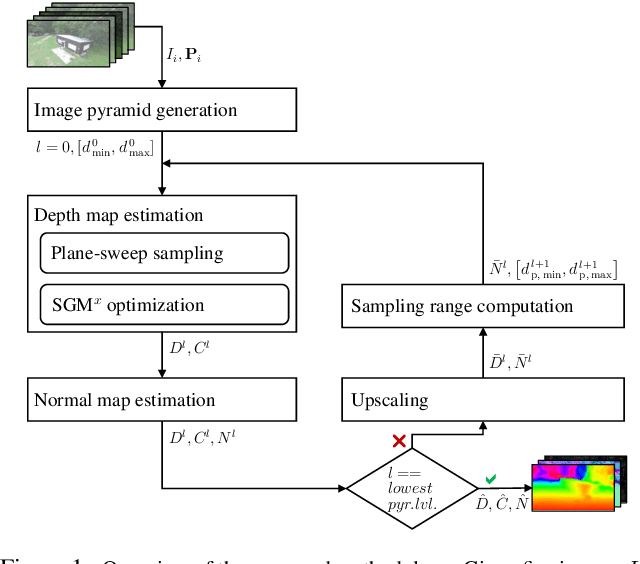
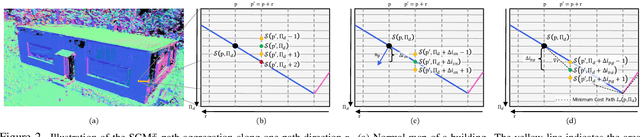
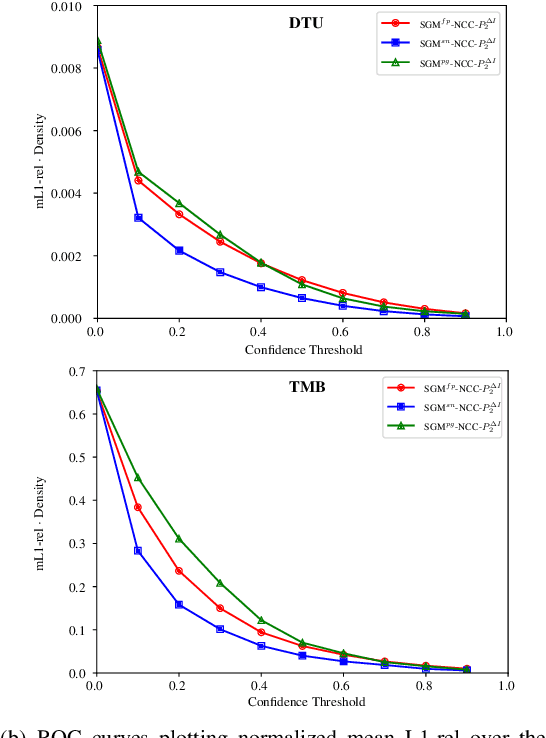
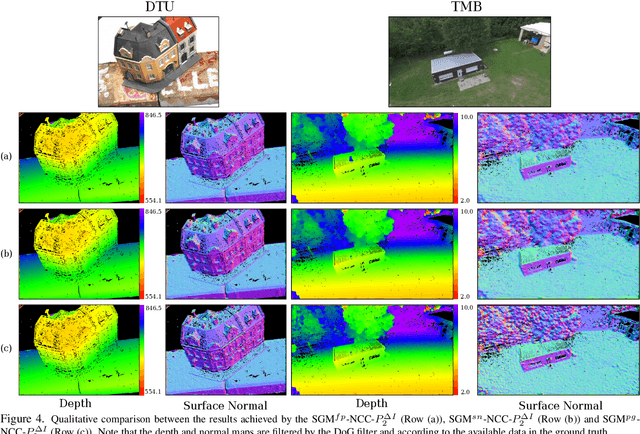
Online augmentation of an oblique aerial image sequence with structural information is an essential aspect in the process of 3D scene interpretation and analysis. One key aspect in this is the efficient dense image matching and depth estimation. Here, the Semi-Global Matching (SGM) approach has proven to be one of the most widely used algorithms for efficient depth estimation, providing a good trade-off between accuracy and computational complexity. However, SGM only models a first-order smoothness assumption, thus favoring fronto-parallel surfaces. In this work, we present a hierarchical algorithm that allows for efficient depth and normal map estimation together with confidence measures for each estimate. Our algorithm relies on a plane-sweep multi-image matching followed by an extended SGM optimization that allows to incorporate local surface orientations, thus achieving more consistent and accurate estimates in areasmade up of slanted surfaces, inherent to oblique aerial imagery. We evaluate numerous configurations of our algorithm on two different datasets using an absolute and relative accuracy measure. In our evaluation, we show that the results of our approach are comparable to the ones achieved by refined Structure-from-Motion (SfM) pipelines, such as COLMAP, which are designed for offline processing. In contrast, however, our approach only considers a confined image bundle of an input sequence, thus allowing to perform an online and incremental computation at 1Hz-2Hz.
Automatic Co-Registration of Aerial Imagery and Untextured Model Data Utilizing Average Shading Gradients
Jun 26, 2019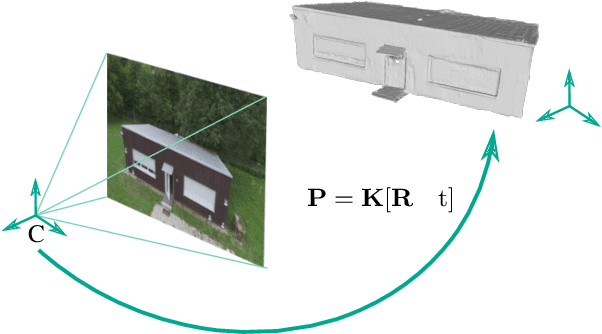
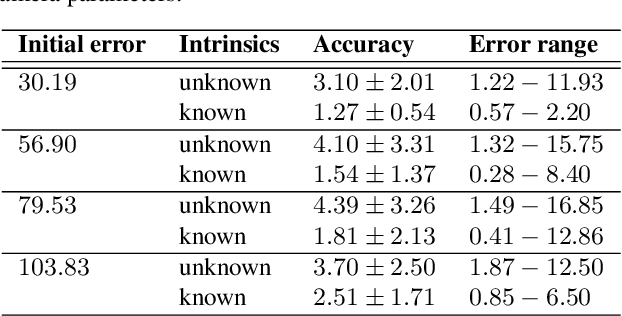
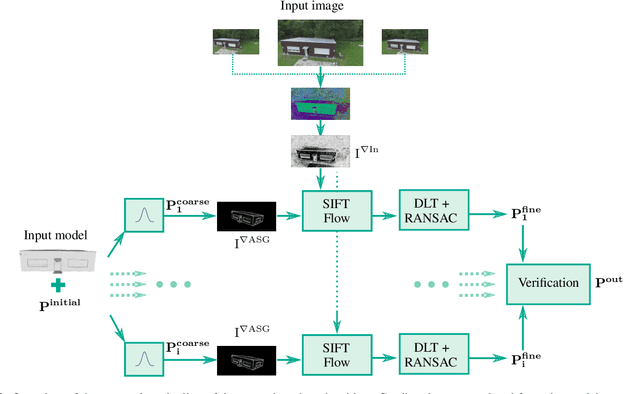

The comparison of current image data with existing 3D model data of a scene provides an efficient method to keep models up to date. In order to transfer information between 2D and 3D data, a preliminary co-registration is necessary. In this paper, we present a concept to automatically co-register aerial imagery and untextured 3D model data. To refine a given initial camera pose, our algorithm computes dense correspondence fields using SIFT flow between gradient representations of the model and camera image, from which 2D-3D correspondences are obtained. These correspondences are then used in an iterative optimization scheme to refine the initial camera pose by minimizing the reprojection error. Since it is assumed that the model does not contain texture information, our algorithm is built up on an existing method based on Average Shading Gradients (ASG) to generate gradient images based on raw geometry information only. We apply our algorithm for the co-registering of aerial photographs to an untextured, noisy mesh model. We have investigated different magnitudes of input error and show that the proposed approach can reduce the final reprojection error to a minimum of 1.27 plus-minus 0.54 pixels, which is less than 10 % of its initial value. Furthermore, our evaluation shows that our approach outperforms the accuracy of a standard Iterative Closest Point (ICP) implementation.
Real-time on-board obstacle avoidance for UAVs based on embedded stereo vision
Jul 17, 2018
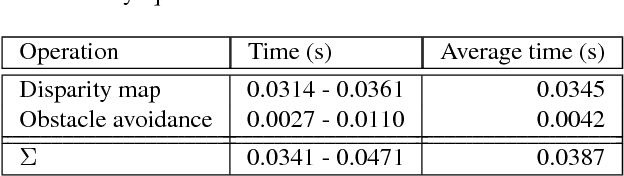
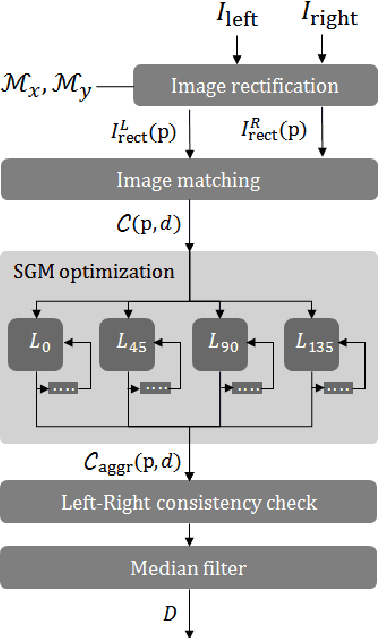
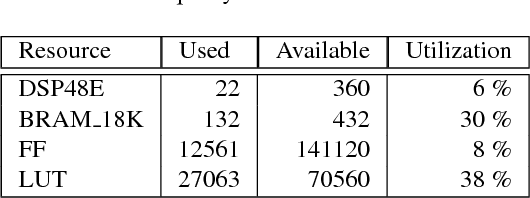
In order to improve usability and safety, modern unmanned aerial vehicles (UAVs) are equipped with sensors to monitor the environment, such as laser-scanners and cameras. One important aspect in this monitoring process is to detect obstacles in the flight path in order to avoid collisions. Since a large number of consumer UAVs suffer from tight weight and power constraints, our work focuses on obstacle avoidance based on a lightweight stereo camera setup. We use disparity maps, which are computed from the camera images, to locate obstacles and to automatically steer the UAV around them. For disparity map computation we optimize the well-known semi-global matching (SGM) approach for the deployment on an embedded FPGA. The disparity maps are then converted into simpler representations, the so called U-/V-Maps, which are used for obstacle detection. Obstacle avoidance is based on a reactive approach which finds the shortest path around the obstacles as soon as they have a critical distance to the UAV. One of the fundamental goals of our work was the reduction of development costs by closing the gap between application development and hardware optimization. Hence, we aimed at using high-level synthesis (HLS) for porting our algorithms, which are written in C/C++, to the embedded FPGA. We evaluated our implementation of the disparity estimation on the KITTI Stereo 2015 benchmark. The integrity of the overall realtime reactive obstacle avoidance algorithm has been evaluated by using Hardware-in-the-Loop testing in conjunction with two flight simulators.
Deep cross-domain building extraction for selective depth estimation from oblique aerial imagery
Jul 17, 2018
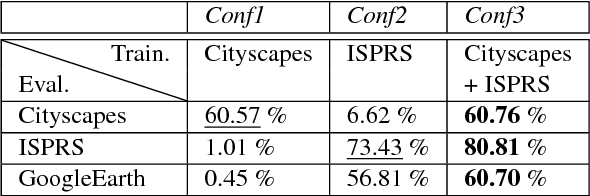
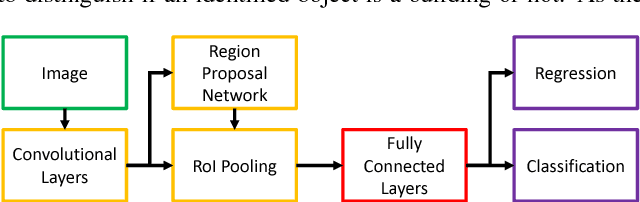

With the technological advancements of aerial imagery and accurate 3d reconstruction of urban environments, more and more attention has been paid to the automated analyses of urban areas. In our work, we examine two important aspects that allow live analysis of building structures in city models given oblique aerial imagery, namely automatic building extraction with convolutional neural networks (CNNs) and selective real-time depth estimation from aerial imagery. We use transfer learning to train the Faster R-CNN method for real-time deep object detection, by combining a large ground-based dataset for urban scene understanding with a smaller number of images from an aerial dataset. We achieve an average precision (AP) of about 80% for the task of building extraction on a selected evaluation dataset. Our evaluation focuses on both dataset-specific learning and transfer learning. Furthermore, we present an algorithm that allows for multi-view depth estimation from aerial imagery in real-time. We adopt the semi-global matching (SGM) optimization strategy to preserve sharp edges at object boundaries. In combination with the Faster R-CNN, it allows a selective reconstruction of buildings, identified with regions of interest (RoIs), from oblique aerial imagery.