 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELMA: SEmantic Large-scale Multimodal Acquisitions in Variable Weather, Daytime and Viewpoints
Paper and Code
Apr 20, 2022
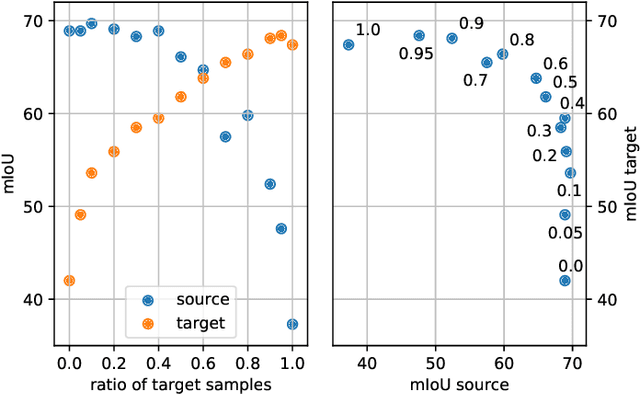
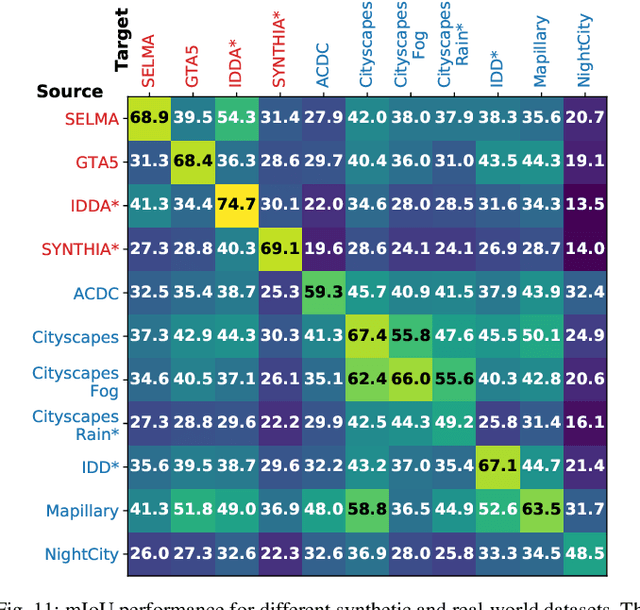

Accurate scene understanding from multiple sensors mounted on cars is a key requirement for autonomous driving systems. Nowadays, this task is mainly performed through data-hungry deep learning techniques that need very large amounts of data to be trained. Due to the high cost of performing segmentation labeling, many synthetic datasets have been proposed. However, most of them miss the multi-sensor nature of the data, and do not capture the significant changes introduced by the variation of daytime and weather conditions. To fill these gaps, we introduce SELMA, a novel synthetic dataset for semantic segmentation that contains more than 30K unique waypoints acquired from 24 different sensors including RGB, depth, semantic cameras and LiDARs, in 27 different atmospheric and daytime conditions, for a total of more than 20M samples. SELMA is based on CARLA, an open-source simulator for generating synthetic data in autonomous driving scenarios, that we modified to increase the variability and the diversity in the scenes and class sets, and to align it with other benchmark datasets. As shown by the experimental evaluation, SELMA allows the efficient training of standard and multi-modal deep learning architectures, and achieves remarkable results on real-world data. SELMA is free and publicly available, thus supporting open science and research.