 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEkka: Automated Diagnosis of Silent Errors in LLM Inference
Jun 03, 2026LLM serving frameworks are quickly evolving with a complex software stack and a vast number of optimizations. The rapid development process can introduce silent errors where output quality silently degrades without any explicit error signals. Diagnosing silent errors is notoriously difficult due to the substantial semantic gap between the high-level symptoms and the low-level root causes. We observe that diagnosis of silent errors can be effectively framed as a differential debugging problem by leveraging the existence of semantically correct reference implementations. We propose Ekka, an automated diagnosis system that identifies root causes by systematically aligning and comparing intermediate execution states between a target and a reference framework. We constructed a benchmark of real-world silent errors from popular serving frameworks, where Ekka shows 80% pass@1 diagnosis accuracy and 88% pass@5 diagnosis accuracy, outperforming state-of-the-art systems. Ekka also diagnoses 4 new silent errors from serving frameworks, all of which have been confirmed by the developers.
TTrace: Lightweight Error Checking and Diagnosis for Distributed Training
Jun 10, 2025Distributed training is essential for scaling the training of large neural network models, such as large language models (LLMs), across thousands of GPUs. However, the complexity of distributed training programs makes them particularly prone to silent bugs, which do not produce explicit error signal but lead to incorrect training outcome. Effectively detecting and localizing such silent bugs in distributed training is challenging. Common debugging practice using metrics like training loss or gradient norm curves can be inefficient and ineffective. Additionally, obtaining intermediate tensor values and determining whether they are correct during silent bug localization is difficult, particularly in the context of low-precision training. To address those challenges, we design and implement TTrace, the first system capable of detecting and localizing silent bugs in distributed training. TTrace collects intermediate tensors from distributing training in a fine-grained manner and compares them against those from a trusted single-device reference implementation. To properly compare the floating-point values in the tensors, we propose novel mathematical analysis that provides a guideline for setting thresholds, enabling TTrace to distinguish bug-induced errors from floating-point round-off errors. Experimental results demonstrate that TTrace effectively detects 11 existing bugs and 3 new bugs in the widely used Megatron-LM framework, while requiring fewer than 10 lines of code change. TTrace is effective in various training recipes, including low-precision recipes involving BF16 and FP8.
HLAT: High-quality Large Language Model Pre-trained on AWS Trainium
Apr 16, 2024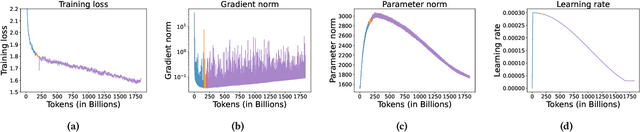
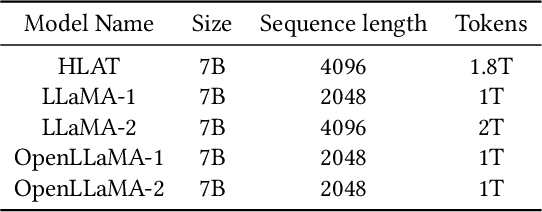
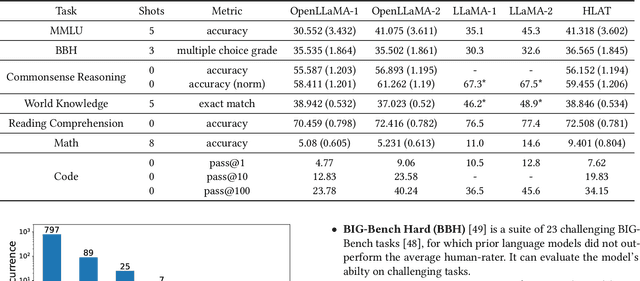
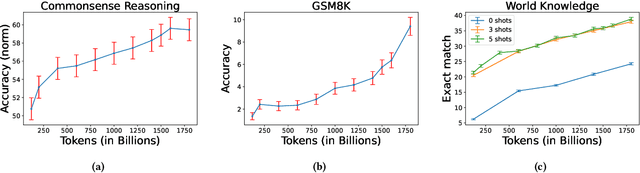
Getting large language models (LLMs) to perform well on the downstream tasks requires pre-training over trillions of tokens. This typically demands a large number of powerful computational devices in addition to a stable distributed training framework to accelerate the training. The growing number of applications leveraging AI/ML had led to a scarcity of the expensive conventional accelerators (such as GPUs), which begs the need for the alternative specialized-accelerators that are scalable and cost-efficient. AWS Trainium is the second-generation machine learning accelerator that has been purposely built for training large deep learning models. Its corresponding instance, Amazon EC2 trn1, is an alternative to GPU instances for LLM training. However, training LLMs with billions of parameters on trn1 is challenging due to its relatively nascent software ecosystem. In this paper, we showcase HLAT: a 7 billion parameter decoder-only LLM pre-trained using trn1 instances over 1.8 trillion tokens. The performance of HLAT is benchmarked against popular open source baseline models including LLaMA and OpenLLaMA, which have been trained on NVIDIA GPUs and Google TPUs, respectively. On various evaluation tasks, we show that HLAT achieves model quality on par with the baselines. We also share the best practice of using the Neuron Distributed Training Library (NDTL), a customized distributed training library for AWS Trainium to achieve efficient training. Our work demonstrates that AWS Trainium powered by the NDTL is able to successfully pre-train state-of-the-art LLM models with high performance and cost-effectiveness.
MV-CLIP: Multi-View CLIP for Zero-shot 3D Shape Recognition
Nov 30, 2023



Large-scale pre-trained models have demonstrated impressive performance in vision and language tasks within open-world scenarios. Due to the lack of comparable pre-trained models for 3D shapes, recent methods utilize language-image pre-training to realize zero-shot 3D shape recognition. However, due to the modality gap, pretrained language-image models are not confident enough in the generalization to 3D shape recognition. Consequently, this paper aims to improve the confidence with view selection and hierarchical prompts. Leveraging the CLIP model as an example, we employ view selection on the vision side by identifying views with high prediction confidence from multiple rendered views of a 3D shape. On the textual side, the strategy of hierarchical prompts is proposed for the first time. The first layer prompts several classification candidates with traditional class-level descriptions, while the second layer refines the prediction based on function-level descriptions or further distinctions between the candidates. Remarkably, without the need for additional training, our proposed method achieves impressive zero-shot 3D classification accuracies of 84.44\%, 91.51\%, and 66.17\% on ModelNet40, ModelNet10, and ShapeNet Core55, respectively. Furthermore, we will make the code publicly available to facilitate reproducibility and further research in this area.