 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion-Eval: Integrating Evaluators with LLMs
Paper and Code

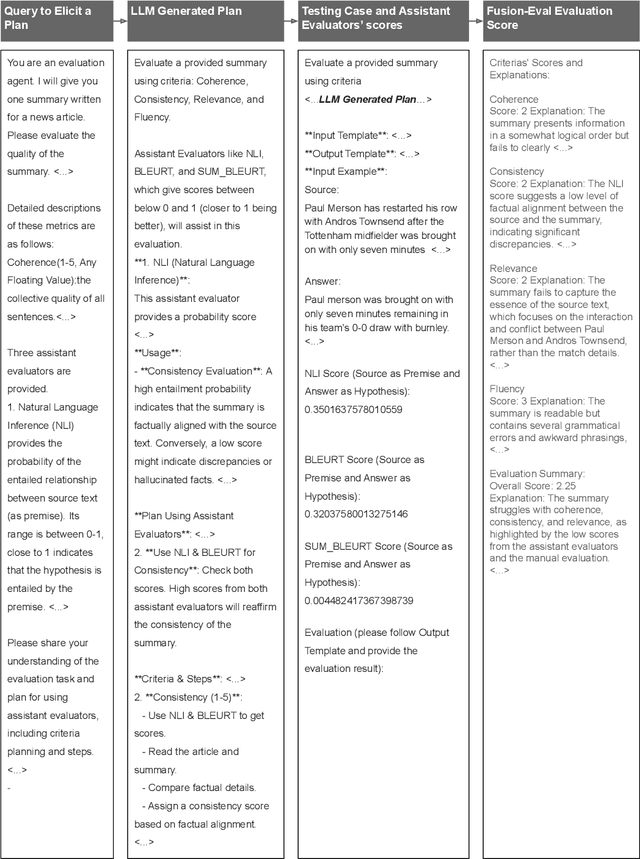
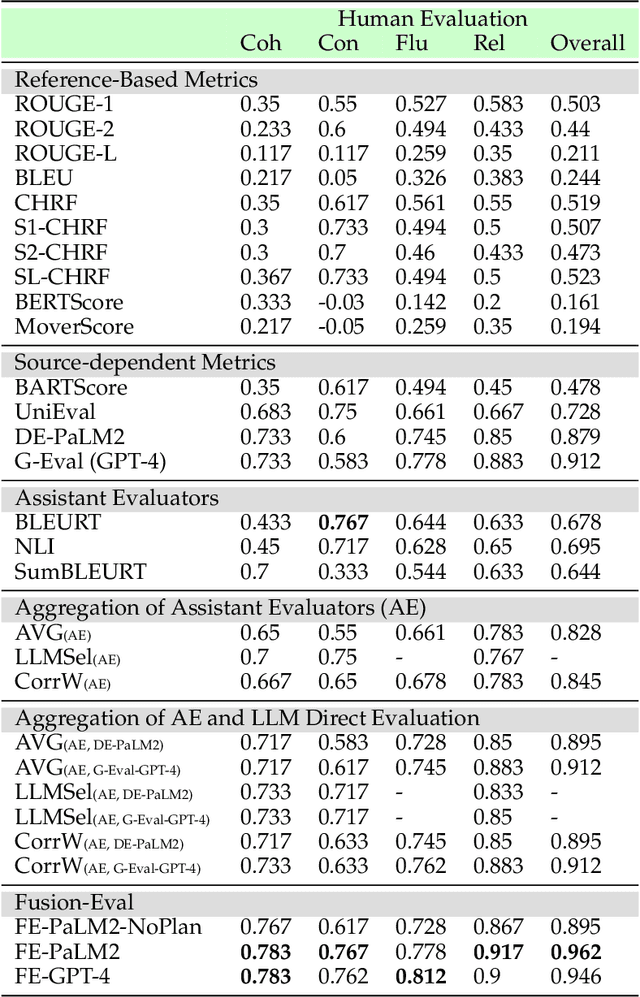
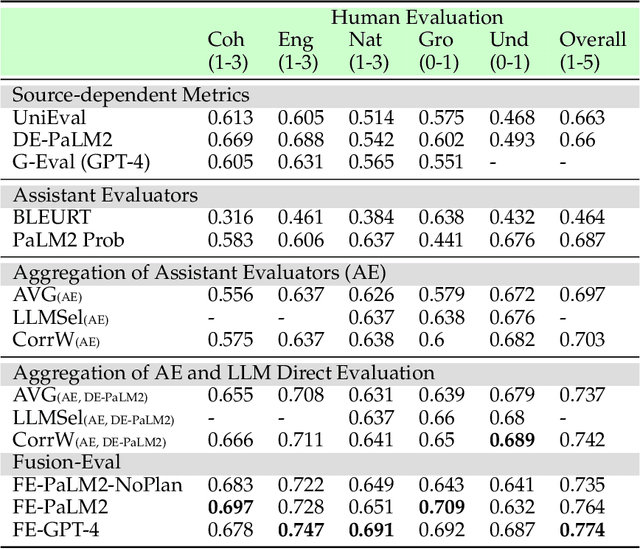
Evaluating Large Language Models (LLMs) is a complex task, especially considering the intricacies of natural language understanding and the expectations for high-level reasoning. Traditional evaluations typically lean on human-based, model-based, or automatic-metrics-based paradigms, each with its own advantages and shortcomings. We introduce "Fusion-Eval", a system that employs LLMs not solely for direct evaluations, but to skillfully integrate insights from diverse evaluators. This gives Fusion-Eval flexibility, enabling it to work effectively across diverse tasks and make optimal use of multiple references. In testing on the SummEval dataset, Fusion-Eval achieved a Spearman correlation of 0.96, outperforming other evaluators. The success of Fusion-Eval underscores the potential of LLMs to produce evaluations that closely align human perspectives, setting a new standard in the field of LLM evaluation.