 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferability Metrics for Selecting Source Model Ensembles
Paper and Code
Nov 25, 2021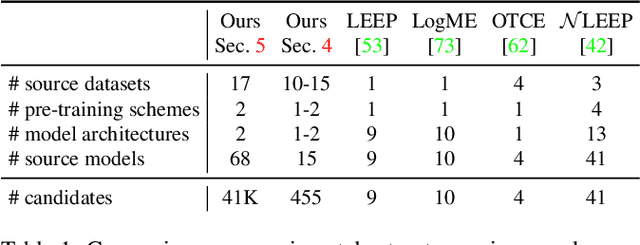
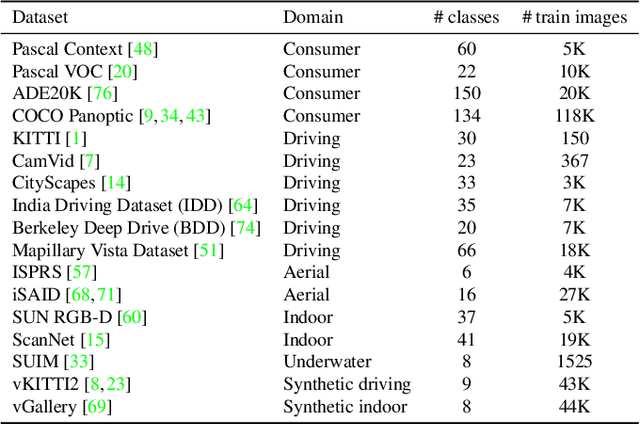
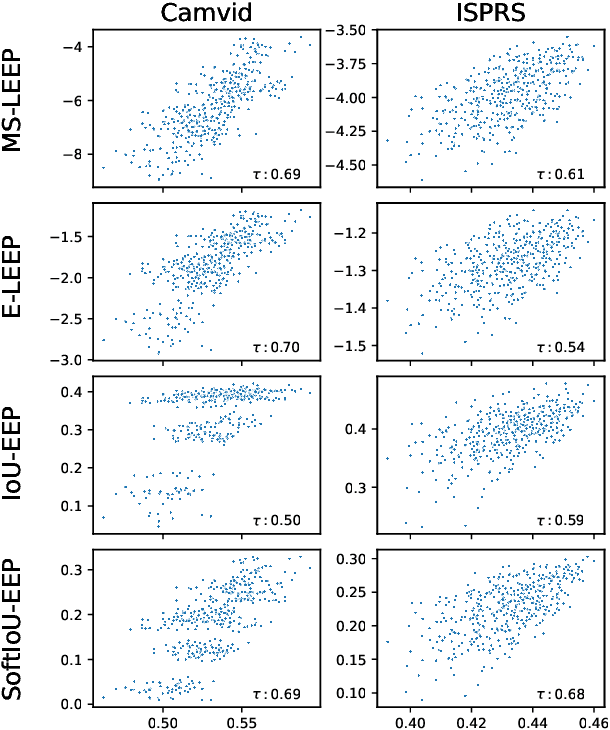

We address the problem of ensemble selection in transfer learning: Given a large pool of source models we want to select an ensemble of models which, after fine-tuning on the target training set, yields the best performance on the target test set. Since fine-tuning all possible ensembles is computationally prohibitive, we aim at predicting performance on the target dataset using a computationally efficient transferability metric. We propose several new transferability metrics designed for this task and evaluate them in a challenging and realistic transfer learning setup for semantic segmentation: we create a large and diverse pool of source models by considering 17 source datasets covering a wide variety of image domain, two different architectures, and two pre-training schemes. Given this pool, we then automatically select a subset to form an ensemble performing well on a given target dataset. We compare the ensemble selected by our method to two baselines which select a single source model, either (1) from the same pool as our method; or (2) from a pool containing large source models, each with similar capacity as an ensemble. Averaged over 17 target datasets, we outperform these baselines by 6.0% and 2.5% relative mean IoU, respectively.