 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Missing Link: Finding label relations across datasets
Paper and Code


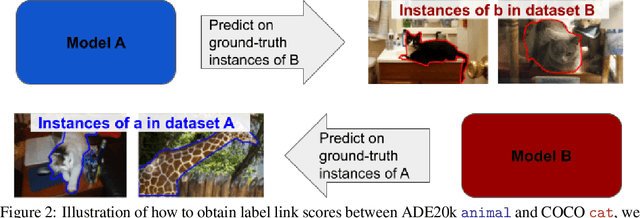

Computer Vision is driven by the many datasets which can be used for training or evaluating novel methods. However, each dataset has different set of class labels, visual definition of classes, images following a specific distribution, annotation protocols, etc. In this paper we explore the automatic discovery of visual-semantic relations between labels across datasets. We want to understand how the instances of a certain class in a dataset relate to the instances of another class in another dataset. Are they in an identity, parent/child, overlap relation? Or is there no link between them at all? To find relations between labels across datasets, we propose methods based on language, on vision, and on a combination of both. Our methods can effectively discover label relations across datasets and the type of the relations. We use these results for a deeper inspection on why instances relate, find missing aspects of a class, and use our relations to create finer-grained annotations. We conclude that label relations cannot be established by looking at the names of classes alone, as they depend strongly on how each of the datasets was constructed.