 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Object Annotation via Speaking and Pointing
Paper and Code
May 25, 2019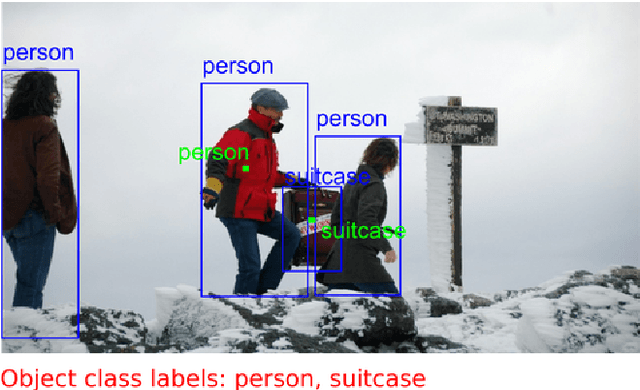



Deep neural networks deliver state-of-the-art visual recognition, but they rely on large datasets, which are time-consuming to annotate. These datasets are typically annotated in two stages: (1) determining the presence of object classes at the image level and (2) marking the spatial extent for all objects of these classes. In this work we use speech, together with mouse inputs, to speed up this process. We first improve stage one, by letting annotators indicate object class presence via speech. We then combine the two stages: annotators draw an object bounding box via the mouse and simultaneously provide its class label via speech. Using speech has distinct advantages over relying on mouse inputs alone. First, it is fast and allows for direct access to the class name, by simply saying it. Second, annotators can simultaneously speak and mark an object location. Finally, speech-based interfaces can be kept extremely simple, hence using them requires less mouse movement compared to existing approaches. Through extensive experiments on the COCO and ILSVRC datasets we show that our approach yields high-quality annotations at significant speed gains. Stage one takes 2.3x - 14.9x less annotation time than existing methods based on a hierarchical organization of the classes to be annotated. Moreover, when combining the two stages, we find that object class labels come for free: annotating them at the same time as bounding boxes has zero additional cost. On COCO, this makes the overall process 1.9x faster than the two-stage approach.