 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiCLIP: Multi-Attribute Face Manipulation from Text
Oct 02, 2022


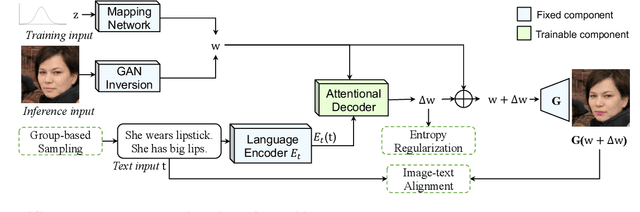
In this paper we present a novel multi-attribute face manipulation method based on textual descriptions. Previous text-based image editing methods either require test-time optimization for each individual image or are restricted to single attribute editing. Extending these methods to multi-attribute face image editing scenarios will introduce undesired excessive attribute change, e.g., text-relevant attributes are overly manipulated and text-irrelevant attributes are also changed. In order to address these challenges and achieve natural editing over multiple face attributes, we propose a new decoupling training scheme where we use group sampling to get text segments from same attribute categories, instead of whole complex sentences. Further, to preserve other existing face attributes, we encourage the model to edit the latent code of each attribute separately via a entropy constraint. During the inference phase, our model is able to edit new face images without any test-time optimization, even from complex textual prompts. We show extensive experiments and analysis to demonstrate the efficacy of our method, which generates natural manipulated faces with minimal text-irrelevant attribute editing. Code and pre-trained model will be released.
PHD-GIFs: Personalized Highlight Detection for Automatic GIF Creation
Aug 07, 2018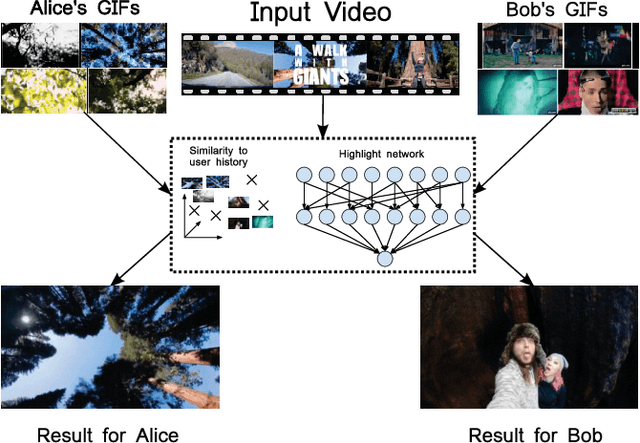
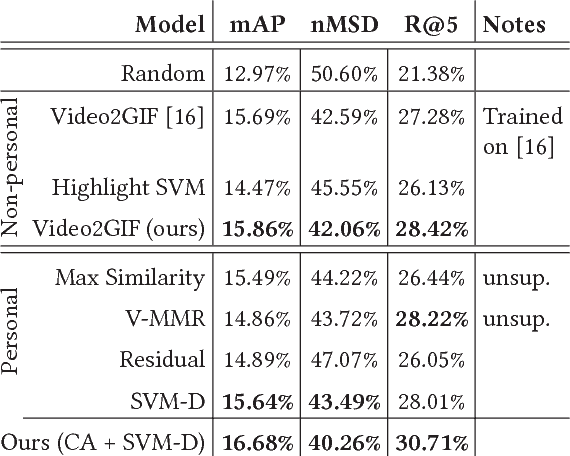

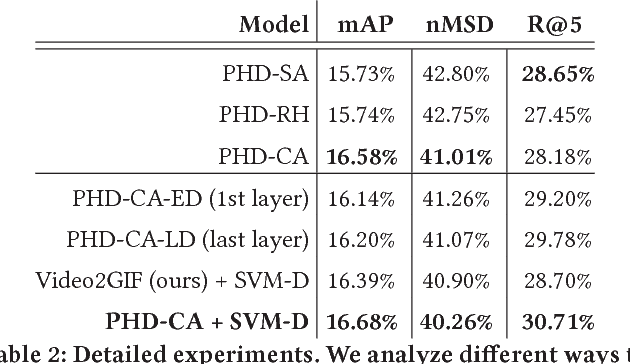
Highlight detection models are typically trained to identify cues that make visual content appealing or interesting for the general public, with the objective of reducing a video to such moments. However, the "interestingness" of a video segment or image is subjective. Thus, such highlight models provide results of limited relevance for the individual user. On the other hand, training one model per user is inefficient and requires large amounts of personal information which is typically not available. To overcome these limitations, we present a global ranking model which conditions on each particular user's interests. Rather than training one model per user, our model is personalized via its inputs, which allows it to effectively adapt its predictions, given only a few user-specific examples. To train this model, we create a large-scale dataset of users and the GIFs they created, giving us an accurate indication of their interests. Our experiments show that using the user history substantially improves the prediction accuracy. On our test set of 850 videos, our model improves the recall by 8% with respect to generic highlight detectors. Furthermore, our method proves more precise than the user-agnostic baselines even with just one person-specific example.