 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Model Compression for Federated Learning with Large Models
Paper and Code
May 06, 2022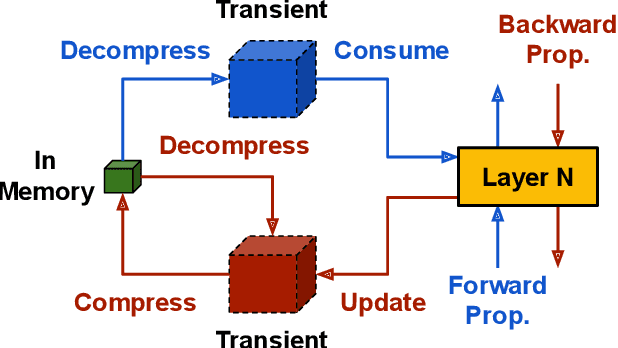
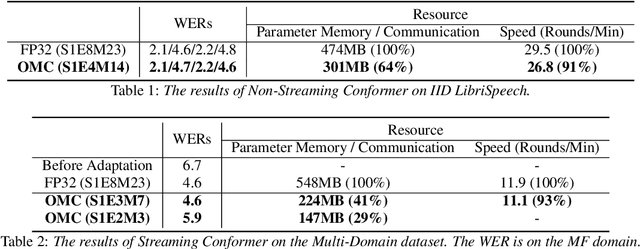
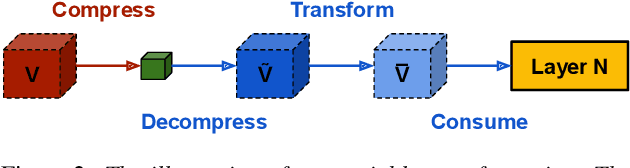
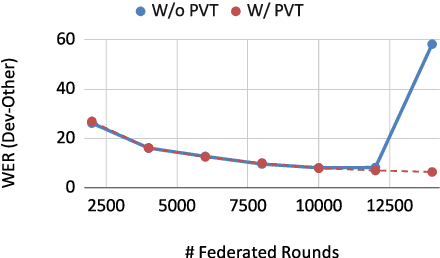
This paper addresses the challenges of training large neural network models under federated learning settings: high on-device memory usage and communication cost. The proposed Online Model Compression (OMC) provides a framework that stores model parameters in a compressed format and decompresses them only when needed. We use quantization as the compression method in this paper and propose three methods, (1) using per-variable transformation, (2) weight matrices only quantization, and (3) partial parameter quantization, to minimize the impact on model accuracy. According to our experiments on two recent neural networks for speech recognition and two different datasets, OMC can reduce memory usage and communication cost of model parameters by up to 59% while attaining comparable accuracy and training speed when compared with full-precision training.