 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Over-Parameterized Training
Paper and Code
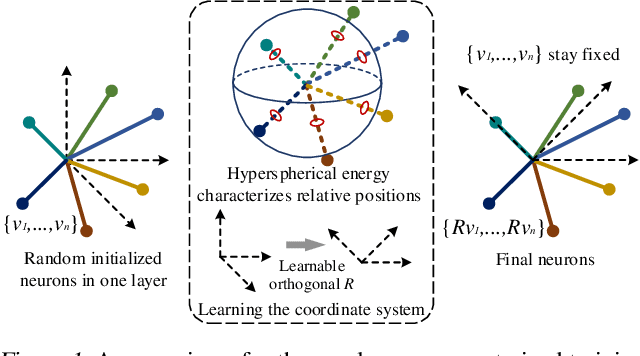

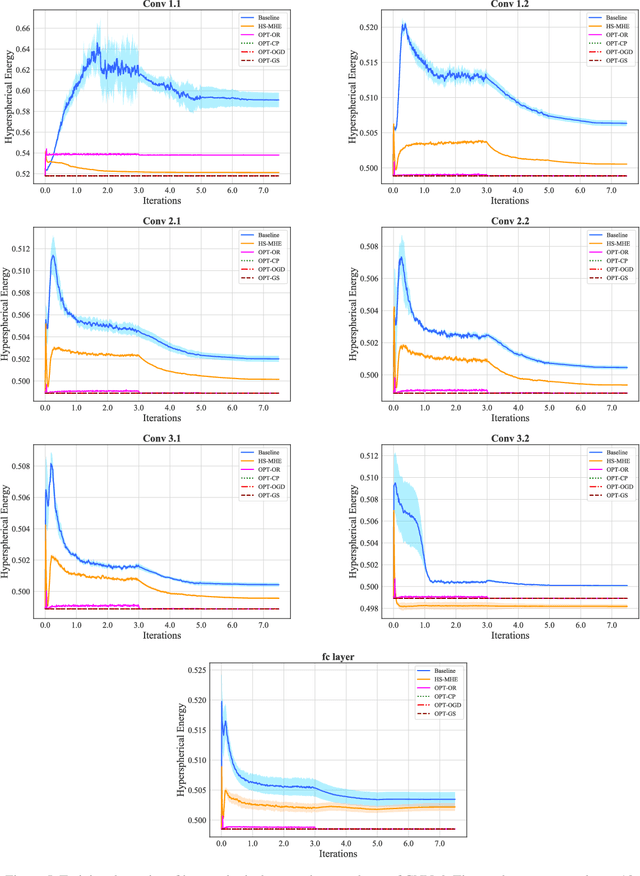
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is even more important than designing the architecture. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. By constantly maintaining the minimum hyperspherical energy during training, OPT can greatly improve the network generalization. Specifically, OPT fixes the randomly initialized weights of the neurons and learns an orthogonal transformation that applies to these neurons. We propose multiple ways to learn such an orthogonal transformation, including unrolling orthogonalization algorithms, applying orthogonal parameterization, and designing orthogonality-preserving gradient update. Interestingly, OPT reveals that learning a proper coordinate system for neurons is crucial to generalization and may be more important than learning a specific relative position of neurons. We further provide theoretical insights of why OPT yields better generalization. Extensive experiments validate the superiority of OPT.