 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Interactive Learning on the Job via Facility Location Planning
May 01, 2025Collaborative robots must continually adapt to novel tasks and user preferences without overburdening the user. While prior interactive robot learning methods aim to reduce human effort, they are typically limited to single-task scenarios and are not well-suited for sustained, multi-task collaboration. We propose COIL (Cost-Optimal Interactive Learning) -- a multi-task interaction planner that minimizes human effort across a sequence of tasks by strategically selecting among three query types (skill, preference, and help). When user preferences are known, we formulate COIL as an uncapacitated facility location (UFL) problem, which enables bounded-suboptimal planning in polynomial time using off-the-shelf approximation algorithms. We extend our formulation to handle uncertainty in user preferences by incorporating one-step belief space planning, which uses these approximation algorithms as subroutines to maintain polynomial-time performance. Simulated and physical experiments on manipulation tasks show that our framework significantly reduces the amount of work allocated to the human while maintaining successful task completion.
RecoveryChaining: Learning Local Recovery Policies for Robust Manipulation
Oct 17, 2024



Model-based planners and controllers are commonly used to solve complex manipulation problems as they can efficiently optimize diverse objectives and generalize to long horizon tasks. However, they are limited by the fidelity of their model which oftentimes leads to failures during deployment. To enable a robot to recover from such failures, we propose to use hierarchical reinforcement learning to learn a separate recovery policy. The recovery policy is triggered when a failure is detected based on sensory observations and seeks to take the robot to a state from which it can complete the task using the nominal model-based controllers. Our approach, called RecoveryChaining, uses a hybrid action space, where the model-based controllers are provided as additional \emph{nominal} options which allows the recovery policy to decide how to recover, when to switch to a nominal controller and which controller to switch to even with \emph{sparse rewards}. We evaluate our approach in three multi-step manipulation tasks with sparse rewards, where it learns significantly more robust recovery policies than those learned by baselines. Finally, we successfully transfer recovery policies learned in simulation to a physical robot to demonstrate the feasibility of sim-to-real transfer with our method.
Multi-Robot Motion Planning with Diffusion Models
Oct 04, 2024



Diffusion models have recently been successfully applied to a wide range of robotics applications for learning complex multi-modal behaviors from data. However, prior works have mostly been confined to single-robot and small-scale environments due to the high sample complexity of learning multi-robot diffusion models. In this paper, we propose a method for generating collision-free multi-robot trajectories that conform to underlying data distributions while using only single-robot data. Our algorithm, Multi-robot Multi-model planning Diffusion (MMD), does so by combining learned diffusion models with classical search-based techniques -- generating data-driven motions under collision constraints. Scaling further, we show how to compose multiple diffusion models to plan in large environments where a single diffusion model fails to generalize well. We demonstrate the effectiveness of our approach in planning for dozens of robots in a variety of simulated scenarios motivated by logistics environments. View video demonstrations in our supplementary material, and our code at: https://github.com/yoraish/mmd.
Efficiently Learning Recoveries from Failures Under Partial Observability
Sep 27, 2022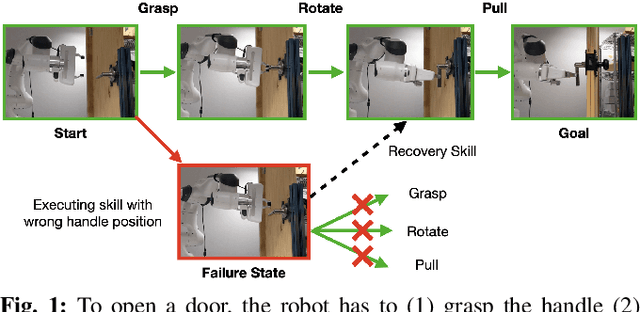
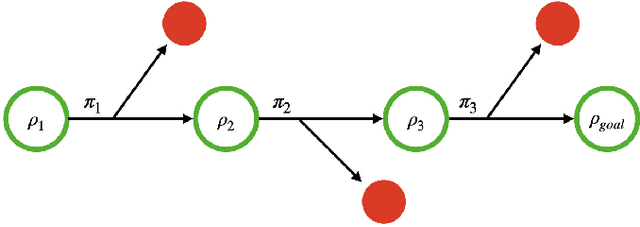
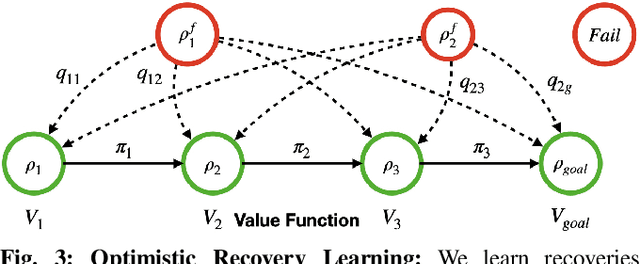

Operating under real world conditions is challenging due to the possibility of a wide range of failures induced by partial observability. In relatively benign settings, such failures can be overcome by retrying or executing one of a small number of hand-engineered recovery strategies. By contrast, contact-rich sequential manipulation tasks, like opening doors and assembling furniture, are not amenable to exhaustive hand-engineering. To address this issue, we present a general approach for robustifying manipulation strategies in a sample-efficient manner. Our approach incrementally improves robustness by first discovering the failure modes of the current strategy via exploration in simulation and then learning additional recovery skills to handle these failures. To ensure efficient learning, we propose an online algorithm Value Upper Confidence Limit (Value-UCL) that selects what failure modes to prioritize and which state to recover to such that the expected performance improves maximally in every training episode. We use our approach to learn recovery skills for door-opening and evaluate them both in simulation and on a real robot with little fine-tuning. Compared to open-loop execution, our experiments show that even a limited amount of recovery learning improves task success substantially from 71\% to 92.4\% in simulation and from 75\% to 90\% on a real robot.
Synergistic Scheduling of Learning and Allocation of Tasks in Human-Robot Teams
Mar 14, 2022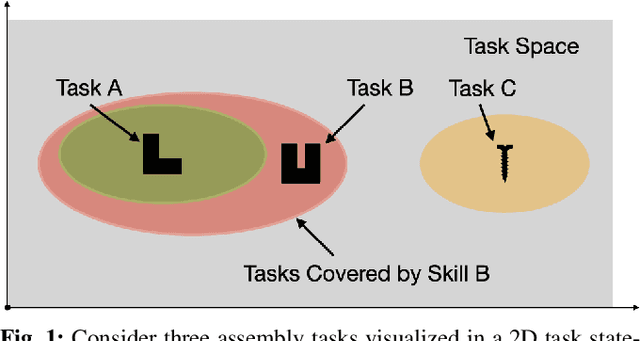
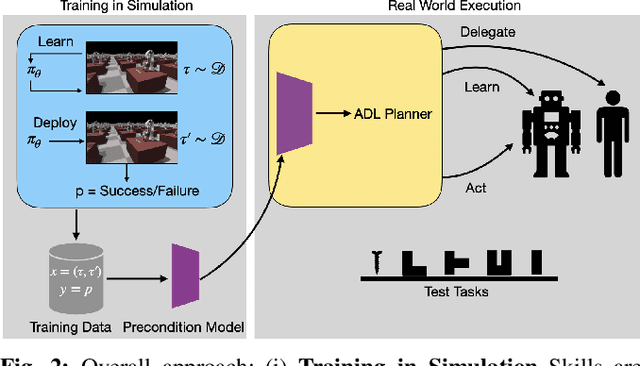
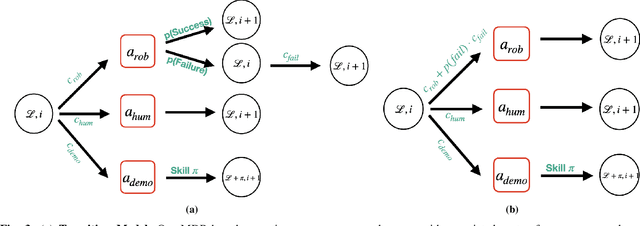
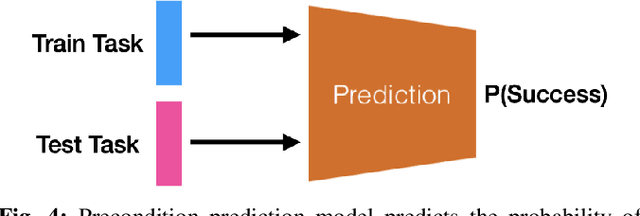
We consider the problem of completing a set of $n$ tasks with a human-robot team using minimum effort. In many domains, teaching a robot to be fully autonomous can be counterproductive if there are finitely many tasks to be done. Rather, the optimal strategy is to weigh the cost of teaching a robot and its benefit -- how many new tasks it allows the robot to solve autonomously. We formulate this as a planning problem where the goal is to decide what tasks the robot should do autonomously (act), what tasks should be delegated to a human (delegate) and what tasks the robot should be taught (learn) so as to complete all the given tasks with minimum effort. This planning problem results in a search tree that grows exponentially with $n$ -- making standard graph search algorithms intractable. We address this by converting the problem into a mixed integer program that can be solved efficiently using off-the-shelf solvers with bounds on solution quality. To predict the benefit of learning, we use an approximate simulation model of the tasks to train a precondition model that is parameterized by the training task. Finally, we evaluate our approach on peg insertion and Lego stacking tasks -- both in simulation and real-world, showing substantial savings in human effort.
Search-Based Task Planning with Learned Skill Effect Models for Lifelong Robotic Manipulation
Sep 17, 2021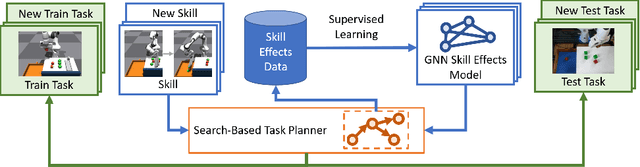

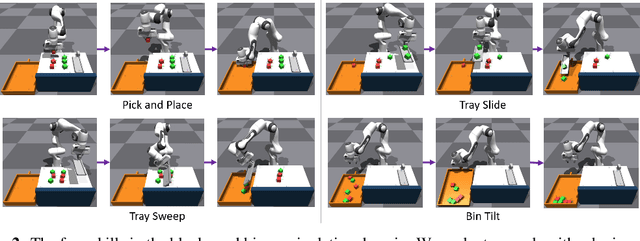
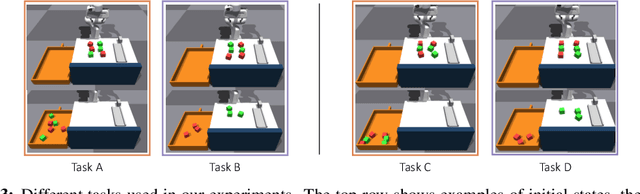
Lifelong-learning robots need to be able to acquire new skills and plan for new tasks over time. Prior works on planning with skills often make assumptions on the structure of skills and tasks, like subgoal skills, shared skill implementations, or learning task-specific plan skeletons, that limit their application to new and different skills and tasks. By contrast, we propose doing task planning by jointly searching in the space of skills and their parameters with skill effect models learned in simulation. Our approach is flexible about skill parameterizations and task specifications, and we use an iterative training procedure to efficiently generate relevant data to train such models. Experiments demonstrate the ability of our planner to integrate new skills in a lifelong manner, finding new task strategies with lower costs in both train and test tasks. We additionally show that our method can transfer to the real world without further fine-tuning.