 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Learning Recoveries from Failures Under Partial Observability
Paper and Code
Sep 27, 2022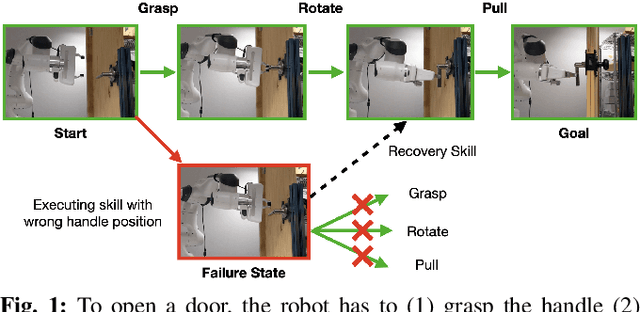
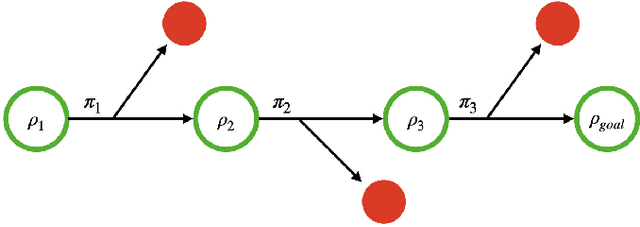
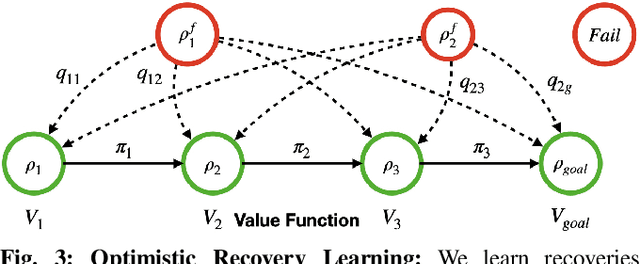

Operating under real world conditions is challenging due to the possibility of a wide range of failures induced by partial observability. In relatively benign settings, such failures can be overcome by retrying or executing one of a small number of hand-engineered recovery strategies. By contrast, contact-rich sequential manipulation tasks, like opening doors and assembling furniture, are not amenable to exhaustive hand-engineering. To address this issue, we present a general approach for robustifying manipulation strategies in a sample-efficient manner. Our approach incrementally improves robustness by first discovering the failure modes of the current strategy via exploration in simulation and then learning additional recovery skills to handle these failures. To ensure efficient learning, we propose an online algorithm Value Upper Confidence Limit (Value-UCL) that selects what failure modes to prioritize and which state to recover to such that the expected performance improves maximally in every training episode. We use our approach to learn recovery skills for door-opening and evaluate them both in simulation and on a real robot with little fine-tuning. Compared to open-loop execution, our experiments show that even a limited amount of recovery learning improves task success substantially from 71\% to 92.4\% in simulation and from 75\% to 90\% on a real robot.