 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning-Query-Guided Model Generation for Model-Based Deformable Object Manipulation
Aug 26, 2025Efficient planning in high-dimensional spaces, such as those involving deformable objects, requires computationally tractable yet sufficiently expressive dynamics models. This paper introduces a method that automatically generates task-specific, spatially adaptive dynamics models by learning which regions of the object require high-resolution modeling to achieve good task performance for a given planning query. Task performance depends on the complex interplay between the dynamics model, world dynamics, control, and task requirements. Our proposed diffusion-based model generator predicts per-region model resolutions based on start and goal pointclouds that define the planning query. To efficiently collect the data for learning this mapping, a two-stage process optimizes resolution using predictive dynamics as a prior before directly optimizing using closed-loop performance. On a tree-manipulation task, our method doubles planning speed with only a small decrease in task performance over using a full-resolution model. This approach informs a path towards using previous planning and control data to generate computationally efficient yet sufficiently expressive dynamics models for new tasks.
Task-Oriented Active Learning of Model Preconditions for Inaccurate Dynamics Models
Jan 08, 2024When planning with an inaccurate dynamics model, a practical strategy is to restrict planning to regions of state-action space where the model is accurate: also known as a model precondition. Empirical real-world trajectory data is valuable for defining data-driven model preconditions regardless of the model form (analytical, simulator, learned, etc...). However, real-world data is often expensive and dangerous to collect. In order to achieve data efficiency, this paper presents an algorithm for actively selecting trajectories to learn a model precondition for an inaccurate pre-specified dynamics model. Our proposed techniques address challenges arising from the sequential nature of trajectories, and potential benefit of prioritizing task-relevant data. The experimental analysis shows how algorithmic properties affect performance in three planning scenarios: icy gridworld, simulated plant watering, and real-world plant watering. Results demonstrate an improvement of approximately 80% after only four real-world trajectories when using our proposed techniques.
Focused Adaptation of Dynamics Models for Deformable Object Manipulation
Sep 28, 2022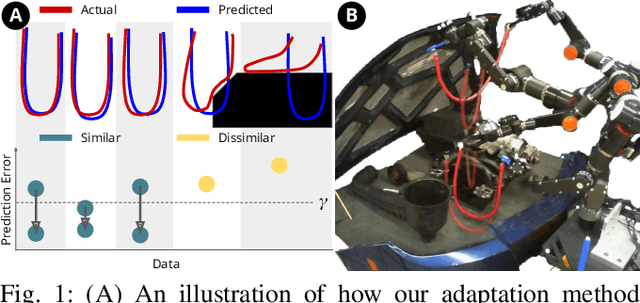
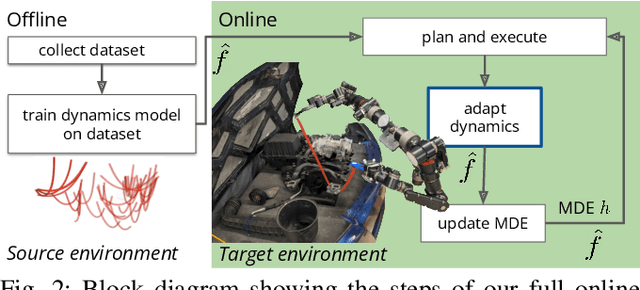
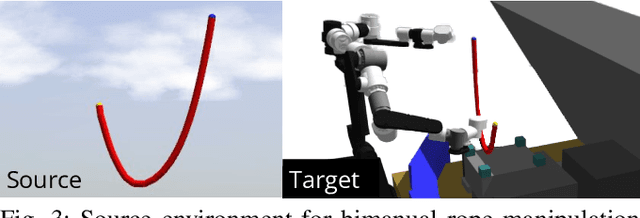
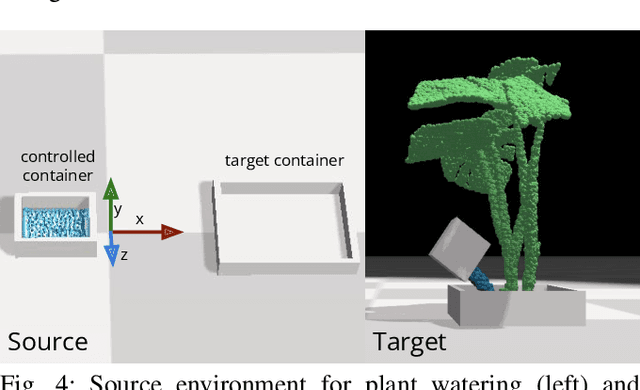
In order to efficiently learn a dynamics model for a task in a new environment, one can adapt a model learned in a similar source environment. However, existing adaptation methods can fail when the target dataset contains transitions where the dynamics are very different from the source environment. For example, the source environment dynamics could be of a rope manipulated in free-space, whereas the target dynamics could involve collisions and deformation on obstacles. Our key insight is to improve data efficiency by focusing model adaptation on only the regions where the source and target dynamics are similar. In the rope example, adapting the free-space dynamics requires significantly fewer data than adapting the free-space dynamics while also learning collision dynamics. We propose a new method for adaptation that is effective in adapting to regions of similar dynamics. Additionally, we combine this adaptation method with prior work on planning with unreliable dynamics to make a method for data-efficient online adaptation, called FOCUS. We first demonstrate that the proposed adaptation method achieves statistically significantly lower prediction error in regions of similar dynamics on simulated rope manipulation and plant watering tasks. We then show on a bimanual rope manipulation task that FOCUS achieves data-efficient online learning, in simulation and in the real world.
Learning Model Preconditions for Planning with Multiple Models
Jun 11, 2022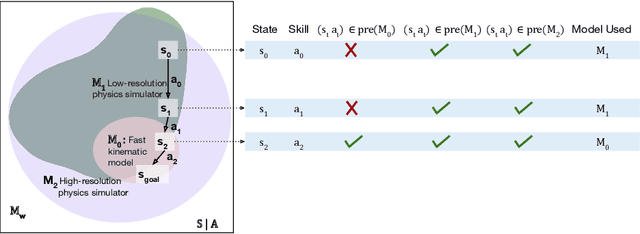
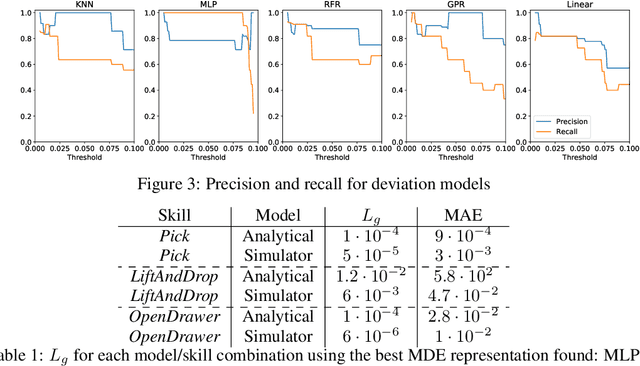
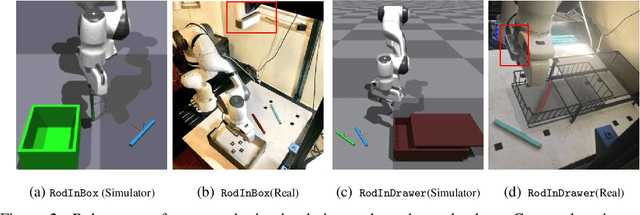

Different models can provide differing levels of fidelity when a robot is planning. Analytical models are often fast to evaluate but only work in limited ranges of conditions. Meanwhile, physics simulators are effective at modeling complex interactions between objects but are typically more computationally expensive. Learning when to switch between the various models can greatly improve the speed of planning and task success reliability. In this work, we learn model deviation estimators (MDEs) to predict the error between real-world states and the states outputted by transition models. MDEs can be used to define a model precondition that describes which transitions are accurately modeled. We then propose a planner that uses the learned model preconditions to switch between various models in order to use models in conditions where they are accurate, prioritizing faster models when possible. We evaluate our method on two real-world tasks: placing a rod into a box and placing a rod into a closed drawer.
* Presented at Conference on Robot Learning (CoRL 2021). Revised for clarity
Specifying and achieving goals in open uncertain robot-manipulation domains
Dec 21, 2021
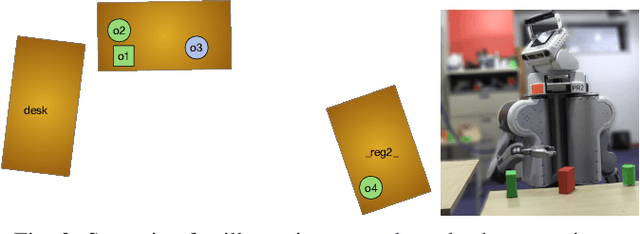
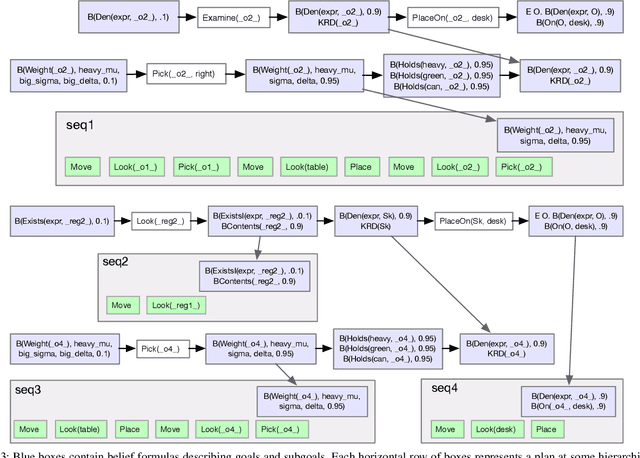

This paper describes an integrated solution to the problem of describing and interpreting goals for robots in open uncertain domains. Given a formal specification of a desired situation, in which objects are described only by their properties, general-purpose planning and reasoning tools are used to derive appropriate actions for a robot. These goals are carried out through an online combination of hierarchical planning, state-estimation, and execution that operates robustly in real robot domains with substantial occlusion and sensing error.
Search-Based Task Planning with Learned Skill Effect Models for Lifelong Robotic Manipulation
Sep 17, 2021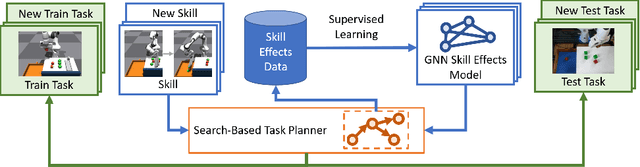

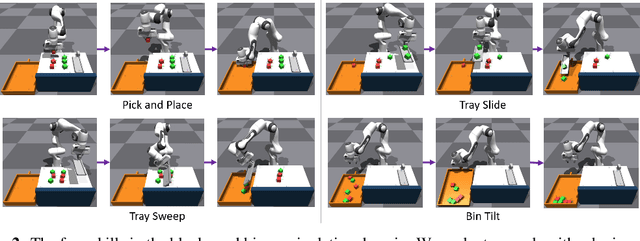
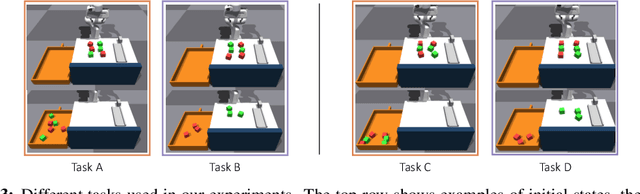
Lifelong-learning robots need to be able to acquire new skills and plan for new tasks over time. Prior works on planning with skills often make assumptions on the structure of skills and tasks, like subgoal skills, shared skill implementations, or learning task-specific plan skeletons, that limit their application to new and different skills and tasks. By contrast, we propose doing task planning by jointly searching in the space of skills and their parameters with skill effect models learned in simulation. Our approach is flexible about skill parameterizations and task specifications, and we use an iterative training procedure to efficiently generate relevant data to train such models. Experiments demonstrate the ability of our planner to integrate new skills in a lifelong manner, finding new task strategies with lower costs in both train and test tasks. We additionally show that our method can transfer to the real world without further fine-tuning.
Learning Reactive and Predictive Differentiable Controllers for Switching Linear Dynamical Models
Mar 26, 2021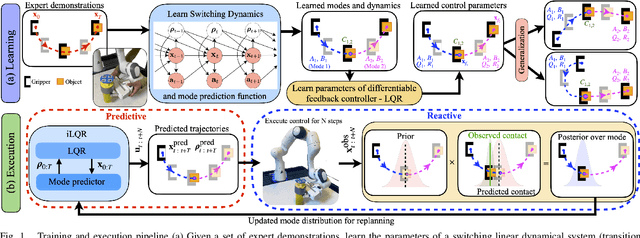
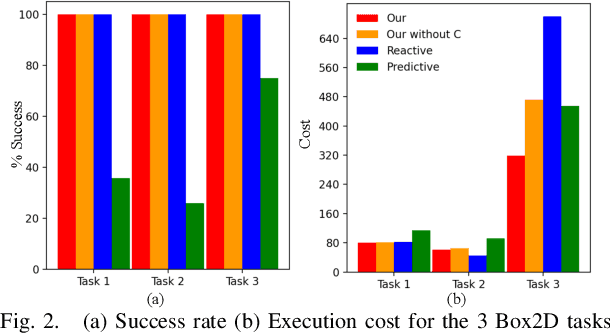


Humans leverage the dynamics of the environment and their own bodies to accomplish challenging tasks such as grasping an object while walking past it or pushing off a wall to turn a corner. Such tasks often involve switching dynamics as the robot makes and breaks contact. Learning these dynamics is a challenging problem and prone to model inaccuracies, especially near contact regions. In this work, we present a framework for learning composite dynamical behaviors from expert demonstrations. We learn a switching linear dynamical model with contacts encoded in switching conditions as a close approximation of our system dynamics. We then use discrete-time LQR as the differentiable policy class for data-efficient learning of control to develop a control strategy that operates over multiple dynamical modes and takes into account discontinuities due to contact. In addition to predicting interactions with the environment, our policy effectively reacts to inaccurate predictions such as unanticipated contacts. Through simulation and real world experiments, we demonstrate generalization of learned behaviors to different scenarios and robustness to model inaccuracies during execution.
Learning to Compose Hierarchical Object-Centric Controllers for Robotic Manipulation
Nov 13, 2020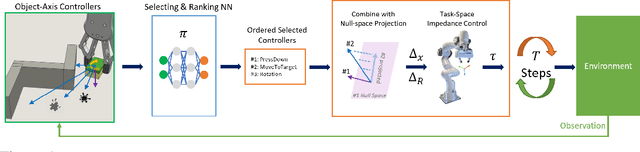
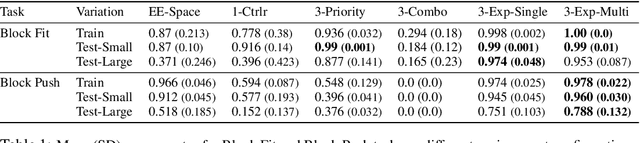
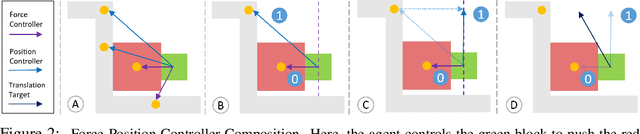
Manipulation tasks can often be decomposed into multiple subtasks performed in parallel, e.g., sliding an object to a goal pose while maintaining contact with a table. Individual subtasks can be achieved by task-axis controllers defined relative to the objects being manipulated, and a set of object-centric controllers can be combined in an hierarchy. In prior works, such combinations are defined manually or learned from demonstrations. By contrast, we propose using reinforcement learning to dynamically compose hierarchical object-centric controllers for manipulation tasks. Experiments in both simulation and real world show how the proposed approach leads to improved sample efficiency, zero-shot generalization to novel test environments, and simulation-to-reality transfer without fine-tuning.
Learning Skills to Patch Plans Based on Inaccurate Models
Sep 29, 2020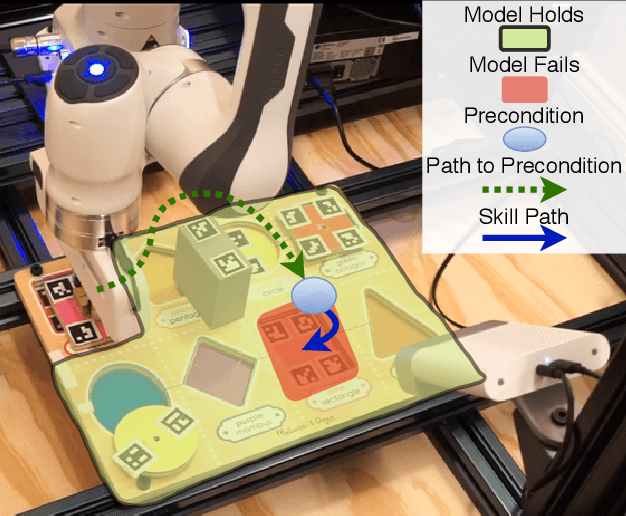
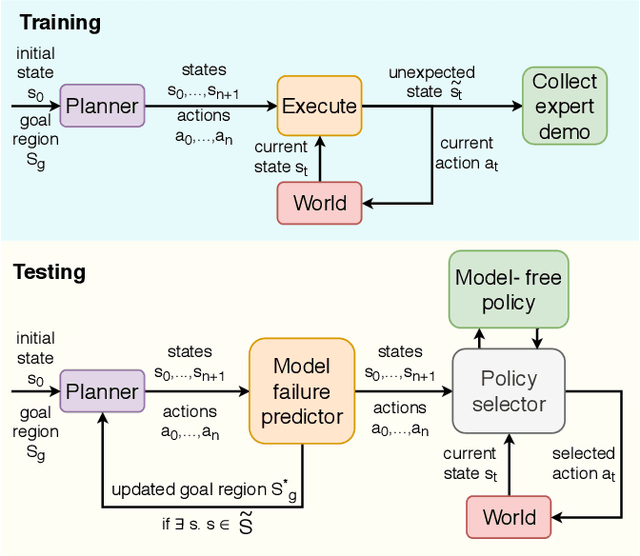

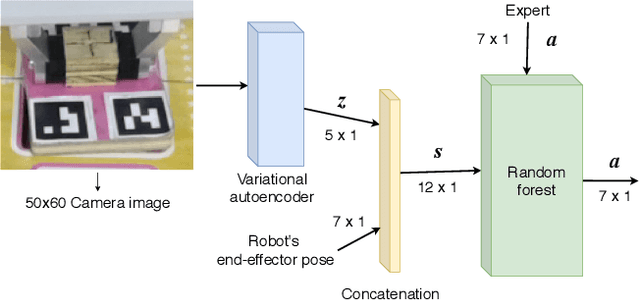
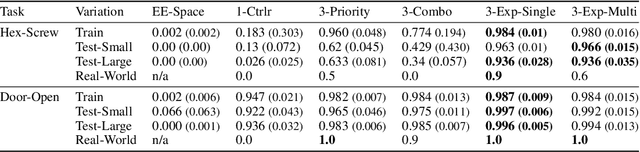
Planners using accurate models can be effective for accomplishing manipulation tasks in the real world, but are typically highly specialized and require significant fine-tuning to be reliable. Meanwhile, learning is useful for adaptation, but can require a substantial amount of data collection. In this paper, we propose a method that improves the efficiency of sub-optimal planners with approximate but simple and fast models by switching to a model-free policy when unexpected transitions are observed. Unlike previous work, our method specifically addresses when the planner fails due to transition model error by patching with a local policy only where needed. First, we use a sub-optimal model-based planner to perform a task until model failure is detected. Next, we learn a local model-free policy from expert demonstrations to complete the task in regions where the model failed. To show the efficacy of our method, we perform experiments with a shape insertion puzzle and compare our results to both pure planning and imitation learning approaches. We then apply our method to a door opening task. Our experiments demonstrate that our patch-enhanced planner performs more reliably than pure planning and with lower overall sample complexity than pure imitation learning.