 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeCaRDv2: A Large-Scale Chinese Legal Case Retrieval Dataset
Oct 26, 2023As an important component of intelligent legal systems, legal case retrieval plays a critical role in ensuring judicial justice and fairness. However, the development of legal case retrieval technologies in the Chinese legal system is restricted by three problems in existing datasets: limited data size, narrow definitions of legal relevance, and naive candidate pooling strategies used in data sampling. To alleviate these issues, we introduce LeCaRDv2, a large-scale Legal Case Retrieval Dataset (version 2). It consists of 800 queries and 55,192 candidates extracted from 4.3 million criminal case documents. To the best of our knowledge, LeCaRDv2 is one of the largest Chinese legal case retrieval datasets, providing extensive coverage of criminal charges. Additionally, we enrich the existing relevance criteria by considering three key aspects: characterization, penalty, procedure. This comprehensive criteria enriches the dataset and may provides a more holistic perspective. Furthermore, we propose a two-level candidate set pooling strategy that effectively identify potential candidates for each query case. It's important to note that all cases in the dataset have been annotated by multiple legal experts specializing in criminal law. Their expertise ensures the accuracy and reliability of the annotations. We evaluate several state-of-the-art retrieval models at LeCaRDv2, demonstrating that there is still significant room for improvement in legal case retrieval. The details of LeCaRDv2 can be found at the anonymous website https://github.com/anonymous1113243/LeCaRDv2.
An Intent Taxonomy of Legal Case Retrieval
Jul 25, 2023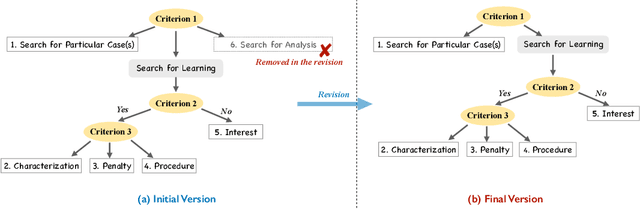
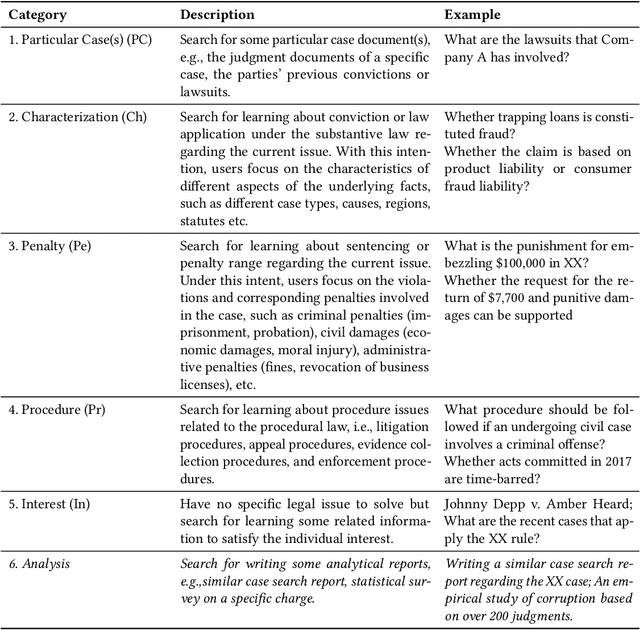


Legal case retrieval is a special Information Retrieval~(IR) task focusing on legal case documents. Depending on the downstream tasks of the retrieved case documents, users' information needs in legal case retrieval could be significantly different from those in Web search and traditional ad-hoc retrieval tasks. While there are several studies that retrieve legal cases based on text similarity, the underlying search intents of legal retrieval users, as shown in this paper, are more complicated than that yet mostly unexplored. To this end, we present a novel hierarchical intent taxonomy of legal case retrieval. It consists of five intent types categorized by three criteria, i.e., search for Particular Case(s), Characterization, Penalty, Procedure, and Interest. The taxonomy was constructed transparently and evaluated extensively through interviews, editorial user studies, and query log analysis. Through a laboratory user study, we reveal significant differences in user behavior and satisfaction under different search intents in legal case retrieval. Furthermore, we apply the proposed taxonomy to various downstream legal retrieval tasks, e.g., result ranking and satisfaction prediction, and demonstrate its effectiveness. Our work provides important insights into the understanding of user intents in legal case retrieval and potentially leads to better retrieval techniques in the legal domain, such as intent-aware ranking strategies and evaluation methodologies.
THUIR@COLIEE-2020: Leveraging Semantic Understanding and Exact Matching for Legal Case Retrieval and Entailment
Dec 24, 2020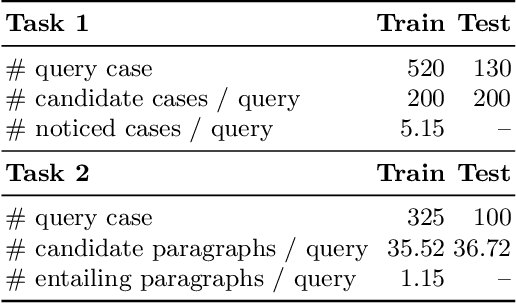
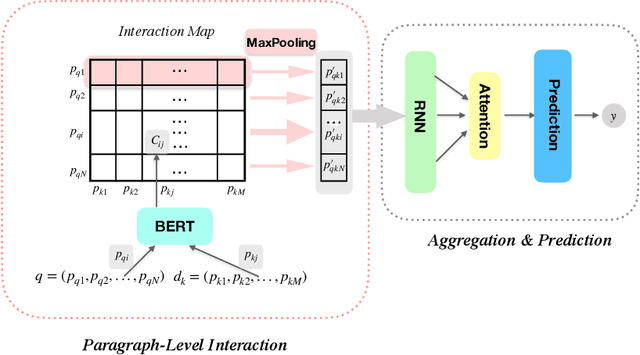

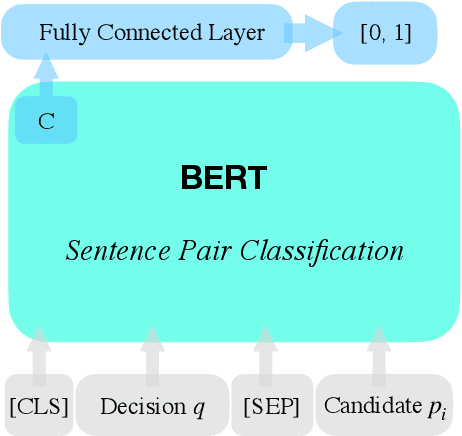
In this paper, we present our methodologies for tackling the challenges of legal case retrieval and entailment in the Competition on Legal Information Extraction / Entailment 2020 (COLIEE-2020). We participated in the two case law tasks, i.e., the legal case retrieval task and the legal case entailment task. Task 1 (the retrieval task) aims to automatically identify supporting cases from the case law corpus given a new case, and Task 2 (the entailment task) to identify specific paragraphs that entail the decision of a new case in a relevant case. In both tasks, we employed the neural models for semantic understanding and the traditional retrieval models for exact matching. As a result, our team (TLIR) ranked 2nd among all of the teams in Task 1 and 3rd among teams in Task 2. Experimental results suggest that combing models of semantic understanding and exact matching benefits the legal case retrieval task while the legal case entailment task relies more on semantic understanding.