 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOption-ID Based Elimination For Multiple Choice Questions
Jan 25, 2025



Multiple choice questions (MCQs) are a common and important task for evaluating large language models (LLMs). Based on common strategies humans use when answering MCQs, the process of elimination has been proposed as an effective problem-solving method. Existing methods to the process of elimination generally fall into two categories: one involves having the model directly select the incorrect answer, while the other involves scoring the options. However, both methods incur high computational costs and often perform worse than methods that answer based on option ID. To address this issue, this paper proposes a process of elimination based on option ID. We select 10 LLMs and conduct zero-shot experiments on 7 different datasets. The experimental results demonstrate that our method significantly improves the model's performance. Further analysis reveals that the sequential elimination strategy can effectively enhance the model's reasoning ability. Additionally, we find that sequential elimination is also applicable to few-shot settings and can be combined with debias methods to further improve model performance.
THUIR@COLIEE-2020: Leveraging Semantic Understanding and Exact Matching for Legal Case Retrieval and Entailment
Dec 24, 2020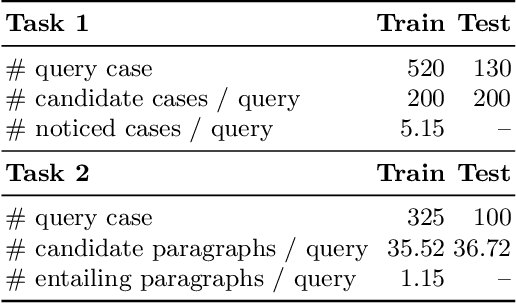
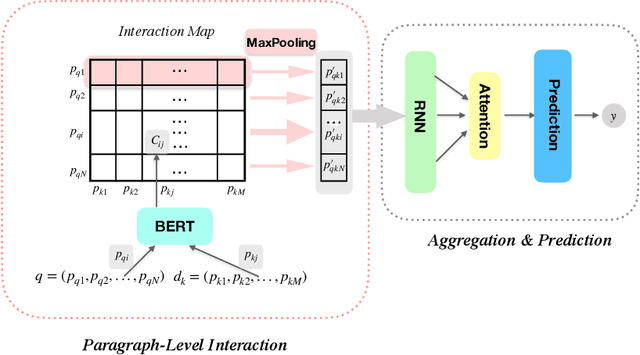

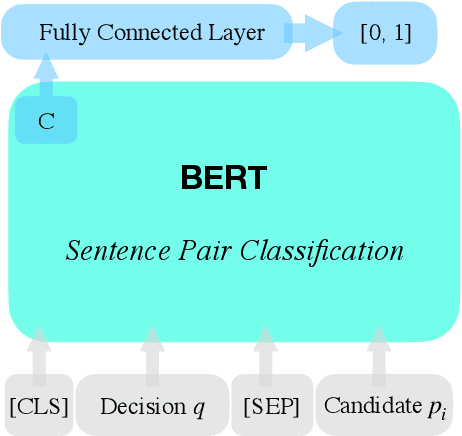
In this paper, we present our methodologies for tackling the challenges of legal case retrieval and entailment in the Competition on Legal Information Extraction / Entailment 2020 (COLIEE-2020). We participated in the two case law tasks, i.e., the legal case retrieval task and the legal case entailment task. Task 1 (the retrieval task) aims to automatically identify supporting cases from the case law corpus given a new case, and Task 2 (the entailment task) to identify specific paragraphs that entail the decision of a new case in a relevant case. In both tasks, we employed the neural models for semantic understanding and the traditional retrieval models for exact matching. As a result, our team (TLIR) ranked 2nd among all of the teams in Task 1 and 3rd among teams in Task 2. Experimental results suggest that combing models of semantic understanding and exact matching benefits the legal case retrieval task while the legal case entailment task relies more on semantic understanding.