 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Design for Reinforcement Learning Agents
Paper and Code
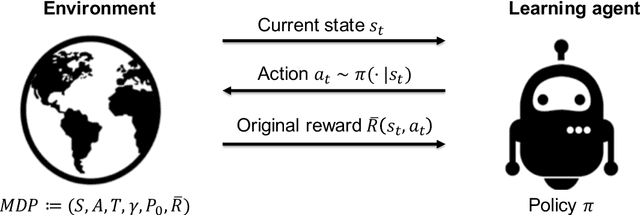
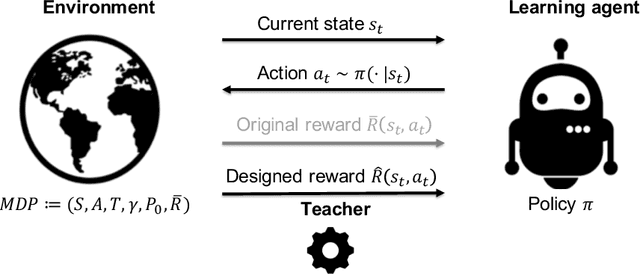
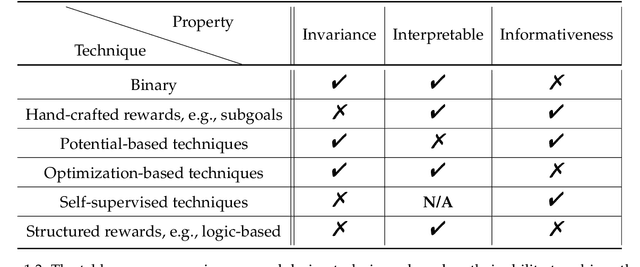

Reward functions are central in reinforcement learning (RL), guiding agents towards optimal decision-making. The complexity of RL tasks requires meticulously designed reward functions that effectively drive learning while avoiding unintended consequences. Effective reward design aims to provide signals that accelerate the agent's convergence to optimal behavior. Crafting rewards that align with task objectives, foster desired behaviors, and prevent undesirable actions is inherently challenging. This thesis delves into the critical role of reward signals in RL, highlighting their impact on the agent's behavior and learning dynamics and addressing challenges such as delayed, ambiguous, or intricate rewards. In this thesis work, we tackle different aspects of reward shaping. First, we address the problem of designing informative and interpretable reward signals from a teacher's/expert's perspective (teacher-driven). Here, the expert, equipped with the optimal policy and the corresponding value function, designs reward signals that expedite the agent's convergence to optimal behavior. Second, we build on this teacher-driven approach by introducing a novel method for adaptive interpretable reward design. In this scenario, the expert tailors the rewards based on the learner's current policy, ensuring alignment and optimal progression. Third, we propose a meta-learning approach, enabling the agent to self-design its reward signals online without expert input (agent-driven). This self-driven method considers the agent's learning and exploration to establish a self-improving feedback loop.