 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment Shaping in Reinforcement Learning using State Abstraction
Paper and Code
Jun 23, 2020
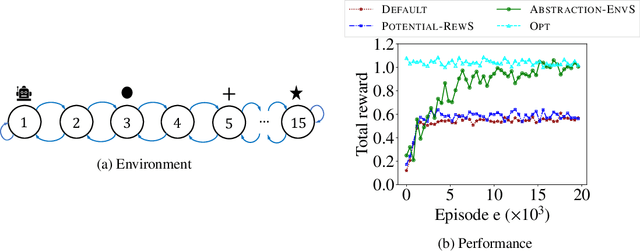
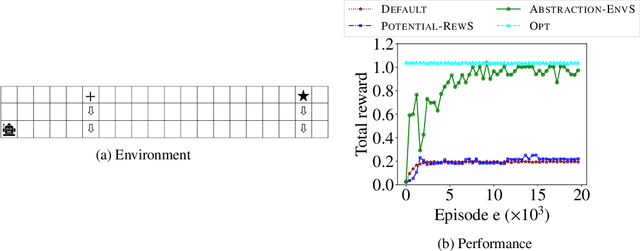
One of the central challenges faced by a reinforcement learning (RL) agent is to effectively learn a (near-)optimal policy in environments with large state spaces having sparse and noisy feedback signals. In real-world applications, an expert with additional domain knowledge can help in speeding up the learning process via \emph{shaping the environment}, i.e., making the environment more learner-friendly. A popular paradigm in literature is \emph{potential-based reward shaping}, where the environment's reward function is augmented with additional local rewards using a potential function. However, the applicability of potential-based reward shaping is limited in settings where (i) the state space is very large, and it is challenging to compute an appropriate potential function, (ii) the feedback signals are noisy, and even with shaped rewards the agent could be trapped in local optima, and (iii) changing the rewards alone is not sufficient, and effective shaping requires changing the dynamics. We address these limitations of potential-based shaping methods and propose a novel framework of \emph{environment shaping using state abstraction}. Our key idea is to compress the environment's large state space with noisy signals to an abstracted space, and to use this abstraction in creating smoother and more effective feedback signals for the agent. We study the theoretical underpinnings of our abstraction-based environment shaping, and show that the agent's policy learnt in the shaped environment preserves near-optimal behavior in the original environment.