 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPICE: Self-supervised Pitch Estimation
Paper and Code
Oct 25, 2019
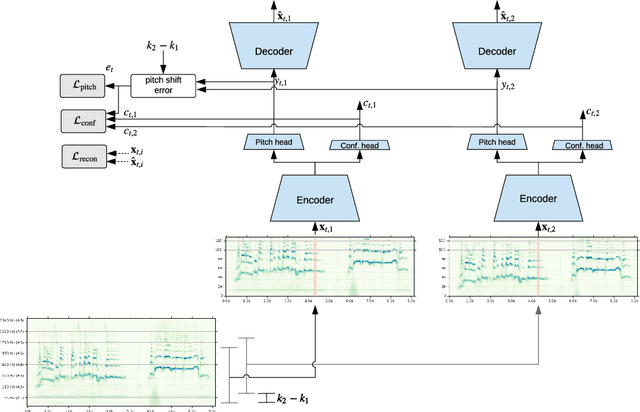
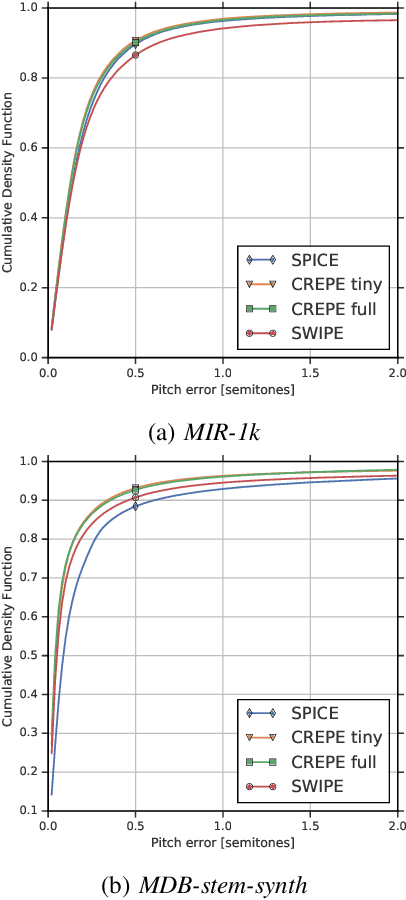
We propose a model to estimate the fundamental frequency in monophonic audio, often referred to as pitch estimation. We acknowledge the fact that obtaining ground truth annotations at the required temporal and frequency resolution is a particularly daunting task. Therefore, we propose to adopt a self-supervised learning technique, which is able to estimate (relative) pitch without any form of supervision. The key observation is that pitch shift maps to a simple translation when the audio signal is analysed through the lens of the constant-Q transform (CQT). We design a self-supervised task by feeding two shifted slices of the CQT to the same convolutional encoder, and require that the difference in the outputs is proportional to the corresponding difference in pitch. In addition, we introduce a small model head on top of the encoder, which is able to determine the confidence of the pitch estimate, so as to distinguish between voiced and unvoiced audio. Our results show that the proposed method is able to estimate pitch at a level of accuracy comparable to fully supervised models, both on clean and noisy audio samples, yet it does not require access to large labeled datasets