 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom BOP to BOSS and Beyond: Time Series Classification with Dictionary Based Classifiers
Paper and Code


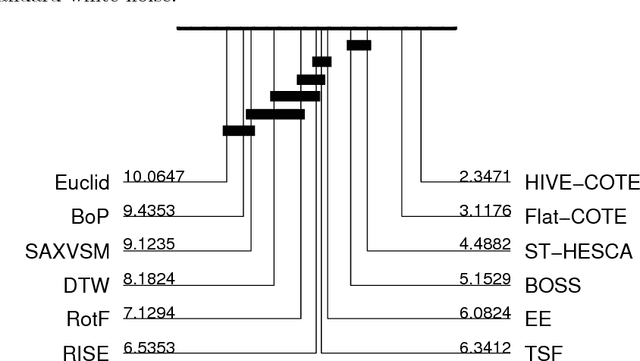
A family of algorithms for time series classification (TSC) involve running a sliding window across each series, discretising the window to form a word, forming a histogram of word counts over the dictionary, then constructing a classifier on the histograms. A recent evaluation of two of this type of algorithm, Bag of Patterns (BOP) and Bag of Symbolic Fourier Approximation Symbols (BOSS) found a significant difference in accuracy between these seemingly similar algorithms. We investigate this phenomenon by deconstructing the classifiers and measuring the relative importance of the four key components between BOP and BOSS. We find that whilst ensembling is a key component for both algorithms, the effect of the other components is mixed and more complex. We conclude that BOSS represents the state of the art for dictionary based TSC. Both BOP and BOSS can be classed as bag of words approaches. These are particularly popular in Computer Vision for tasks such as image classification. Converting approaches from vision requires careful engineering. We adapt three techniques used in Computer Vision for TSC: Scale Invariant Feature Transform; Spatial Pyramids; and Histrogram Intersection. We find that using Spatial Pyramids in conjunction with BOSS (SP) produces a significantly more accurate classifier. SP is significantly more accurate than standard benchmarks and the original BOSS algorithm. It is not significantly worse than the best shapelet based approach, and is only outperformed by HIVE-COTE, an ensemble that includes BOSS as a constituent module.