 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Gromov-Wasserstein with Applications on Positive-Unlabeled Learning
Paper and Code
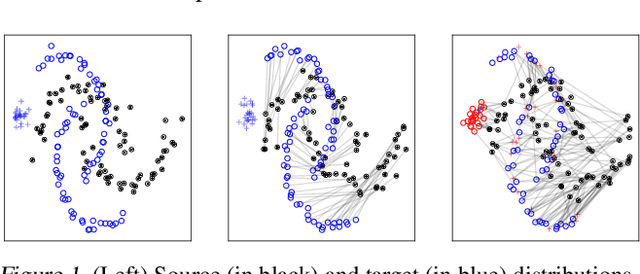
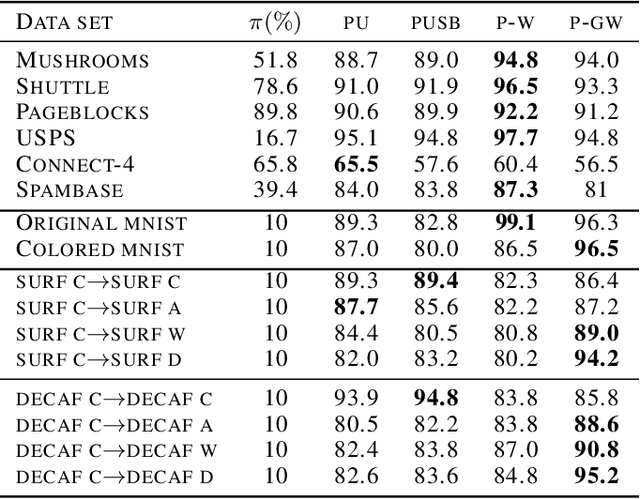
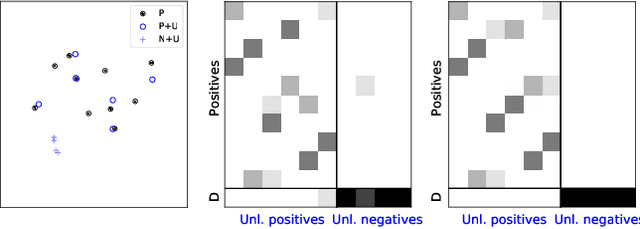

Optimal Transport (OT) framework allows defining similarity between probability distributions and provides metrics such as the Wasserstein and Gromov-Wasserstein discrepancies. Classical OT problem seeks a transportation map that preserves the total mass, requiring the mass of the source and target distributions to be the same. This may be too restrictive in certain applications such as color or shape matching, since the distributions may have arbitrary masses or that only a fraction of the total mass has to be transported. Several algorithms have been devised for computing unbalanced Wasserstein metrics but when it comes with the Gromov-Wasserstein problem, no partial formulation is available yet. This precludes from working with distributions that do not lie in the same metric space or when invariance to rotation or translation is needed. In this paper, we address the partial Gromov-Wasserstein problem and propose an algorithm to solve it. We showcase the new formulation in a positive-unlabeled (PU) learning application. To the best of our knowledge, this is the first application of optimal transport in this context and we first highlight that partial Wasserstein-based metrics prove effective in usual PU learning settings. We then demonstrate that partial Gromov-Wasserstein metrics is efficient in scenario where point clouds come from different domains or have different features.