 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAEMA: Denoising Autoencoder with Mask Attention
Jun 30, 2021
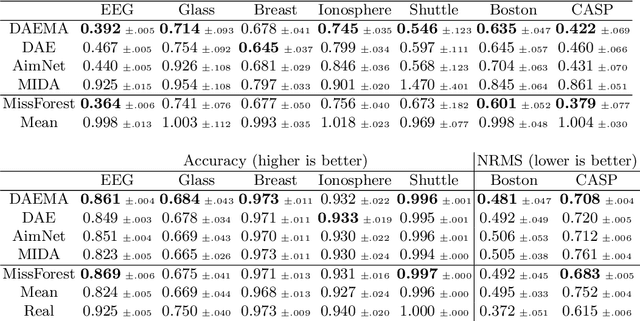
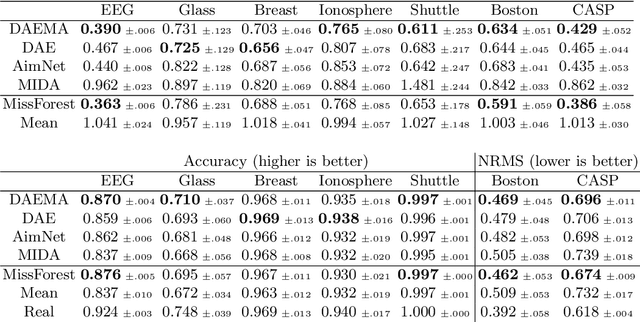
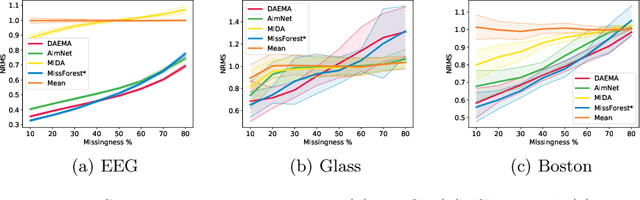
Missing data is a recurrent and challenging problem, especially when using machine learning algorithms for real-world applications. For this reason, missing data imputation has become an active research area, in which recent deep learning approaches have achieved state-of-the-art results. We propose DAEMA (Denoising Autoencoder with Mask Attention), an algorithm based on a denoising autoencoder architecture with an attention mechanism. While most imputation algorithms use incomplete inputs as they would use complete data - up to basic preprocessing (e.g. mean imputation) - DAEMA leverages a mask-based attention mechanism to focus on the observed values of its inputs. We evaluate DAEMA both in terms of reconstruction capabilities and downstream prediction and show that it achieves superior performance to state-of-the-art algorithms on several publicly available real-world datasets under various missingness settings.
A Framework using Contrastive Learning for Classification with Noisy Labels
Apr 19, 2021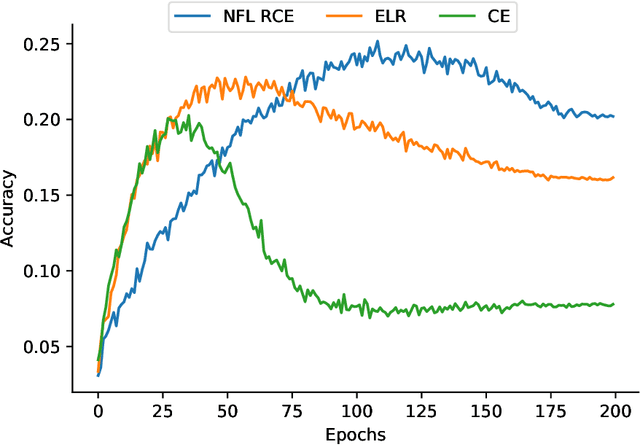
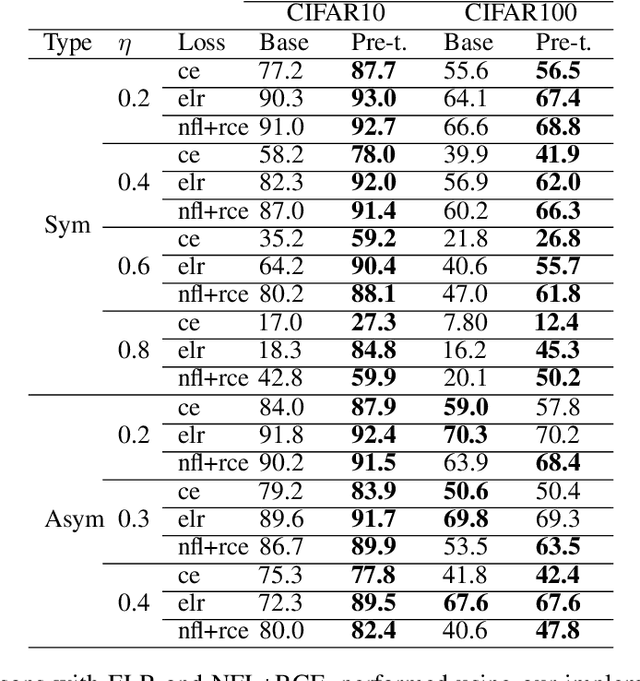
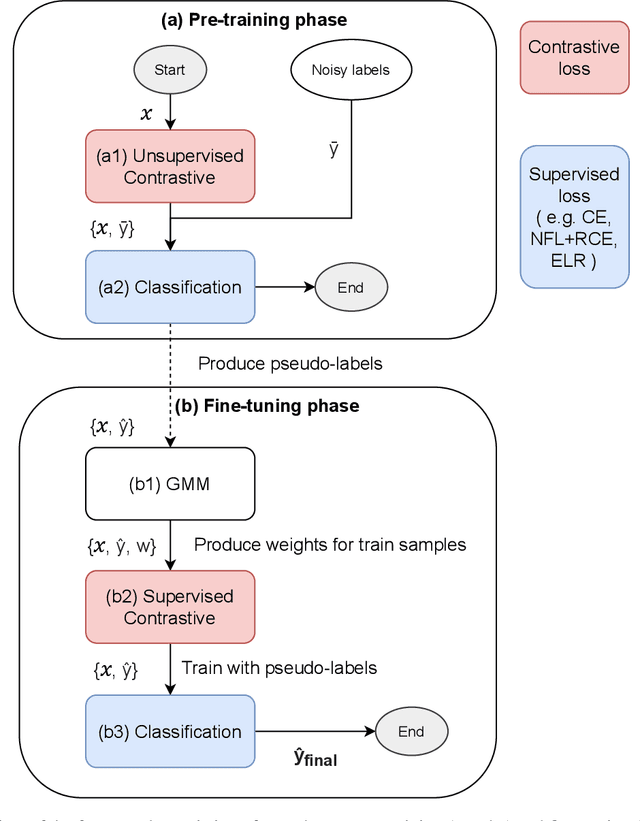
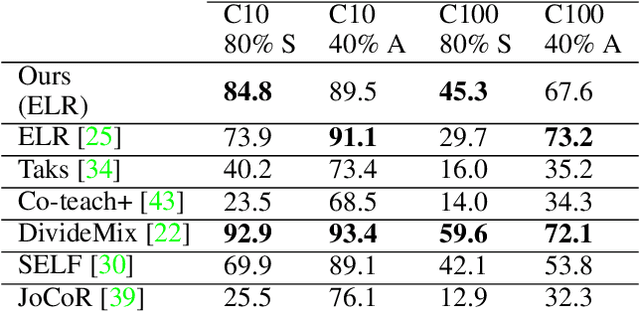
We propose a framework using contrastive learning as a pre-training task to perform image classification in the presence of noisy labels. Recent strategies such as pseudo-labeling, sample selection with Gaussian Mixture models, weighted supervised contrastive learning have been combined into a fine-tuning phase following the pre-training. This paper provides an extensive empirical study showing that a preliminary contrastive learning step brings a significant gain in performance when using different loss functions: non-robust, robust, and early-learning regularized. Our experiments performed on standard benchmarks and real-world datasets demonstrate that: i) the contrastive pre-training increases the robustness of any loss function to noisy labels and ii) the additional fine-tuning phase can further improve accuracy but at the cost of additional complexity.
STRASS: A Light and Effective Method for Extractive Summarization Based on Sentence Embeddings
Jul 16, 2019

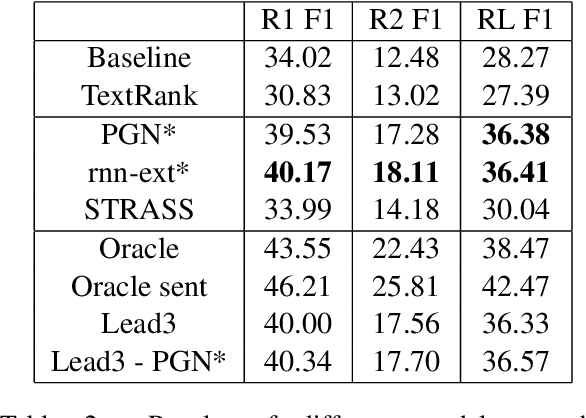

This paper introduces STRASS: Summarization by TRAnsformation Selection and Scoring. It is an extractive text summarization method which leverages the semantic information in existing sentence embedding spaces. Our method creates an extractive summary by selecting the sentences with the closest embeddings to the document embedding. The model learns a transformation of the document embedding to minimize the similarity between the extractive summary and the ground truth summary. As the transformation is only composed of a dense layer, the training can be done on CPU, therefore, inexpensive. Moreover, inference time is short and linear according to the number of sentences. As a second contribution, we introduce the French CASS dataset, composed of judgments from the French Court of cassation and their corresponding summaries. On this dataset, our results show that our method performs similarly to the state of the art extractive methods with effective training and inferring time.
Stochastic Low-Rank Kernel Learning for Regression
Jan 11, 2012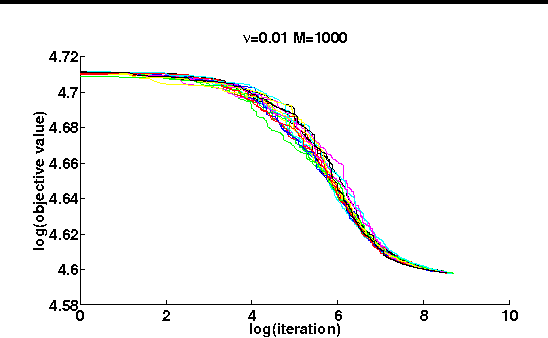
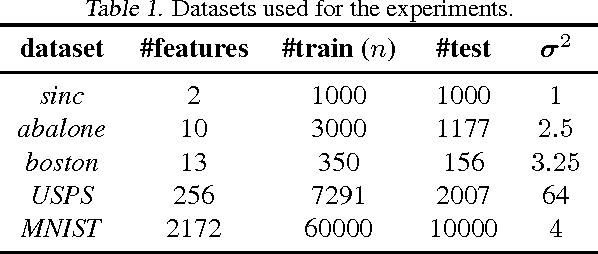
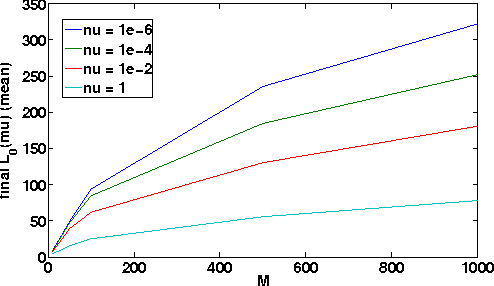
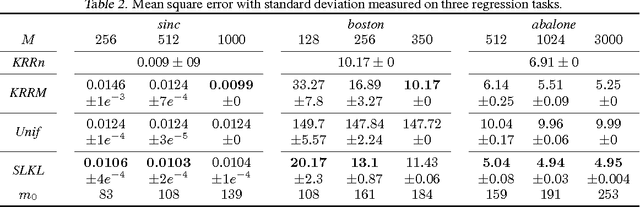
We present a novel approach to learn a kernel-based regression function. It is based on the useof conical combinations of data-based parameterized kernels and on a new stochastic convex optimization procedure of which we establish convergence guarantees. The overall learning procedure has the nice properties that a) the learned conical combination is automatically designed to perform the regression task at hand and b) the updates implicated by the optimization procedure are quite inexpensive. In order to shed light on the appositeness of our learning strategy, we present empirical results from experiments conducted on various benchmark datasets.