 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugment to Interpret: Unsupervised and Inherently Interpretable Graph Embeddings
Sep 28, 2023



Unsupervised learning allows us to leverage unlabelled data, which has become abundantly available, and to create embeddings that are usable on a variety of downstream tasks. However, the typical lack of interpretability of unsupervised representation learning has become a limiting factor with regard to recent transparent-AI regulations. In this paper, we study graph representation learning and we show that data augmentation that preserves semantics can be learned and used to produce interpretations. Our framework, which we named INGENIOUS, creates inherently interpretable embeddings and eliminates the need for costly additional post-hoc analysis. We also introduce additional metrics addressing the lack of formalism and metrics in the understudied area of unsupervised-representation learning interpretability. Our results are supported by an experimental study applied to both graph-level and node-level tasks and show that interpretable embeddings provide state-of-the-art performance on subsequent downstream tasks.
A Framework using Contrastive Learning for Classification with Noisy Labels
Apr 19, 2021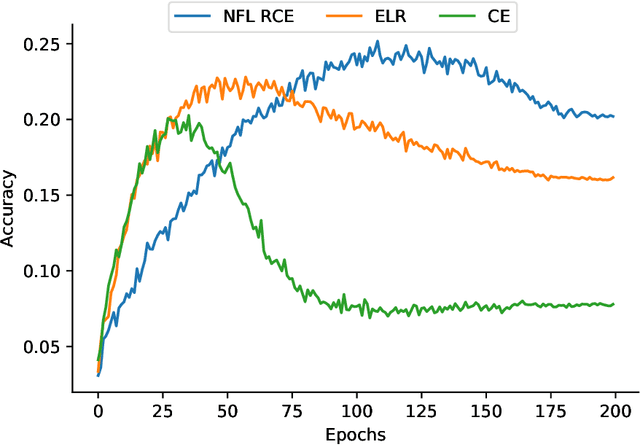
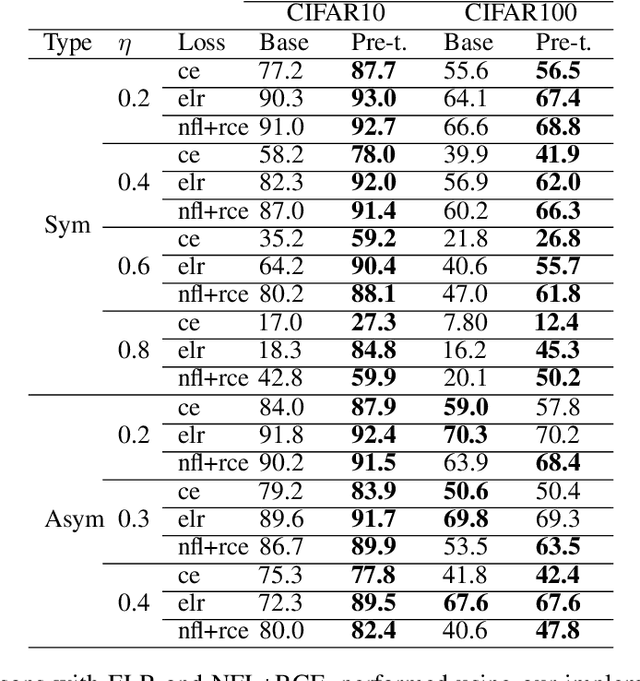
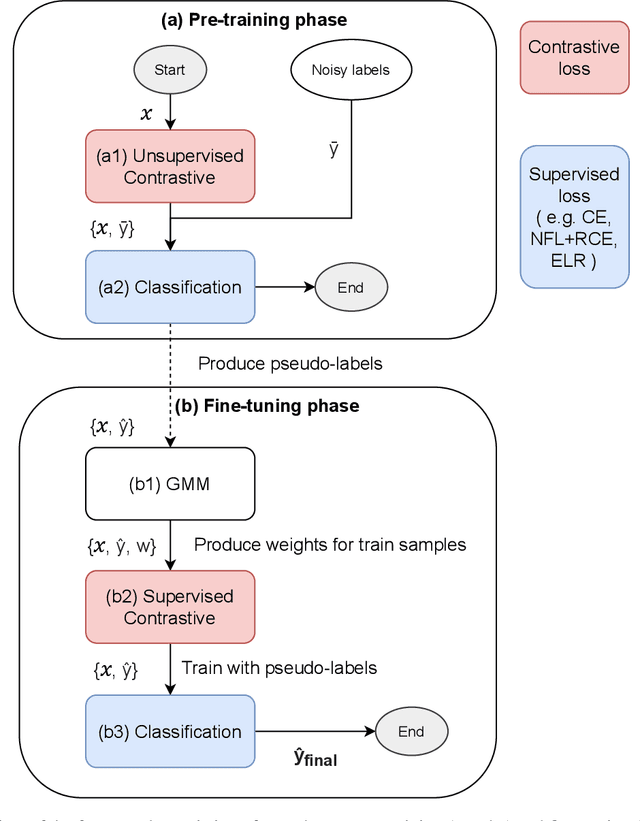
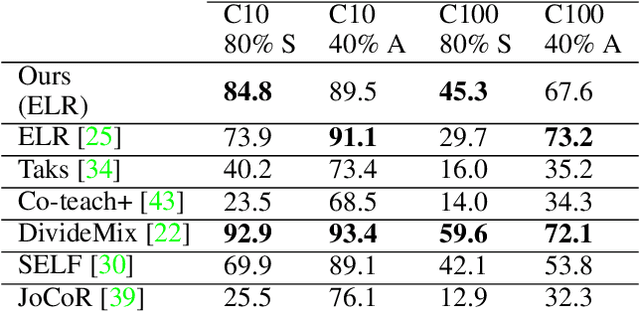
We propose a framework using contrastive learning as a pre-training task to perform image classification in the presence of noisy labels. Recent strategies such as pseudo-labeling, sample selection with Gaussian Mixture models, weighted supervised contrastive learning have been combined into a fine-tuning phase following the pre-training. This paper provides an extensive empirical study showing that a preliminary contrastive learning step brings a significant gain in performance when using different loss functions: non-robust, robust, and early-learning regularized. Our experiments performed on standard benchmarks and real-world datasets demonstrate that: i) the contrastive pre-training increases the robustness of any loss function to noisy labels and ii) the additional fine-tuning phase can further improve accuracy but at the cost of additional complexity.