 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugment to Interpret: Unsupervised and Inherently Interpretable Graph Embeddings
Sep 28, 2023



Unsupervised learning allows us to leverage unlabelled data, which has become abundantly available, and to create embeddings that are usable on a variety of downstream tasks. However, the typical lack of interpretability of unsupervised representation learning has become a limiting factor with regard to recent transparent-AI regulations. In this paper, we study graph representation learning and we show that data augmentation that preserves semantics can be learned and used to produce interpretations. Our framework, which we named INGENIOUS, creates inherently interpretable embeddings and eliminates the need for costly additional post-hoc analysis. We also introduce additional metrics addressing the lack of formalism and metrics in the understudied area of unsupervised-representation learning interpretability. Our results are supported by an experimental study applied to both graph-level and node-level tasks and show that interpretable embeddings provide state-of-the-art performance on subsequent downstream tasks.
DAEMA: Denoising Autoencoder with Mask Attention
Jun 30, 2021
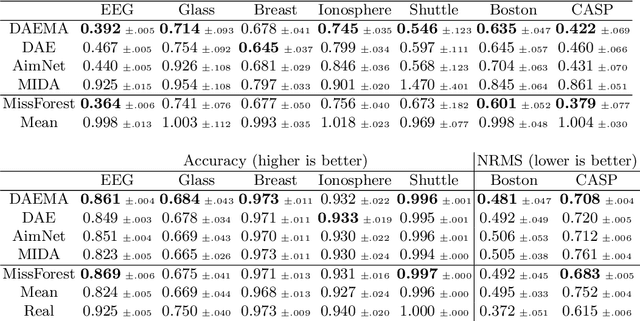
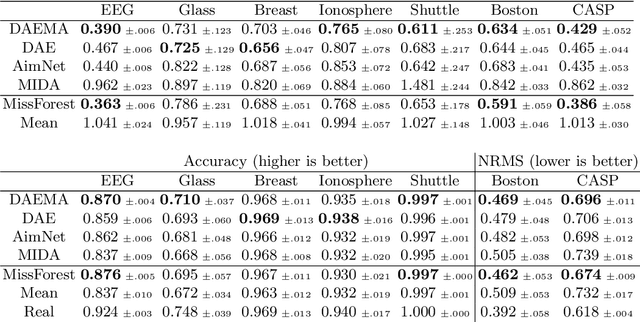
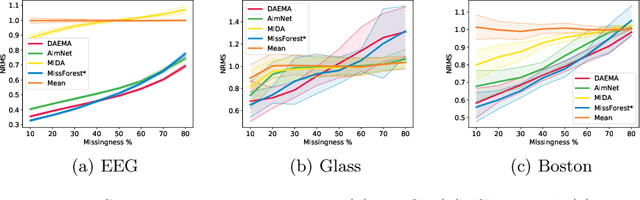
Missing data is a recurrent and challenging problem, especially when using machine learning algorithms for real-world applications. For this reason, missing data imputation has become an active research area, in which recent deep learning approaches have achieved state-of-the-art results. We propose DAEMA (Denoising Autoencoder with Mask Attention), an algorithm based on a denoising autoencoder architecture with an attention mechanism. While most imputation algorithms use incomplete inputs as they would use complete data - up to basic preprocessing (e.g. mean imputation) - DAEMA leverages a mask-based attention mechanism to focus on the observed values of its inputs. We evaluate DAEMA both in terms of reconstruction capabilities and downstream prediction and show that it achieves superior performance to state-of-the-art algorithms on several publicly available real-world datasets under various missingness settings.
Anomaly Detection: How to Artificially Increase your F1-Score with a Biased Evaluation Protocol
Jun 30, 2021
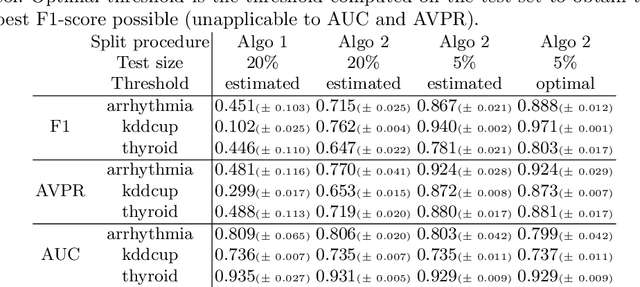
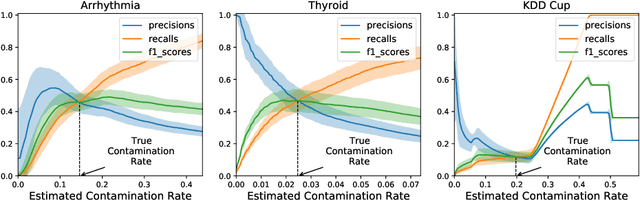
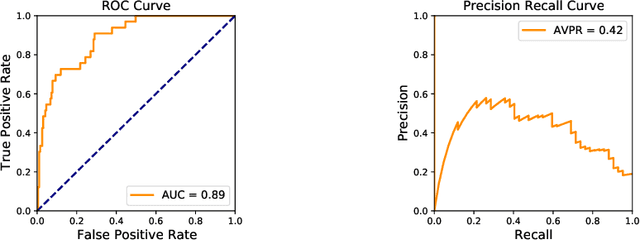
Anomaly detection is a widely explored domain in machine learning. Many models are proposed in the literature, and compared through different metrics measured on various datasets. The most popular metrics used to compare performances are F1-score, AUC and AVPR. In this paper, we show that F1-score and AVPR are highly sensitive to the contamination rate. One consequence is that it is possible to artificially increase their values by modifying the train-test split procedure. This leads to misleading comparisons between algorithms in the literature, especially when the evaluation protocol is not well detailed. Moreover, we show that the F1-score and the AVPR cannot be used to compare performances on different datasets as they do not reflect the intrinsic difficulty of modeling such data. Based on these observations, we claim that F1-score and AVPR should not be used as metrics for anomaly detection. We recommend a generic evaluation procedure for unsupervised anomaly detection, including the use of other metrics such as the AUC, which are more robust to arbitrary choices in the evaluation protocol.