 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSANGEA: Scalable and Attributed Network Generation
Sep 27, 2023



The topic of synthetic graph generators (SGGs) has recently received much attention due to the wave of the latest breakthroughs in generative modelling. However, many state-of-the-art SGGs do not scale well with the graph size. Indeed, in the generation process, all the possible edges for a fixed number of nodes must often be considered, which scales in $\mathcal{O}(N^2)$, with $N$ being the number of nodes in the graph. For this reason, many state-of-the-art SGGs are not applicable to large graphs. In this paper, we present SANGEA, a sizeable synthetic graph generation framework which extends the applicability of any SGG to large graphs. By first splitting the large graph into communities, SANGEA trains one SGG per community, then links the community graphs back together to create a synthetic large graph. Our experiments show that the graphs generated by SANGEA have high similarity to the original graph, in terms of both topology and node feature distribution. Additionally, these generated graphs achieve high utility on downstream tasks such as link prediction. Finally, we provide a privacy assessment of the generated graphs to show that, even though they have excellent utility, they also achieve reasonable privacy scores.
Calibrate to Interpret
Jul 07, 2022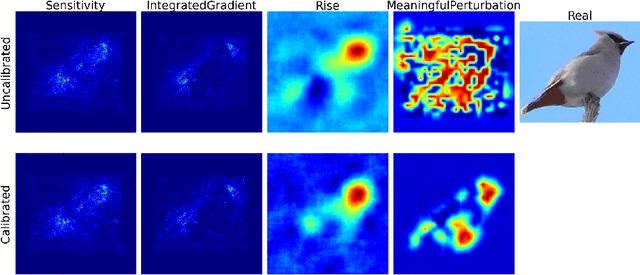
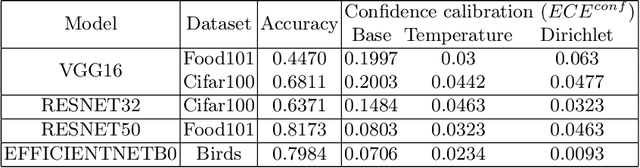
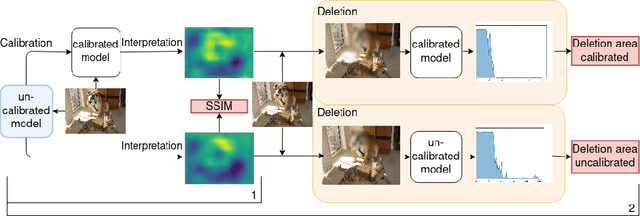
Trustworthy machine learning is driving a large number of ML community works in order to improve ML acceptance and adoption. The main aspect of trustworthy machine learning are the followings: fairness, uncertainty, robustness, explainability and formal guaranties. Each of these individual domains gains the ML community interest, visible by the number of related publications. However few works tackle the interconnection between these fields. In this paper we show a first link between uncertainty and explainability, by studying the relation between calibration and interpretation. As the calibration of a given model changes the way it scores samples, and interpretation approaches often rely on these scores, it seems safe to assume that the confidence-calibration of a model interacts with our ability to interpret such model. In this paper, we show, in the context of networks trained on image classification tasks, to what extent interpretations are sensitive to confidence-calibration. It leads us to suggest a simple practice to improve the interpretation outcomes: Calibrate to Interpret.
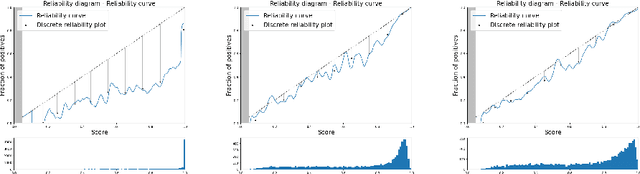
Estimating Expected Calibration Errors
Sep 08, 2021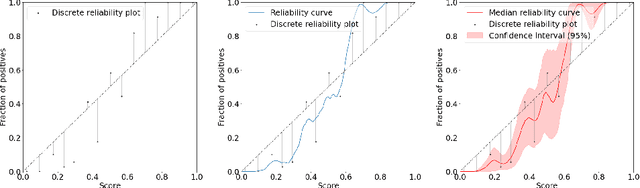
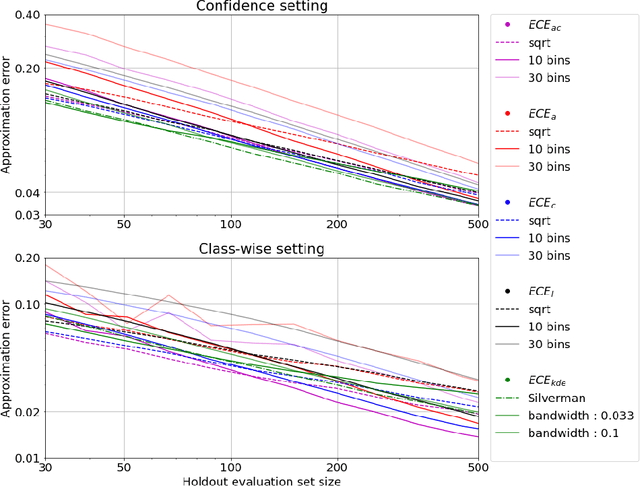
Uncertainty in probabilistic classifiers predictions is a key concern when models are used to support human decision making, in broader probabilistic pipelines or when sensitive automatic decisions have to be taken. Studies have shown that most models are not intrinsically well calibrated, meaning that their decision scores are not consistent with posterior probabilities. Hence being able to calibrate these models, or enforce calibration while learning them, has regained interest in recent literature. In this context, properly assessing calibration is paramount to quantify new contributions tackling calibration. However, there is room for improvement for commonly used metrics and evaluation of calibration could benefit from deeper analyses. Thus this paper focuses on the empirical evaluation of calibration metrics in the context of classification. More specifically it evaluates different estimators of the Expected Calibration Error ($ECE$), amongst which legacy estimators and some novel ones, proposed in this paper. We build an empirical procedure to quantify the quality of these $ECE$ estimators, and use it to decide which estimator should be used in practice for different settings.
DAEMA: Denoising Autoencoder with Mask Attention
Jun 30, 2021
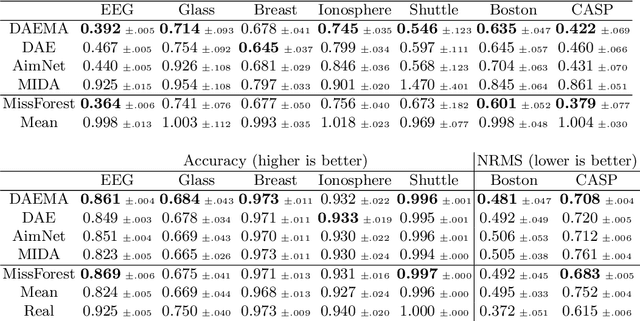
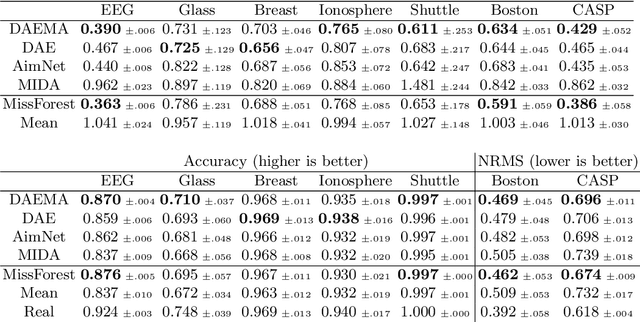
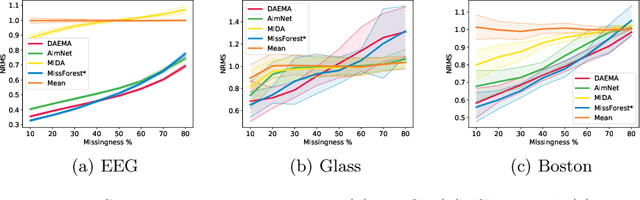
Missing data is a recurrent and challenging problem, especially when using machine learning algorithms for real-world applications. For this reason, missing data imputation has become an active research area, in which recent deep learning approaches have achieved state-of-the-art results. We propose DAEMA (Denoising Autoencoder with Mask Attention), an algorithm based on a denoising autoencoder architecture with an attention mechanism. While most imputation algorithms use incomplete inputs as they would use complete data - up to basic preprocessing (e.g. mean imputation) - DAEMA leverages a mask-based attention mechanism to focus on the observed values of its inputs. We evaluate DAEMA both in terms of reconstruction capabilities and downstream prediction and show that it achieves superior performance to state-of-the-art algorithms on several publicly available real-world datasets under various missingness settings.
Anomaly Detection: How to Artificially Increase your F1-Score with a Biased Evaluation Protocol
Jun 30, 2021
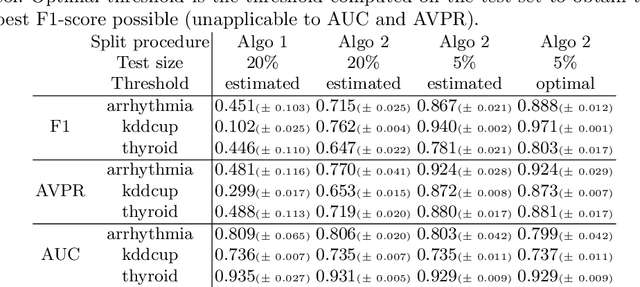
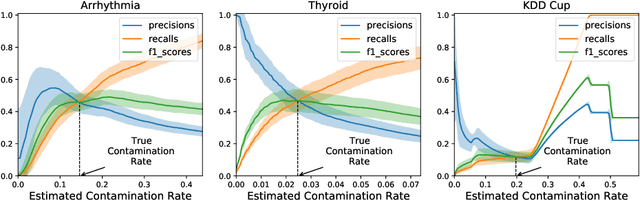
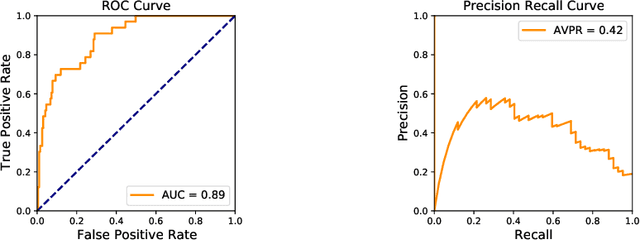
Anomaly detection is a widely explored domain in machine learning. Many models are proposed in the literature, and compared through different metrics measured on various datasets. The most popular metrics used to compare performances are F1-score, AUC and AVPR. In this paper, we show that F1-score and AVPR are highly sensitive to the contamination rate. One consequence is that it is possible to artificially increase their values by modifying the train-test split procedure. This leads to misleading comparisons between algorithms in the literature, especially when the evaluation protocol is not well detailed. Moreover, we show that the F1-score and the AVPR cannot be used to compare performances on different datasets as they do not reflect the intrinsic difficulty of modeling such data. Based on these observations, we claim that F1-score and AVPR should not be used as metrics for anomaly detection. We recommend a generic evaluation procedure for unsupervised anomaly detection, including the use of other metrics such as the AUC, which are more robust to arbitrary choices in the evaluation protocol.
Automated Estimation of the Spinal Curvature via Spine Centerline Extraction with Ensembles of Cascaded Neural Networks
Dec 11, 2019

Scoliosis is a condition defined by an abnormal spinal curvature. For diagnosis and treatment planning of scoliosis, spinal curvature can be estimated using Cobb angles. We propose an automated method for the estimation of Cobb angles from X-ray scans. First, the centerline of the spine was segmented using a cascade of two convolutional neural networks. After smoothing the centerline, Cobb angles were automatically estimated using the derivative of the centerline. We evaluated the results using the mean absolute error and the average symmetric mean absolute percentage error between the manual assessment by experts and the automated predictions. For optimization, we used 609 X-ray scans from the London Health Sciences Center, and for evaluation, we participated in the international challenge "Accurate Automated Spinal Curvature Estimation, MICCAI 2019" (100 scans). On the challenge's test set, we obtained an average symmetric mean absolute percentage error of 22.96.