 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Segmentation and Volume Measurement of Intracranial Carotid Artery Calcification on Non-Contrast CT
Jul 20, 2021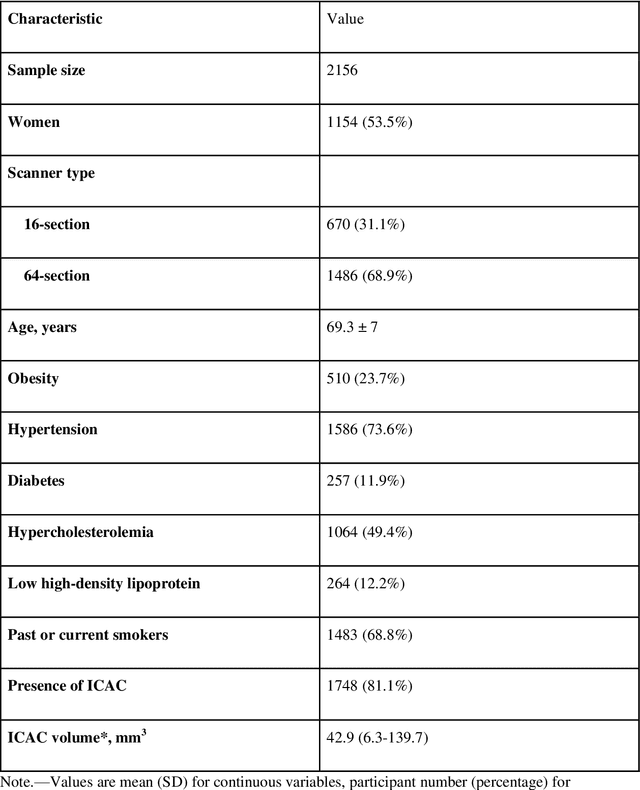
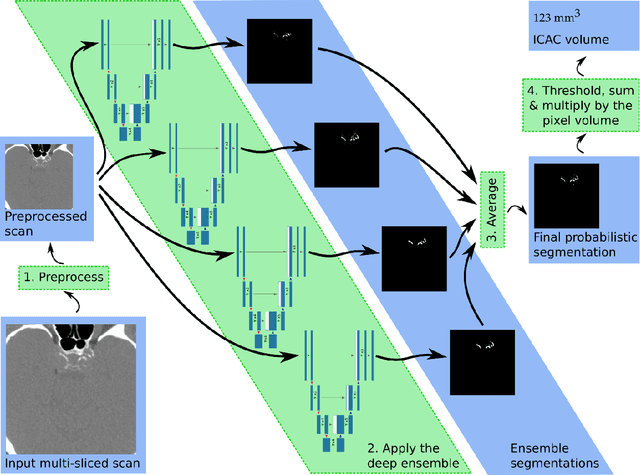
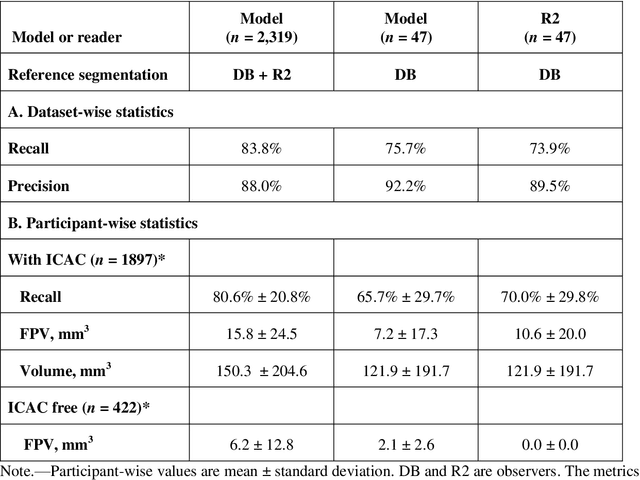
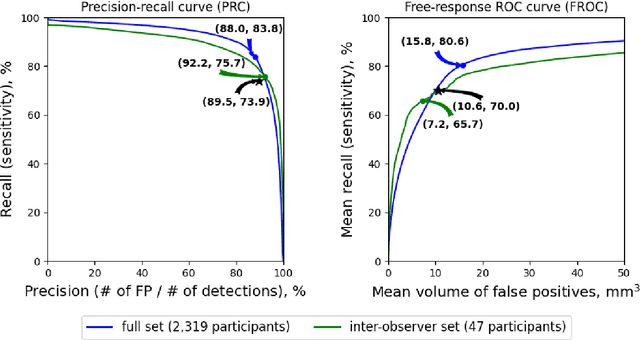
Purpose: To evaluate a fully-automated deep-learning-based method for assessment of intracranial carotid artery calcification (ICAC). Methods: Two observers manually delineated ICAC in non-contrast CT scans of 2,319 participants (mean age 69 (SD 7) years; 1154 women) of the Rotterdam Study, prospectively collected between 2003 and 2006. These data were used to retrospectively develop and validate a deep-learning-based method for automated ICAC delineation and volume measurement. To evaluate the method, we compared manual and automatic assessment (computed using ten-fold cross-validation) with respect to 1) the agreement with an independent observer's assessment (available in a random subset of 47 scans); 2) the accuracy in delineating ICAC as judged via blinded visual comparison by an expert; 3) the association with first stroke incidence from the scan date until 2012. All method performance metrics were computed using 10-fold cross-validation. Results: The automated delineation of ICAC reached sensitivity of 83.8% and positive predictive value (PPV) of 88%. The intraclass correlation between automatic and manual ICAC volume measures was 0.98 (95% CI: 0.97, 0.98; computed in the entire dataset). Measured between the assessments of independent observers, sensitivity was 73.9%, PPV was 89.5%, and intraclass correlation was 0.91 (95% CI: 0.84, 0.95; computed in the 47-scan subset). In the blinded visual comparisons, automatic delineations were more accurate than manual ones (p-value = 0.01). The association of ICAC volume with incident stroke was similarly strong for both automated (hazard ratio, 1.38 (95% CI: 1.12, 1.75) and manually measured volumes (hazard ratio, 1.48 (95% CI: 1.20, 1.87)). Conclusions: The developed model was capable of automated segmentation and volume quantification of ICAC with accuracy comparable to human experts.
Adversarial Heart Attack: Neural Networks Fooled to Segment Heart Symbols in Chest X-Ray Images
Apr 07, 2021
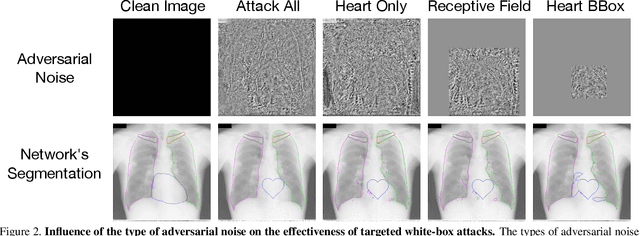
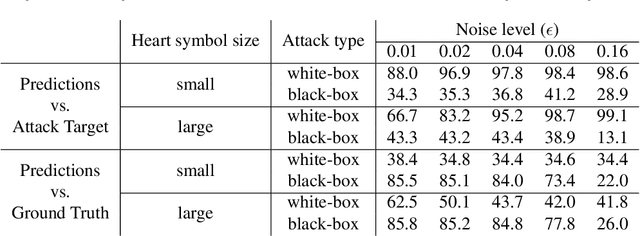
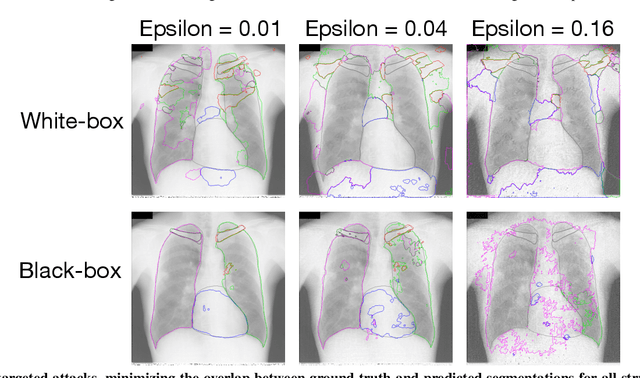
Adversarial attacks consist in maliciously changing the input data to mislead the predictions of automated decision systems and are potentially a serious threat for automated medical image analysis. Previous studies have shown that it is possible to adversarially manipulate automated segmentations produced by neural networks in a targeted manner in the white-box attack setting. In this article, we studied the effectiveness of adversarial attacks in targeted modification of segmentations of anatomical structures in chest X-rays. Firstly, we experimented with using anatomically implausible shapes as targets for adversarial manipulation. We showed that, by adding almost imperceptible noise to the image, we can reliably force state-of-the-art neural networks to segment the heart as a heart symbol instead of its real anatomical shape. Moreover, such heart-shaping attack did not appear to require higher adversarial noise level than an untargeted attack based the same attack method. Secondly, we attempted to explore the limits of adversarial manipulation of segmentations. For that, we assessed the effectiveness of shrinking and enlarging segmentation contours for the three anatomical structures. We observed that adversarially extending segmentations of structures into regions with intensity and texture uncharacteristic for them presented a challenge to our attacks, as well as, in some cases, changing segmentations in ways that conflict with class adjacency priors learned by the target network. Additionally, we evaluated performances of the untargeted attacks and targeted heart attacks in the black-box attack scenario, using a surrogate network trained on a different subset of images. In both cases, the attacks were substantially less effective. We believe these findings bring novel insights into the current capabilities and limits of adversarial attacks for semantic segmentation.
DS6: Deformation-aware learning for small vessel segmentation with small, imperfectly labeled dataset
Jun 18, 2020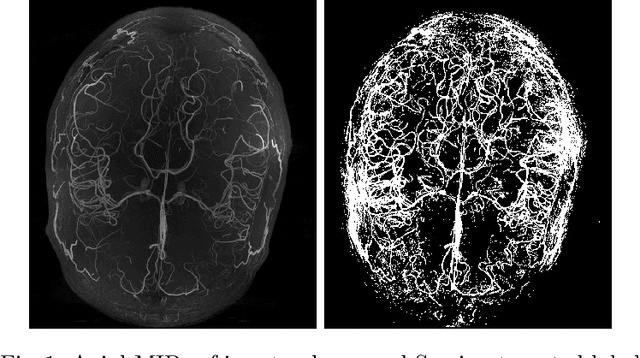
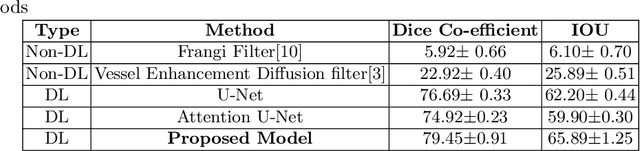


Originating from the initial segment of the middle cerebral artery of the human brain, Lenticulostriate Arteries (LSA) are a collection of perforating vessels that supply blood to the basal ganglia region. With the advancement of 7 Tesla scanner, we are able to detect these LSA which are linked to Small Vessel Diseases(SVD) and potentially a cause for neurodegenerative diseases. Segmentation of LSA with traditional approaches like Frangi or semi-automated/manual techniques can depict medium to large vessels but fail to depict the small vessels. Also, semi-automated/manual approaches are time-consuming. In this paper, we put forth a study that incorporates deep learning techniques to automatically segment these LSA using 3D 7 Tesla Time-of-fight Magnetic Resonance Angiogram images. The algorithm is trained and evaluated on a small dataset of 11 volumes. Deep learning models based on Multi-Scale Supervision U-Net accompanied by elastic deformations to give equivariance to the model, were utilized for the vessel segmentation using semi-automated labeled images. We make a qualitative analysis of the output with the original image and also on imperfect semi-manual labels to confirm the presence and continuity of small vessels.
Adversarial Attack Vulnerability of Medical Image Analysis Systems: Unexplored Factors
Jun 12, 2020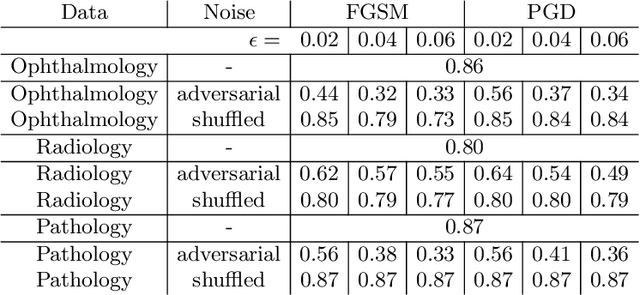
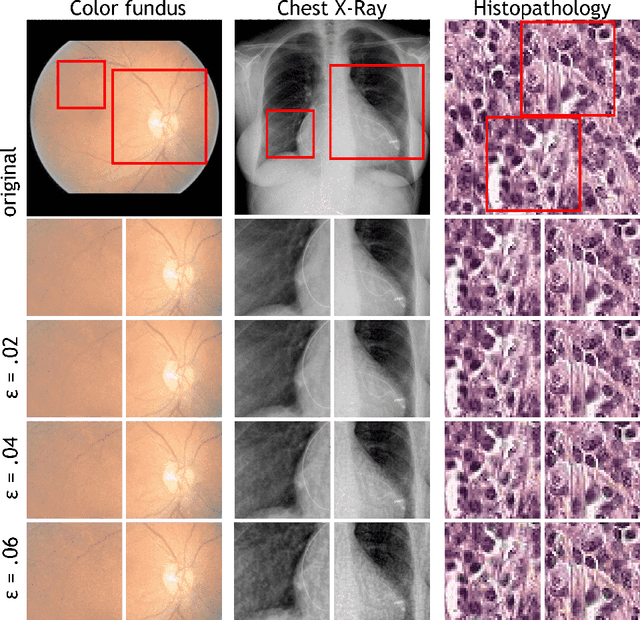
Adversarial attacks are considered a potentially serious security threat for machine learning systems. Medical image analysis (MedIA) systems have recently been argued to be particularly vulnerable to adversarial attacks due to strong financial incentives. In this paper, we study several previously unexplored factors affecting adversarial attack vulnerability of deep learning MedIA systems in three medical domains: ophthalmology, radiology and pathology. Firstly, we study the effect of varying the degree of adversarial perturbation on the attack performance and its visual perceptibility. Secondly, we study how pre-training on a public dataset (ImageNet) affects the models' vulnerability to attacks. Thirdly, we study the influence of data and model architecture disparity between target and attacker models. Our experiments show that the degree of perturbation significantly affects both performance and human perceptibility of attacks. Pre-training may dramatically increase the transfer of adversarial examples; the larger the performance gain achieved by pre-training, the larger the transfer. Finally, disparity in data and/or model architecture between target and attacker models substantially decreases the success of attacks. We believe that these factors should be considered when designing cybersecurity-critical MedIA systems, as well as kept in mind when evaluating their vulnerability to adversarial attacks.
Automated Estimation of the Spinal Curvature via Spine Centerline Extraction with Ensembles of Cascaded Neural Networks
Dec 11, 2019

Scoliosis is a condition defined by an abnormal spinal curvature. For diagnosis and treatment planning of scoliosis, spinal curvature can be estimated using Cobb angles. We propose an automated method for the estimation of Cobb angles from X-ray scans. First, the centerline of the spine was segmented using a cascade of two convolutional neural networks. After smoothing the centerline, Cobb angles were automatically estimated using the derivative of the centerline. We evaluated the results using the mean absolute error and the average symmetric mean absolute percentage error between the manual assessment by experts and the automated predictions. For optimization, we used 609 X-ray scans from the London Health Sciences Center, and for evaluation, we participated in the international challenge "Accurate Automated Spinal Curvature Estimation, MICCAI 2019" (100 scans). On the challenge's test set, we obtained an average symmetric mean absolute percentage error of 22.96.
Semi-Supervised Medical Image Segmentation via Learning Consistency under Transformations
Nov 04, 2019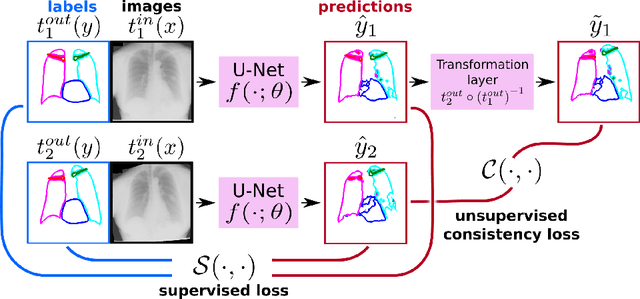
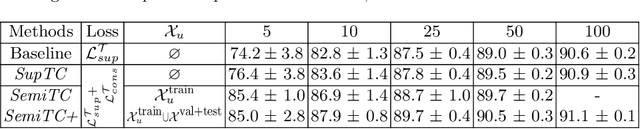
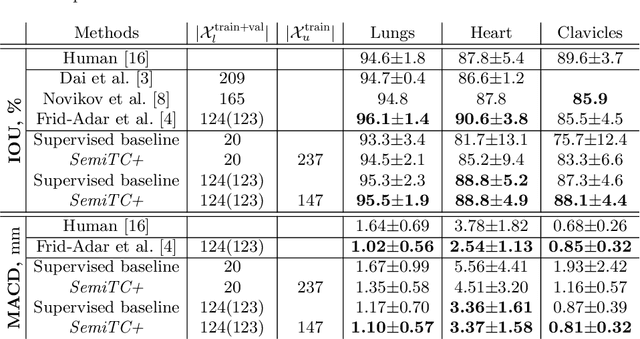
The scarcity of labeled data often limits the application of supervised deep learning techniques for medical image segmentation. This has motivated the development of semi-supervised techniques that learn from a mixture of labeled and unlabeled images. In this paper, we propose a novel semi-supervised method that, in addition to supervised learning on labeled training images, learns to predict segmentations consistent under a given class of transformations on both labeled and unlabeled images. More specifically, in this work we explore learning equivariance to elastic deformations. We implement this through: 1) a Siamese architecture with two identical branches, each of which receives a differently transformed image, and 2) a composite loss function with a supervised segmentation loss term and an unsupervised term that encourages segmentation consistency between the predictions of the two branches. We evaluate the method on a public dataset of chest radiographs with segmentations of anatomical structures using 5-fold cross-validation. The proposed method reaches significantly higher segmentation accuracy compared to supervised learning. This is due to learning transformation consistency on both labeled and unlabeled images, with the latter contributing the most. We achieve the performance comparable to state-of-the-art chest X-ray segmentation methods while using substantially fewer labeled images.
Multi-Task Attention-Based Semi-Supervised Learning for Medical Image Segmentation
Jul 29, 2019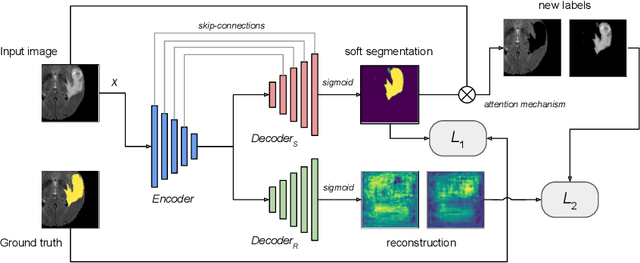
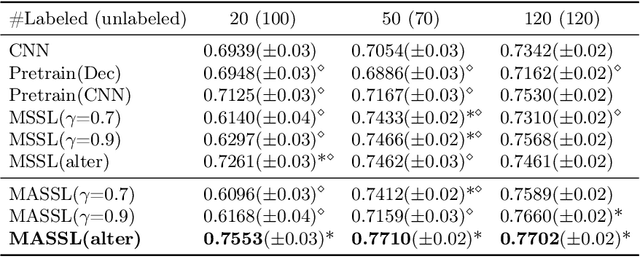
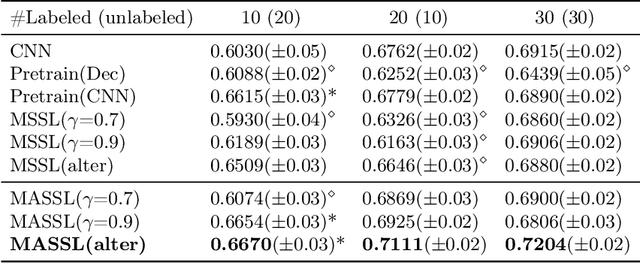
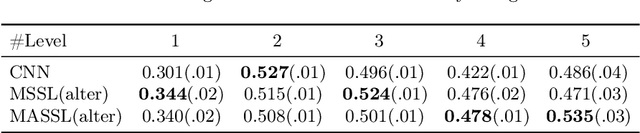
We propose a novel semi-supervised image segmentation method that simultaneously optimizes a supervised segmentation and an unsupervised reconstruction objectives. The reconstruction objective uses an attention mechanism that separates the reconstruction of image areas corresponding to different classes. The proposed approach was evaluated on two applications: brain tumor and white matter hyperintensities segmentation. Our method, trained on unlabeled and a small number of labeled images, outperformed supervised CNNs trained with the same number of images and CNNs pre-trained on unlabeled data. In ablation experiments, we observed that the proposed attention mechanism substantially improves segmentation performance. We explore two multi-task training strategies: joint training and alternating training. Alternating training requires fewer hyperparameters and achieves a better, more stable performance than joint training. Finally, we analyze the features learned by different methods and find that the attention mechanism helps to learn more discriminative features in the deeper layers of encoders.
Weakly Supervised Object Detection with 2D and 3D Regression Neural Networks
Jun 14, 2019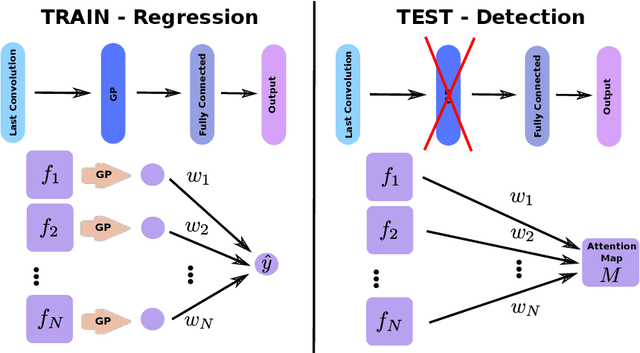

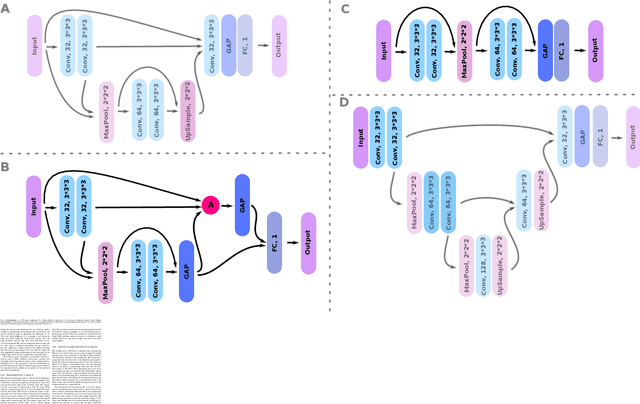

Weakly supervised detection methods can infer the location of target objects in an image without requiring location or appearance information during training. We propose a weakly supervised deep learning method for the detection of objects that appear at multiple locations in an image. The method computes attention maps using the last feature maps of an encoder-decoder network optimized only with global labels: the number of occurrences of the target object in an image. In contrast with previous approaches, attention maps are generated at full input resolution thanks to the decoder part. The proposed approach is compared to multiple state-of-the-art methods in two tasks: the detection of digits in MNIST-based datasets, and the real life application of detection of enlarged perivascular spaces -- a type of brain lesion -- in four brain regions in a dataset of 2202 3D brain MRI scans. In MNIST-based datasets, the proposed method outperforms the other methods. In the brain dataset, several weakly supervised detection methods come close to the human intrarater agreement in each region. The proposed method reaches the lowest number of false positive detections in all brain regions at the operating point, while its average sensitivity is similar to that of the other best methods.
3D Regression Neural Network for the Quantification of Enlarged Perivascular Spaces in Brain MRI
Oct 28, 2018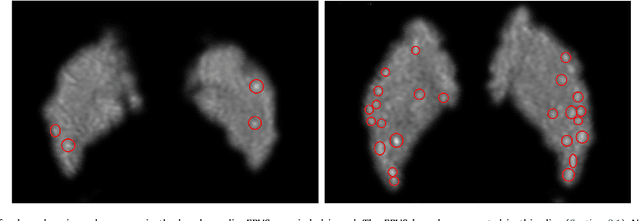
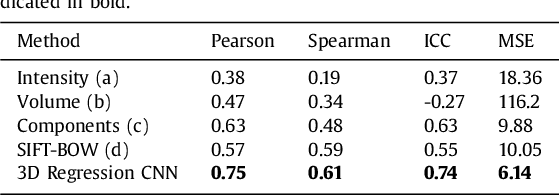
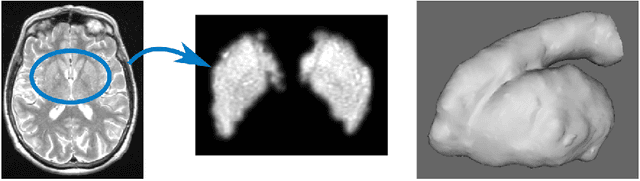
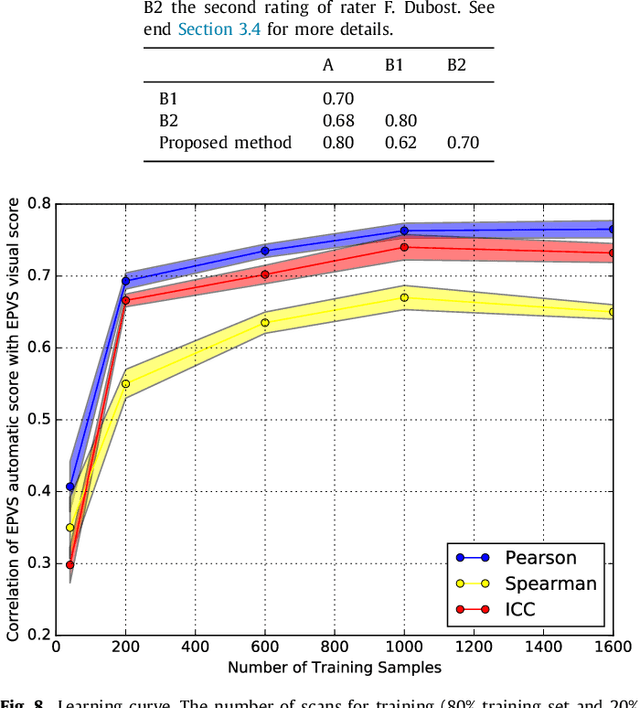
Enlarged perivascular spaces (EPVS) in the brain are an emerging imaging marker for cerebral small vessel disease, and have been shown to be related to increased risk of various neurological diseases, including stroke and dementia. Automatic quantification of EPVS would greatly help to advance research into its etiology and its potential as a risk indicator of disease. We propose a convolutional network regression method to quantify the extent of EPVS in the basal ganglia from 3D brain MRI. We first segment the basal ganglia and subsequently apply a 3D convolutional regression network designed for small object detection within this region of interest. The network takes an image as input, and outputs a quantification score of EPVS. The network has significantly more convolution operations than pooling ones and no final activation, allowing it to span the space of real numbers. We validated our approach using a dataset of 2000 brain MRI scans scored visually. Experiments with varying sizes of training and test sets showed that a good performance can be achieved with a training set of only 200 scans. With a training set of 1000 scans, the intraclass correlation coefficient (ICC) between our scoring method and the expert's visual score was 0.74. Our method outperforms by a large margin - more than 0.10 - four more conventional automated approaches based on intensities, scale-invariant feature transform, and random forest. We show that the network learns the structures of interest and investigate the influence of hyper-parameters on the performance. We also evaluate the reproducibility of our network using a set of 60 subjects scanned twice (scan-rescan reproducibility). On this set our network achieves an ICC of 0.93, while the intrarater agreement reaches 0.80. Furthermore, the automatic EPVS scoring correlates similarly to age as visual scoring.
Deep Learning from Label Proportions for Emphysema Quantification
Jul 23, 2018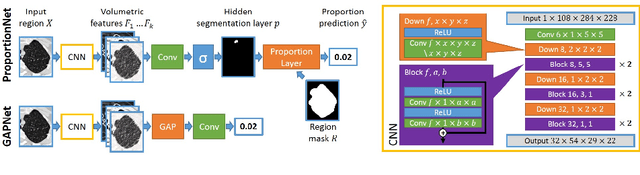
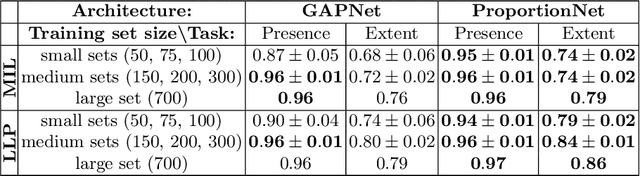
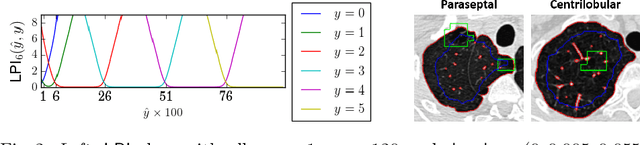
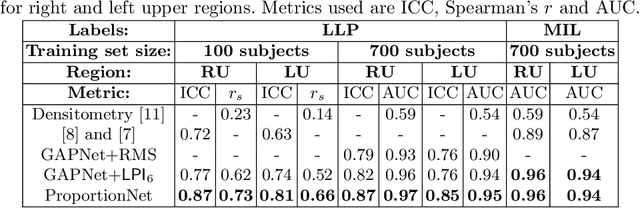
We propose an end-to-end deep learning method that learns to estimate emphysema extent from proportions of the diseased tissue. These proportions were visually estimated by experts using a standard grading system, in which grades correspond to intervals (label example: 1-5% of diseased tissue). The proposed architecture encodes the knowledge that the labels represent a volumetric proportion. A custom loss is designed to learn with intervals. Thus, during training, our network learns to segment the diseased tissue such that its proportions fit the ground truth intervals. Our architecture and loss combined improve the performance substantially (8% ICC) compared to a more conventional regression network. We outperform traditional lung densitometry and two recently published methods for emphysema quantification by a large margin (at least 7% AUC and 15% ICC), and achieve near-human-level performance. Moreover, our method generates emphysema segmentations that predict the spatial distribution of emphysema at human level.