 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021
Aug 15, 2022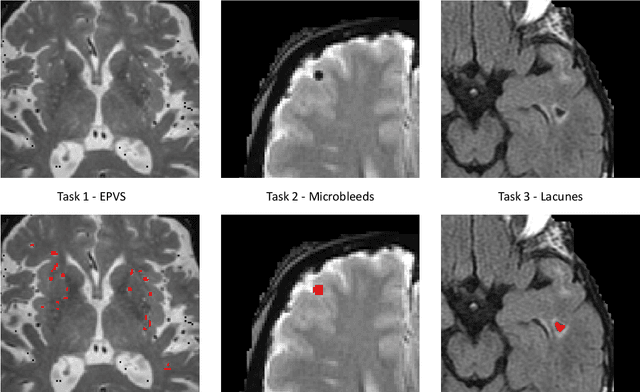
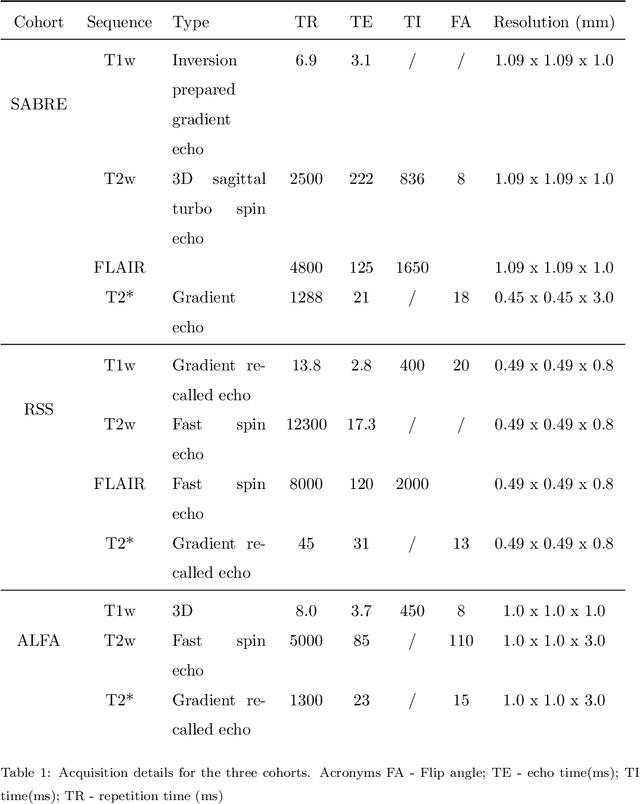
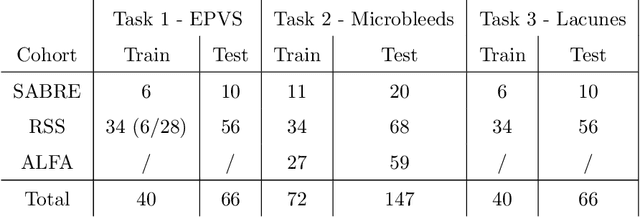
Imaging markers of cerebral small vessel disease provide valuable information on brain health, but their manual assessment is time-consuming and hampered by substantial intra- and interrater variability. Automated rating may benefit biomedical research, as well as clinical assessment, but diagnostic reliability of existing algorithms is unknown. Here, we present the results of the \textit{VAscular Lesions DetectiOn and Segmentation} (\textit{Where is VALDO?}) challenge that was run as a satellite event at the international conference on Medical Image Computing and Computer Aided Intervention (MICCAI) 2021. This challenge aimed to promote the development of methods for automated detection and segmentation of small and sparse imaging markers of cerebral small vessel disease, namely enlarged perivascular spaces (EPVS) (Task 1), cerebral microbleeds (Task 2) and lacunes of presumed vascular origin (Task 3) while leveraging weak and noisy labels. Overall, 12 teams participated in the challenge proposing solutions for one or more tasks (4 for Task 1 - EPVS, 9 for Task 2 - Microbleeds and 6 for Task 3 - Lacunes). Multi-cohort data was used in both training and evaluation. Results showed a large variability in performance both across teams and across tasks, with promising results notably for Task 1 - EPVS and Task 2 - Microbleeds and not practically useful results yet for Task 3 - Lacunes. It also highlighted the performance inconsistency across cases that may deter use at an individual level, while still proving useful at a population level.
Longitudinal diffusion MRI analysis using Segis-Net: a single-step deep-learning framework for simultaneous segmentation and registration
Dec 28, 2020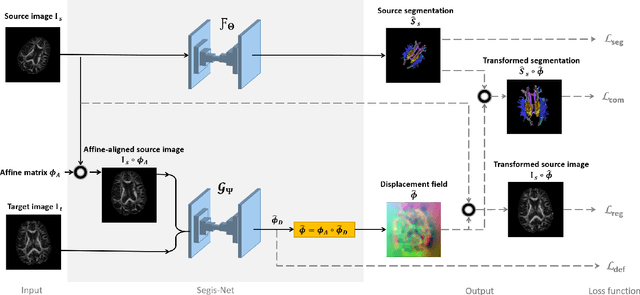
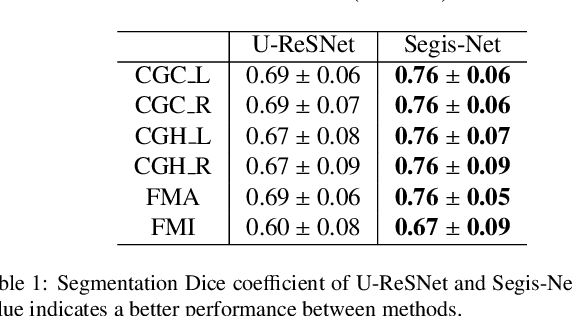
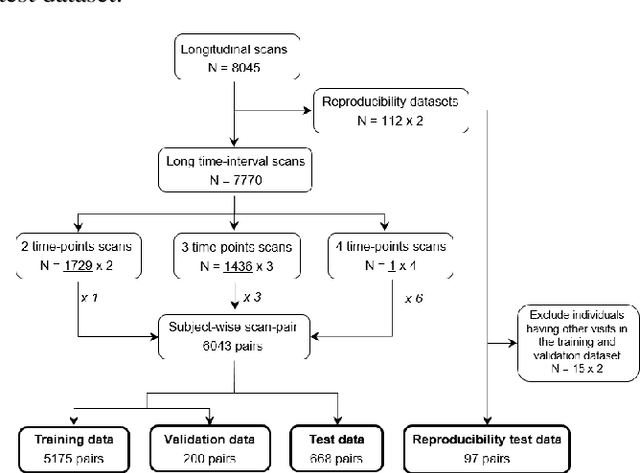
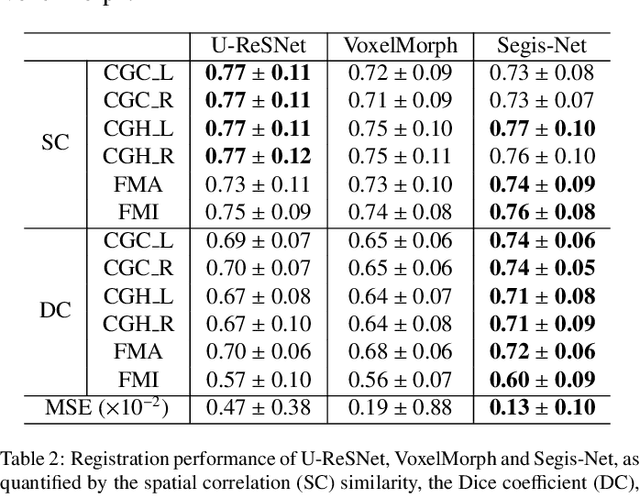
This work presents a single-step deep-learning framework for longitudinal image analysis, coined Segis-Net. To optimally exploit information available in longitudinal data, this method concurrently learns a multi-class segmentation and nonlinear registration. Segmentation and registration are modeled using a convolutional neural network and optimized simultaneously for their mutual benefit. An objective function that optimizes spatial correspondence for the segmented structures across time-points is proposed. We applied Segis-Net to the analysis of white matter tracts from N=8045 longitudinal brain MRI datasets of 3249 elderly individuals. Segis-Net approach showed a significant increase in registration accuracy, spatio-temporal segmentation consistency, and reproducibility comparing with two multistage pipelines. This also led to a significant reduction in the sample-size that would be required to achieve the same statistical power in analyzing tract-specific measures. Thus, we expect that Segis-Net can serve as a new reliable tool to support longitudinal imaging studies to investigate macro- and microstructural brain changes over time.
Learning unbiased registration and joint segmentation: evaluation on longitudinal diffusion MRI
Nov 03, 2020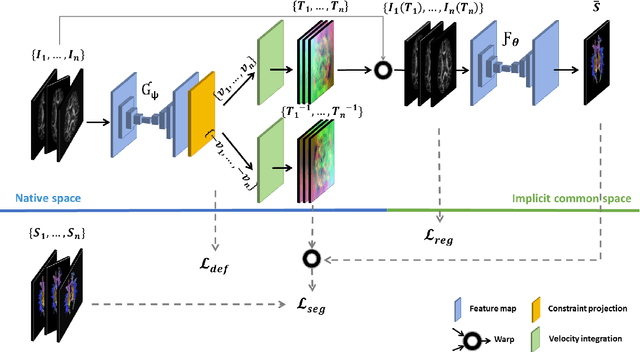
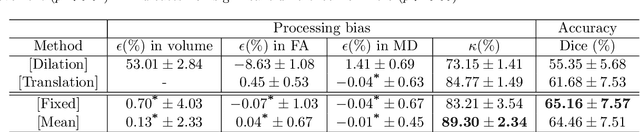
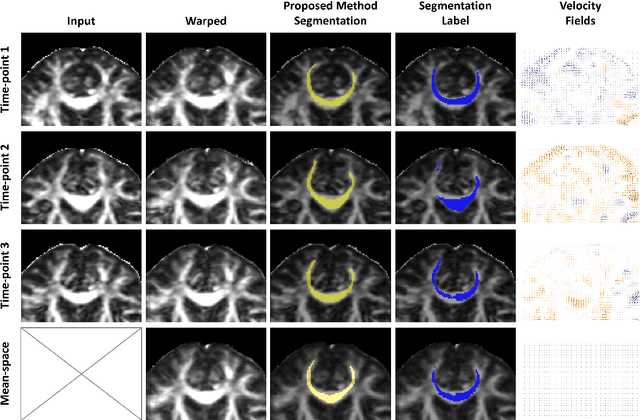
Analysis of longitudinal changes in imaging studies often involves both segmentation of structures of interest and registration of multiple timeframes. The accuracy of such analysis could benefit from a tailored framework that jointly optimizes both tasks to fully exploit the information available in the longitudinal data. Most learning-based registration algorithms, including joint optimization approaches, currently suffer from bias due to selection of a fixed reference frame and only support pairwise transformations. We here propose an analytical framework based on an unbiased learning strategy for group-wise registration that simultaneously registers images to the mean space of a group to obtain consistent segmentations. We evaluate the proposed method on longitudinal analysis of a white matter tract in a brain MRI dataset with 2-3 time-points for 3249 individuals, i.e., 8045 images in total. The reproducibility of the method is evaluated on test-retest data from 97 individuals. The results confirm that the implicit reference image is an average of the input image. In addition, the proposed framework leads to consistent segmentations and significantly lower processing bias than that of a pair-wise fixed-reference approach. This processing bias is even smaller than those obtained when translating segmentations by only one voxel, which can be attributed to subtle numerical instabilities and interpolation. Therefore, we postulate that the proposed mean-space learning strategy could be widely applied to learning-based registration tasks. In addition, this group-wise framework introduces a novel way for learning-based longitudinal studies by direct construction of an unbiased within-subject template and allowing reliable and efficient analysis of spatio-temporal imaging biomarkers.
Neuro4Neuro: A neural network approach for neural tract segmentation using large-scale population-based diffusion imaging
May 26, 2020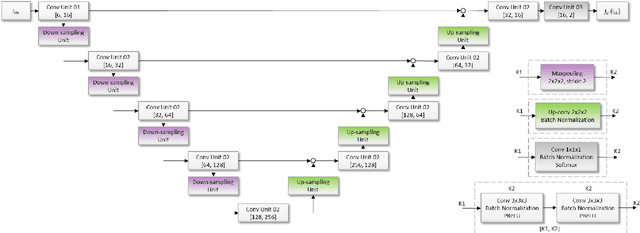
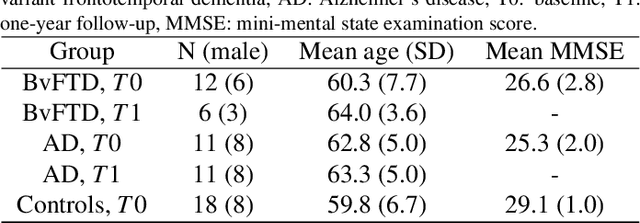
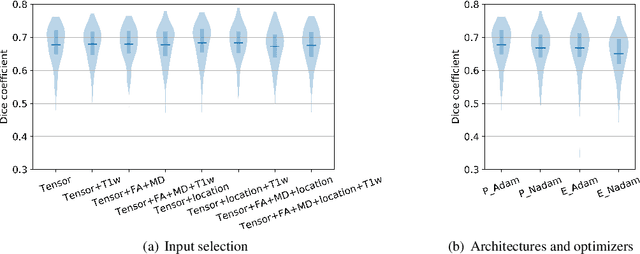
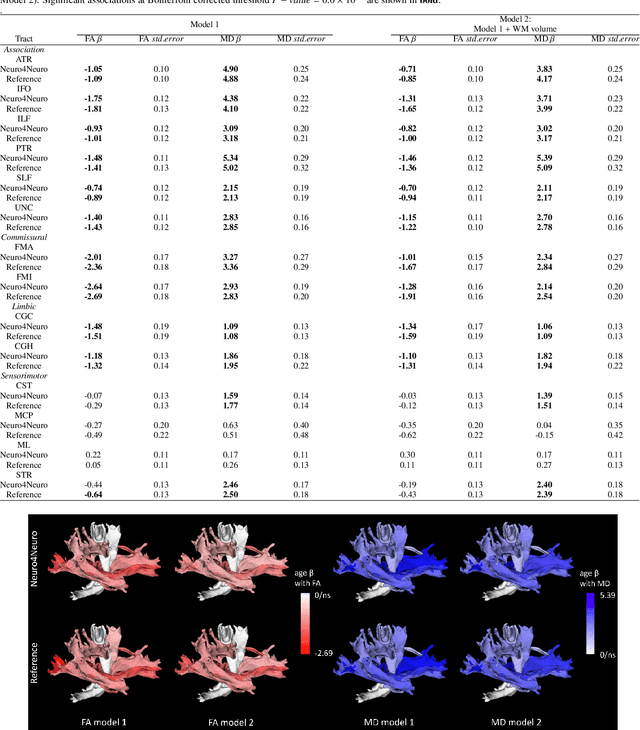
Subtle changes in white matter (WM) microstructure have been associated with normal aging and neurodegeneration. To study these associations in more detail, it is highly important that the WM tracts can be accurately and reproducibly characterized from brain diffusion MRI. In addition, to enable analysis of WM tracts in large datasets and in clinical practice it is essential to have methodology that is fast and easy to apply. This work therefore presents a new approach for WM tract segmentation: Neuro4Neuro, that is capable of direct extraction of WM tracts from diffusion tensor images using convolutional neural network (CNN). This 3D end-to-end method is trained to segment 25 WM tracts in aging individuals from a large population-based study (N=9752, 1.5T MRI). The proposed method showed good segmentation performance and high reproducibility, i.e., a high spatial agreement (Cohen's kappa, k = 0.72 ~ 0.83) and a low scan-rescan error in tract-specific diffusion measures (e.g., fractional anisotropy: error = 1% ~ 5%). The reproducibility of the proposed method was higher than that of a tractography-based segmentation algorithm, while being orders of magnitude faster (0.5s to segment one tract). In addition, we showed that the method successfully generalizes to diffusion scans from an external dementia dataset (N=58, 3T MRI). In two proof-of-principle experiments, we associated WM microstructure obtained using the proposed method with age in a normal elderly population, and with disease subtypes in a dementia cohort. In concordance with the literature, results showed a widespread reduction of microstructural organization with aging and substantial group-wise microstructure differences between dementia subtypes. In conclusion, we presented a highly reproducible and fast method for WM tract segmentation that has the potential of being used in large-scale studies and clinical practice.
Automated Lesion Detection by Regressing Intensity-Based Distance with a Neural Network
Jul 29, 2019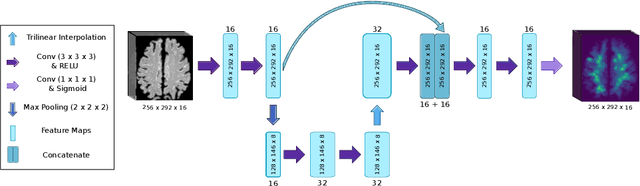

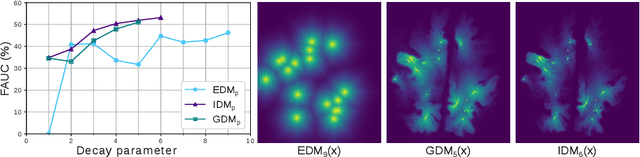
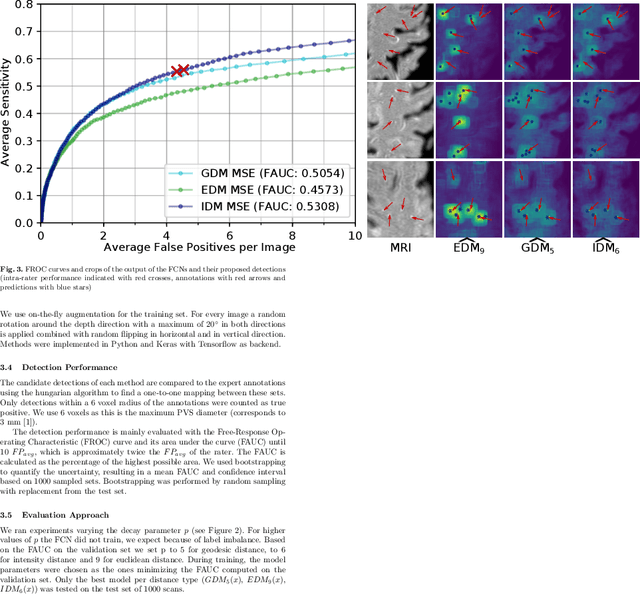
Localization of focal vascular lesions on brain MRI is an important component of research on the etiology of neurological disorders. However, manual annotation of lesions can be challenging, time-consuming and subject to observer bias. Automated detection methods often need voxel-wise annotations for training. We propose a novel approach for automated lesion detection that can be trained on scans only annotated with a dot per lesion instead of a full segmentation. From the dot annotations and their corresponding intensity images we compute various distance maps (DMs), indicating the distance to a lesion based on spatial distance, intensity distance, or both. We train a fully convolutional neural network (FCN) to predict these DMs for unseen intensity images. The local optima in the predicted DMs are expected to correspond to lesion locations. We show the potential of this approach to detect enlarged perivascular spaces in white matter on a large brain MRI dataset with an independent test set of 1000 scans. Our method matches the intra-rater performance of the expert rater that was computed on an independent set. We compare the different types of distance maps, showing that incorporating intensity information in the distance maps used to train an FCN greatly improves performance.
Weakly Supervised Object Detection with 2D and 3D Regression Neural Networks
Jun 14, 2019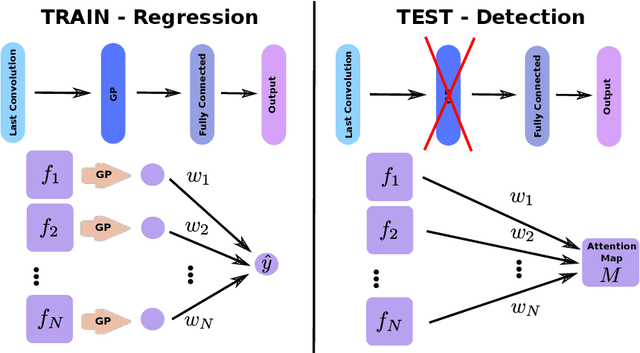

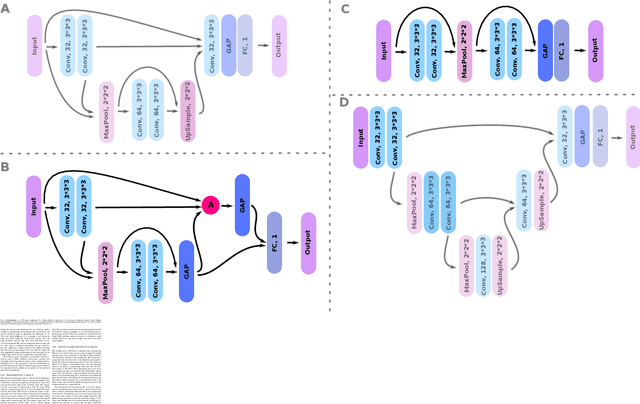

Weakly supervised detection methods can infer the location of target objects in an image without requiring location or appearance information during training. We propose a weakly supervised deep learning method for the detection of objects that appear at multiple locations in an image. The method computes attention maps using the last feature maps of an encoder-decoder network optimized only with global labels: the number of occurrences of the target object in an image. In contrast with previous approaches, attention maps are generated at full input resolution thanks to the decoder part. The proposed approach is compared to multiple state-of-the-art methods in two tasks: the detection of digits in MNIST-based datasets, and the real life application of detection of enlarged perivascular spaces -- a type of brain lesion -- in four brain regions in a dataset of 2202 3D brain MRI scans. In MNIST-based datasets, the proposed method outperforms the other methods. In the brain dataset, several weakly supervised detection methods come close to the human intrarater agreement in each region. The proposed method reaches the lowest number of false positive detections in all brain regions at the operating point, while its average sensitivity is similar to that of the other best methods.
3D Regression Neural Network for the Quantification of Enlarged Perivascular Spaces in Brain MRI
Oct 28, 2018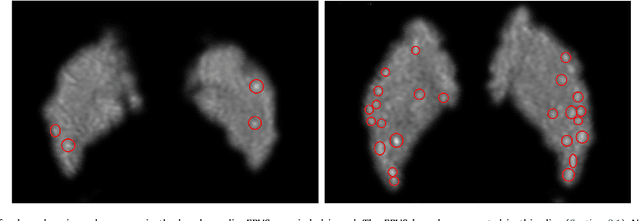
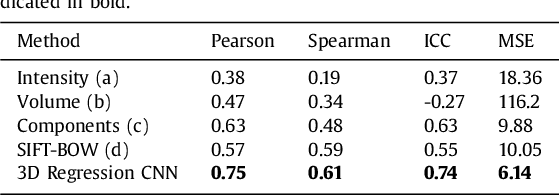
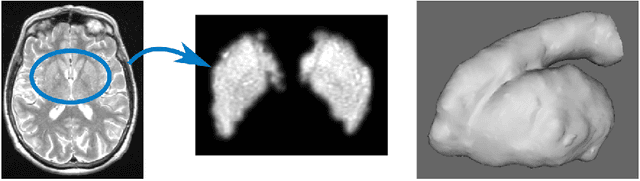
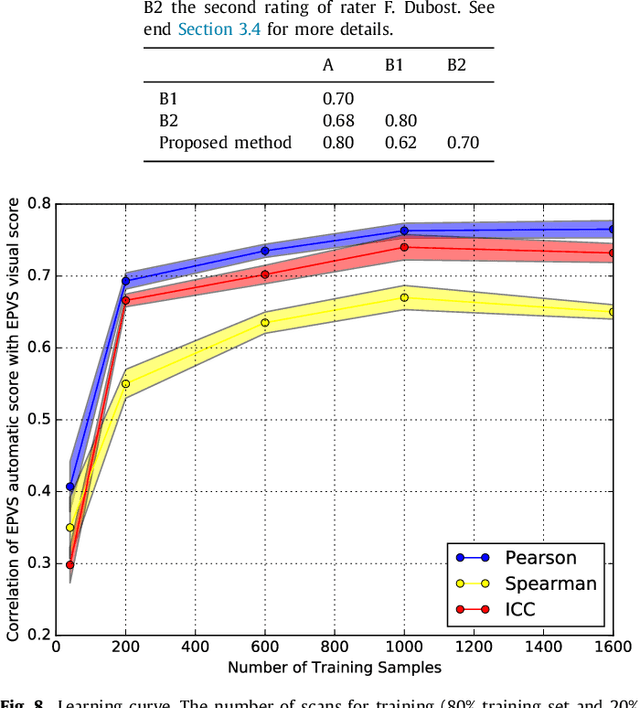
Enlarged perivascular spaces (EPVS) in the brain are an emerging imaging marker for cerebral small vessel disease, and have been shown to be related to increased risk of various neurological diseases, including stroke and dementia. Automatic quantification of EPVS would greatly help to advance research into its etiology and its potential as a risk indicator of disease. We propose a convolutional network regression method to quantify the extent of EPVS in the basal ganglia from 3D brain MRI. We first segment the basal ganglia and subsequently apply a 3D convolutional regression network designed for small object detection within this region of interest. The network takes an image as input, and outputs a quantification score of EPVS. The network has significantly more convolution operations than pooling ones and no final activation, allowing it to span the space of real numbers. We validated our approach using a dataset of 2000 brain MRI scans scored visually. Experiments with varying sizes of training and test sets showed that a good performance can be achieved with a training set of only 200 scans. With a training set of 1000 scans, the intraclass correlation coefficient (ICC) between our scoring method and the expert's visual score was 0.74. Our method outperforms by a large margin - more than 0.10 - four more conventional automated approaches based on intensities, scale-invariant feature transform, and random forest. We show that the network learns the structures of interest and investigate the influence of hyper-parameters on the performance. We also evaluate the reproducibility of our network using a set of 60 subjects scanned twice (scan-rescan reproducibility). On this set our network achieves an ICC of 0.93, while the intrarater agreement reaches 0.80. Furthermore, the automatic EPVS scoring correlates similarly to age as visual scoring.
Hydranet: Data Augmentation for Regression Neural Networks
Jul 12, 2018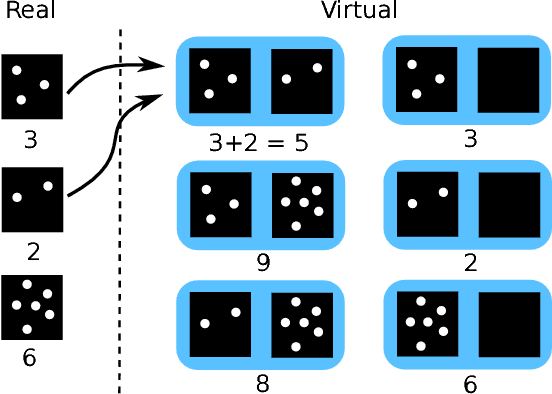
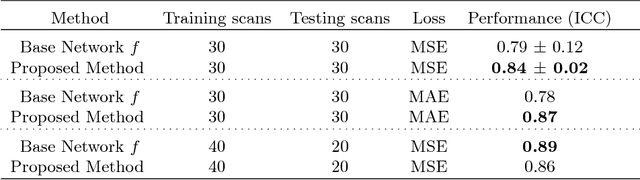
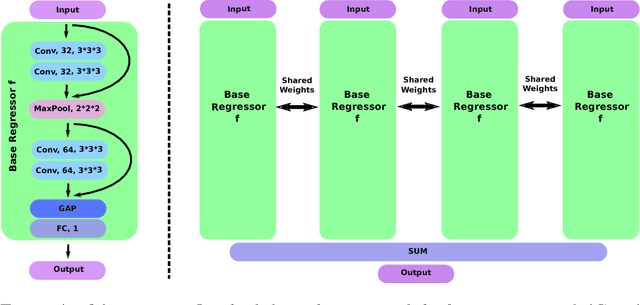
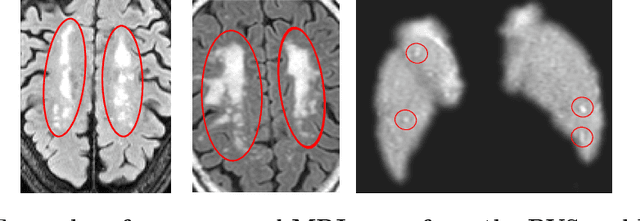
Despite recent efforts, deep learning techniques remain often heavily dependent on a large quantity of labeled data. This problem is even more challenging in medical image analysis where the annotator expertise is often scarce. In this paper we propose a novel data-augmentation method to regularize neural network regressors, learning from a single global label per image. The principle of the method is to create new samples by recombining existing ones. We demonstrate the performance of our algorithm on two tasks: the regression of number of enlarged perivascular spaces in the basal ganglia; and the regression of white matter hyperintensities volume. We show that the proposed method improves the performance even when more basic data augmentation is used. Furthermore we reached an intraclass correlation coefficient between ground truth and network predictions of 0.73 on the first task and 0.86 on the second task, only using between 25 and 30 scans with a single global label per scan for training. To achieve a similar correlation on the first task, state-of-the-art methods needed more than 1000 training scans.
Transfer Learning by Asymmetric Image Weighting for Segmentation across Scanners
Mar 15, 2017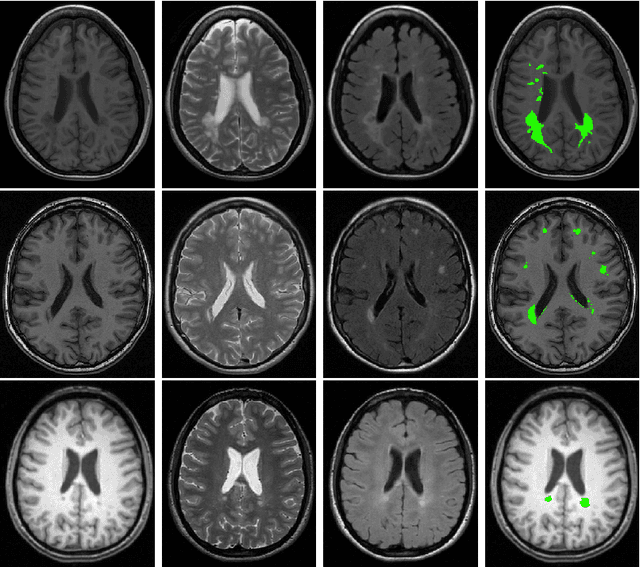
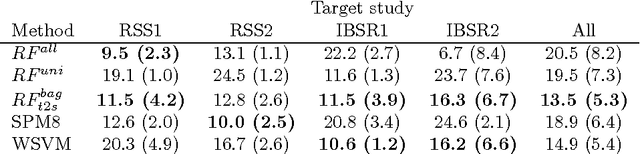
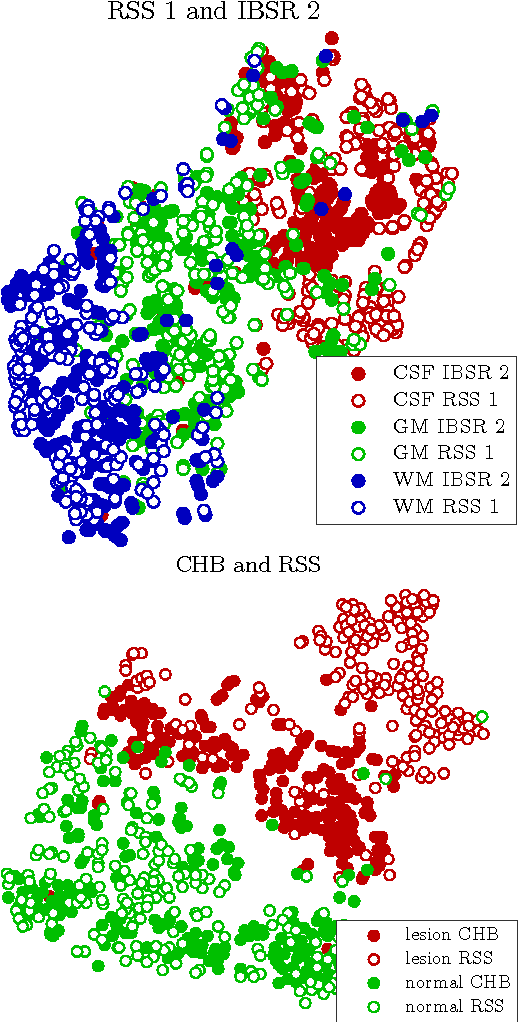
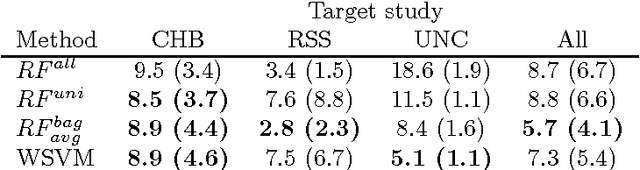
Supervised learning has been very successful for automatic segmentation of images from a single scanner. However, several papers report deteriorated performances when using classifiers trained on images from one scanner to segment images from other scanners. We propose a transfer learning classifier that adapts to differences between training and test images. This method uses a weighted ensemble of classifiers trained on individual images. The weight of each classifier is determined by the similarity between its training image and the test image. We examine three unsupervised similarity measures, which can be used in scenarios where no labeled data from a newly introduced scanner or scanning protocol is available. The measures are based on a divergence, a bag distance, and on estimating the labels with a clustering procedure. These measures are asymmetric. We study whether the asymmetry can improve classification. Out of the three similarity measures, the bag similarity measure is the most robust across different studies and achieves excellent results on four brain tissue segmentation datasets and three white matter lesion segmentation datasets, acquired at different centers and with different scanners and scanning protocols. We show that the asymmetry can indeed be informative, and that computing the similarity from the test image to the training images is more appropriate than the opposite direction.