 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA joint 3D UNet-Graph Neural Network-based method for Airway Segmentation from chest CTs
Aug 22, 2019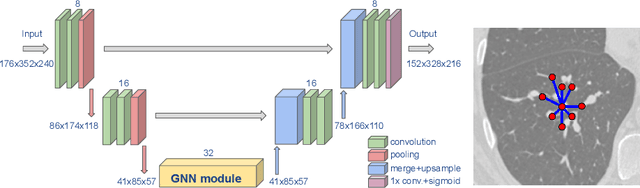


We present an end-to-end deep learning segmentation method by combining a 3D UNet architecture with a graph neural network (GNN) model. In this approach, the convolutional layers at the deepest level of the UNet are replaced by a GNN-based module with a series of graph convolutions. The dense feature maps at this level are transformed into a graph input to the GNN module. The incorporation of graph convolutions in the UNet provides nodes in the graph with information that is based on node connectivity, in addition to the local features learnt through the downsampled paths. This information can help improve segmentation decisions. By stacking several graph convolution layers, the nodes can access higher order neighbourhood information without substantial increase in computational expense. We propose two types of node connectivity in the graph adjacency: i) one predefined and based on a regular node neighbourhood, and ii) one dynamically computed during training and using the nearest neighbour nodes in the feature space. We have applied this method to the task of segmenting the airway tree from chest CT scans. Experiments have been performed on 32 CTs from the Danish Lung Cancer Screening Trial dataset. We evaluate the performance of the UNet-GNN models with two types of graph adjacency and compare it with the baseline UNet.
Multi-Task Attention-Based Semi-Supervised Learning for Medical Image Segmentation
Jul 29, 2019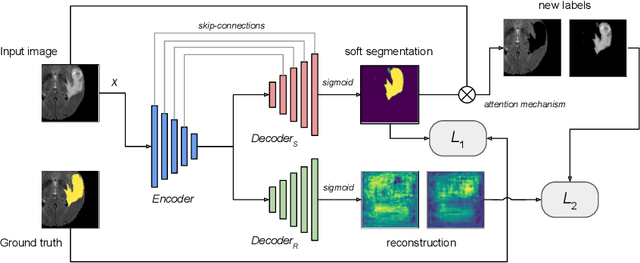
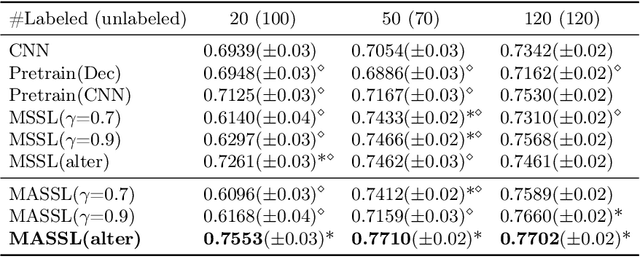
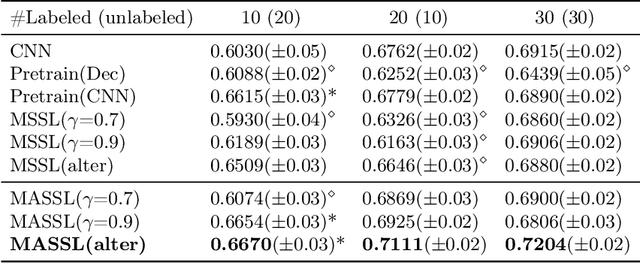
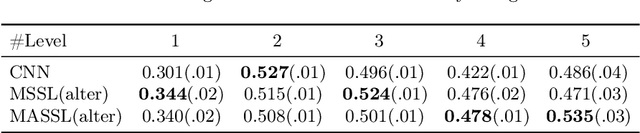
We propose a novel semi-supervised image segmentation method that simultaneously optimizes a supervised segmentation and an unsupervised reconstruction objectives. The reconstruction objective uses an attention mechanism that separates the reconstruction of image areas corresponding to different classes. The proposed approach was evaluated on two applications: brain tumor and white matter hyperintensities segmentation. Our method, trained on unlabeled and a small number of labeled images, outperformed supervised CNNs trained with the same number of images and CNNs pre-trained on unlabeled data. In ablation experiments, we observed that the proposed attention mechanism substantially improves segmentation performance. We explore two multi-task training strategies: joint training and alternating training. Alternating training requires fewer hyperparameters and achieves a better, more stable performance than joint training. Finally, we analyze the features learned by different methods and find that the attention mechanism helps to learn more discriminative features in the deeper layers of encoders.