 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised classification of simulated magnetospheric regions
Sep 10, 2021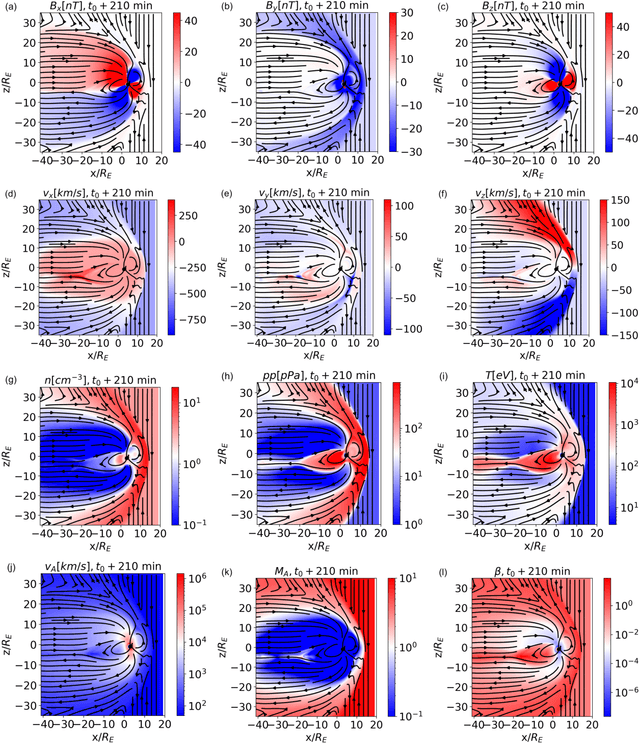

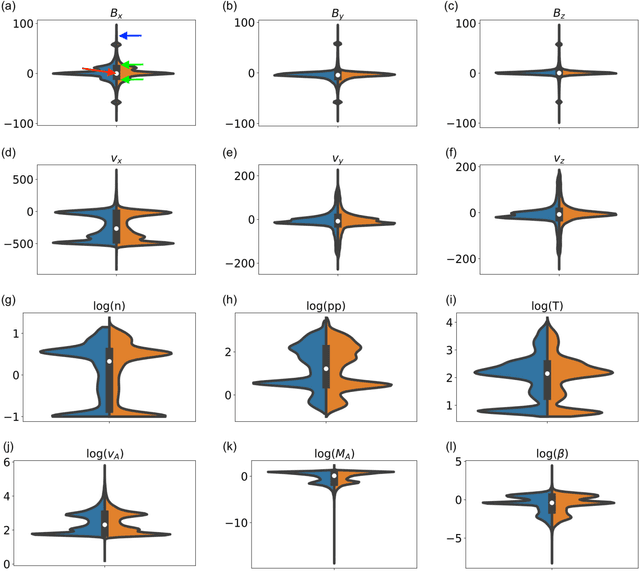
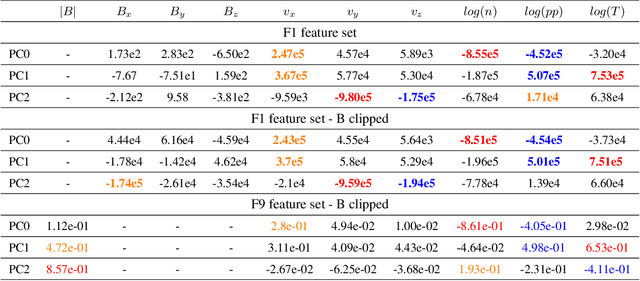
In magnetospheric missions, burst mode data sampling should be triggered in the presence of processes of scientific or operational interest. We present an unsupervised classification method for magnetospheric regions, that could constitute the first-step of a multi-step method for the automatic identification of magnetospheric processes of interest. Our method is based on Self Organizing Maps (SOMs), and we test it preliminarily on data points from global magnetospheric simulations obtained with the OpenGGCM-CTIM-RCM code. The dimensionality of the data is reduced with Principal Component Analysis before classification. The classification relies exclusively on local plasma properties at the selected data points, without information on their neighborhood or on their temporal evolution. We classify the SOM nodes into an automatically selected number of classes, and we obtain clusters that map to well defined magnetospheric regions. We validate our classification results by plotting the classified data in the simulated space and by comparing with K-means classification. For the sake of result interpretability, we examine the SOM feature maps (magnetospheric variables are called features in the context of classification), and we use them to unlock information on the clusters. We repeat the classification experiments using different sets of features, we quantitatively compare different classification results, and we obtain insights on which magnetospheric variables make more effective features for unsupervised classification.
A Framework using Contrastive Learning for Classification with Noisy Labels
Apr 19, 2021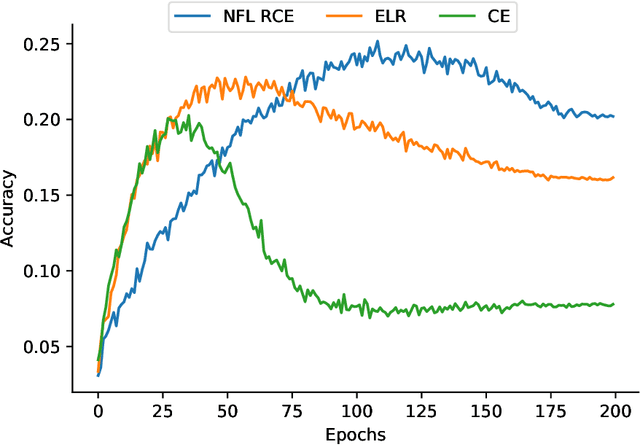
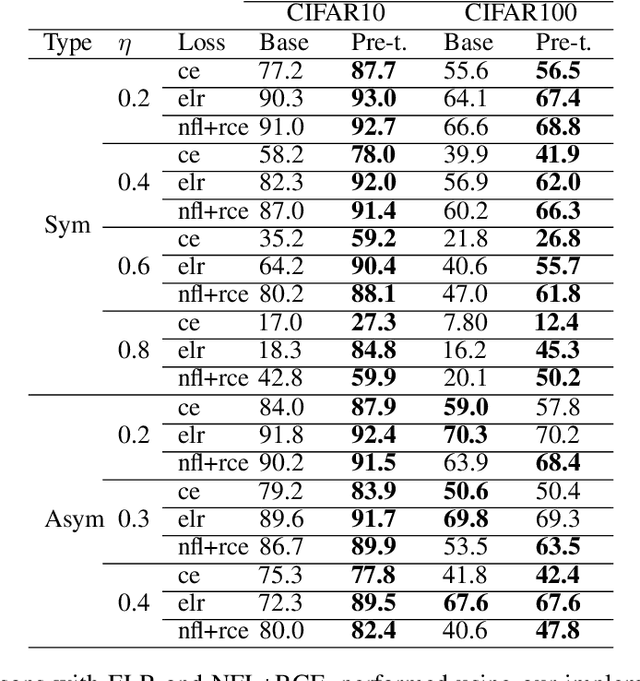
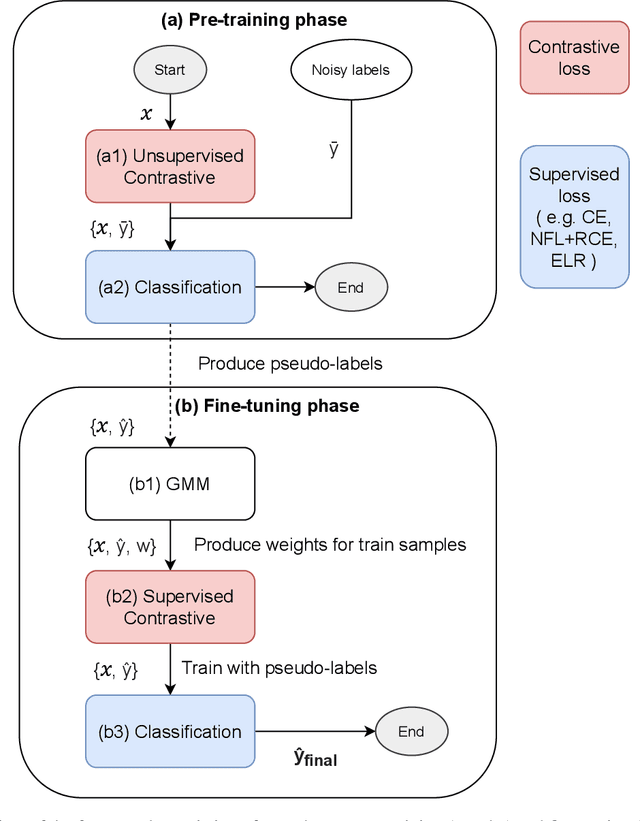
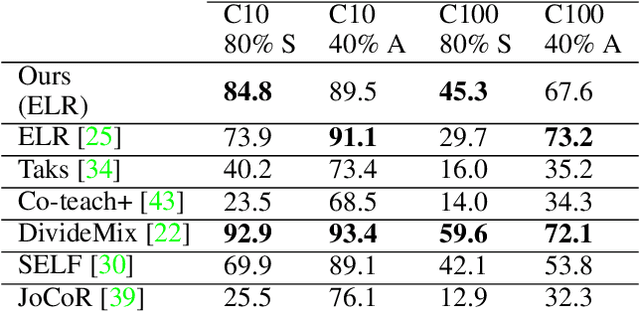
We propose a framework using contrastive learning as a pre-training task to perform image classification in the presence of noisy labels. Recent strategies such as pseudo-labeling, sample selection with Gaussian Mixture models, weighted supervised contrastive learning have been combined into a fine-tuning phase following the pre-training. This paper provides an extensive empirical study showing that a preliminary contrastive learning step brings a significant gain in performance when using different loss functions: non-robust, robust, and early-learning regularized. Our experiments performed on standard benchmarks and real-world datasets demonstrate that: i) the contrastive pre-training increases the robustness of any loss function to noisy labels and ii) the additional fine-tuning phase can further improve accuracy but at the cost of additional complexity.