 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Computational Trade-Off of Inexact Proximal Methods
Oct 21, 2012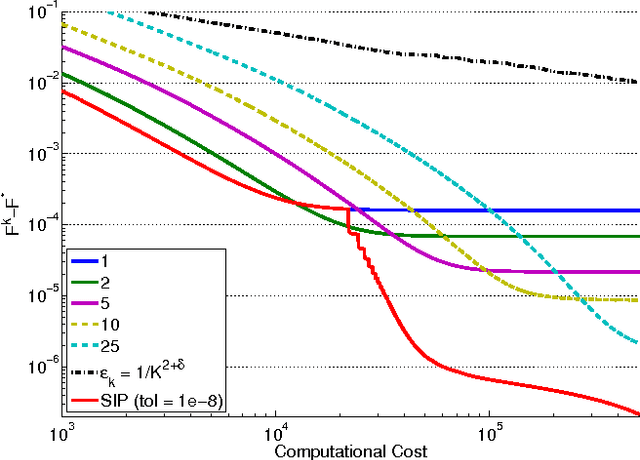
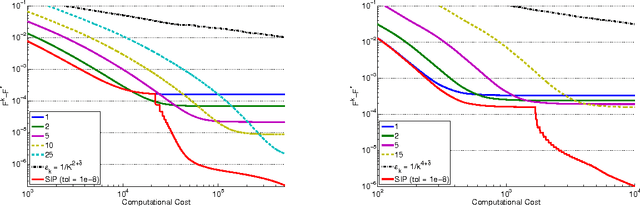
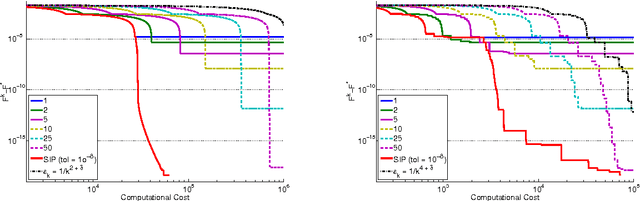
In this paper, we investigate the trade-off between convergence rate and computational cost when minimizing a composite functional with proximal-gradient methods, which are popular optimisation tools in machine learning. We consider the case when the proximity operator is computed via an iterative procedure, which provides an approximation of the exact proximity operator. In that case, we obtain algorithms with two nested loops. We show that the strategy that minimizes the computational cost to reach a solution with a desired accuracy in finite time is to set the number of inner iterations to a constant, which differs from the strategy indicated by a convergence rate analysis. In the process, we also present a new procedure called SIP (that is Speedy Inexact Proximal-gradient algorithm) that is both computationally efficient and easy to implement. Our numerical experiments confirm the theoretical findings and suggest that SIP can be a very competitive alternative to the standard procedure.
Confusion Matrix Stability Bounds for Multiclass Classification
May 24, 2012In this paper, we provide new theoretical results on the generalization properties of learning algorithms for multiclass classification problems. The originality of our work is that we propose to use the confusion matrix of a classifier as a measure of its quality; our contribution is in the line of work which attempts to set up and study the statistical properties of new evaluation measures such as, e.g. ROC curves. In the confusion-based learning framework we propose, we claim that a targetted objective is to minimize the size of the confusion matrix C, measured through its operator norm ||C||. We derive generalization bounds on the (size of the) confusion matrix in an extended framework of uniform stability, adapted to the case of matrix valued loss. Pivotal to our study is a very recent matrix concentration inequality that generalizes McDiarmid's inequality. As an illustration of the relevance of our theoretical results, we show how two SVM learning procedures can be proved to be confusion-friendly. To the best of our knowledge, the present paper is the first that focuses on the confusion matrix from a theoretical point of view.
Stochastic Low-Rank Kernel Learning for Regression
Jan 11, 2012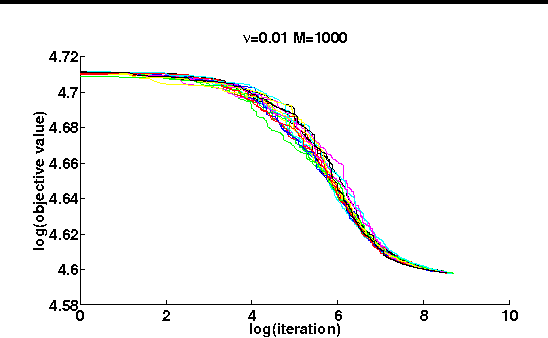
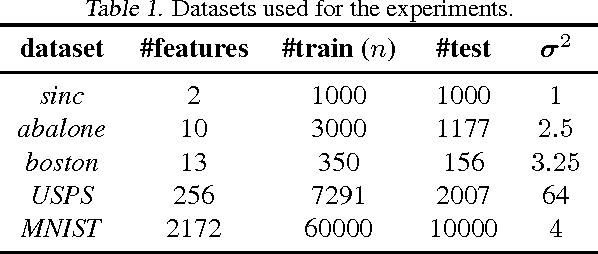
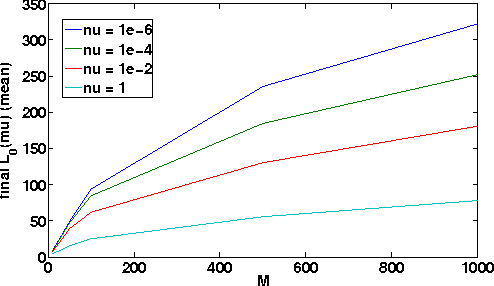
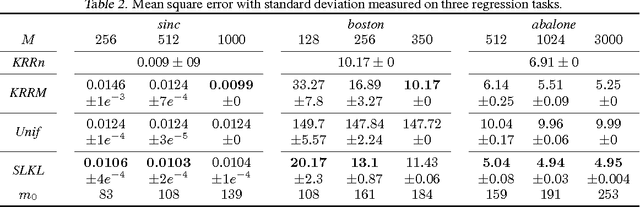
We present a novel approach to learn a kernel-based regression function. It is based on the useof conical combinations of data-based parameterized kernels and on a new stochastic convex optimization procedure of which we establish convergence guarantees. The overall learning procedure has the nice properties that a) the learned conical combination is automatically designed to perform the regression task at hand and b) the updates implicated by the optimization procedure are quite inexpensive. In order to shed light on the appositeness of our learning strategy, we present empirical results from experiments conducted on various benchmark datasets.