 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssemblage: Automatic Binary Dataset Construction for Machine Learning
May 07, 2024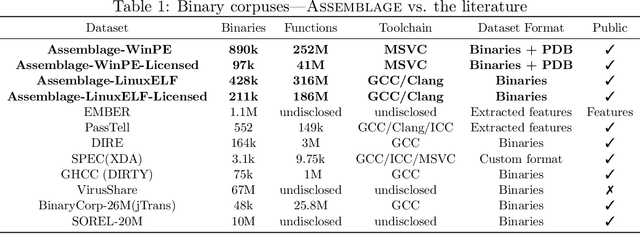
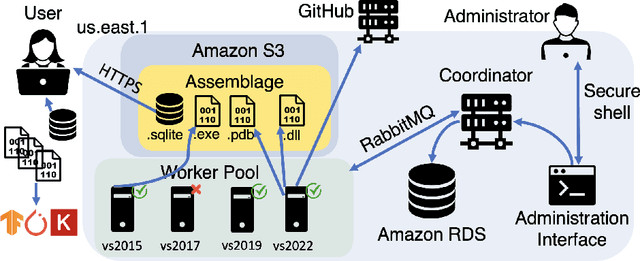

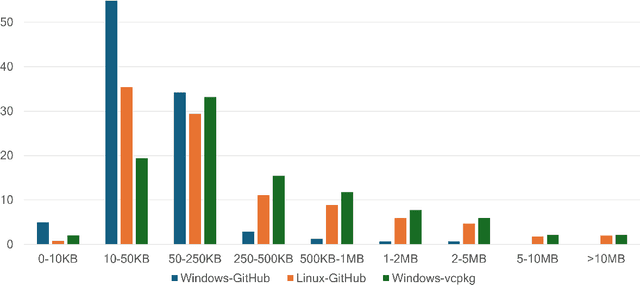
Binary code is pervasive, and binary analysis is a key task in reverse engineering, malware classification, and vulnerability discovery. Unfortunately, while there exist large corpuses of malicious binaries, obtaining high-quality corpuses of benign binaries for modern systems has proven challenging (e.g., due to licensing issues). Consequently, machine learning based pipelines for binary analysis utilize either costly commercial corpuses (e.g., VirusTotal) or open-source binaries (e.g., coreutils) available in limited quantities. To address these issues, we present Assemblage: an extensible cloud-based distributed system that crawls, configures, and builds Windows PE binaries to obtain high-quality binary corpuses suitable for training state-of-the-art models in binary analysis. We have run Assemblage on AWS over the past year, producing 890k Windows PE and 428k Linux ELF binaries across 29 configurations. Assemblage is designed to be both reproducible and extensible, enabling users to publish "recipes" for their datasets, and facilitating the extraction of a wide array of features. We evaluated Assemblage by using its data to train modern learning-based pipelines for compiler provenance and binary function similarity. Our results illustrate the practical need for robust corpuses of high-quality Windows PE binaries in training modern learning-based binary analyses. Assemblage can be downloaded from https://assemblage-dataset.net
Probing the Transition to Dataset-Level Privacy in ML Models Using an Output-Specific and Data-Resolved Privacy Profile
Jun 27, 2023Differential privacy (DP) is the prevailing technique for protecting user data in machine learning models. However, deficits to this framework include a lack of clarity for selecting the privacy budget $\epsilon$ and a lack of quantification for the privacy leakage for a particular data row by a particular trained model. We make progress toward these limitations and a new perspective by which to visualize DP results by studying a privacy metric that quantifies the extent to which a model trained on a dataset using a DP mechanism is ``covered" by each of the distributions resulting from training on neighboring datasets. We connect this coverage metric to what has been established in the literature and use it to rank the privacy of individual samples from the training set in what we call a privacy profile. We additionally show that the privacy profile can be used to probe an observed transition to indistinguishability that takes place in the neighboring distributions as $\epsilon$ decreases, which we suggest is a tool that can enable the selection of $\epsilon$ by the ML practitioner wishing to make use of DP.
A General Framework for Auditing Differentially Private Machine Learning
Oct 16, 2022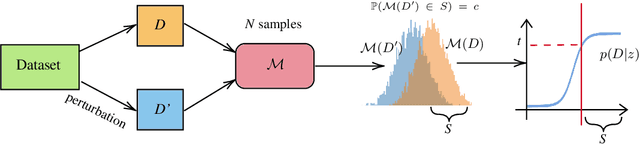

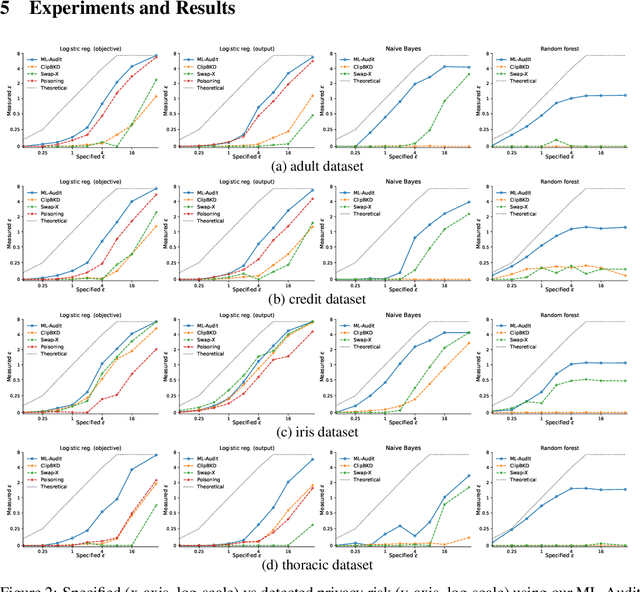
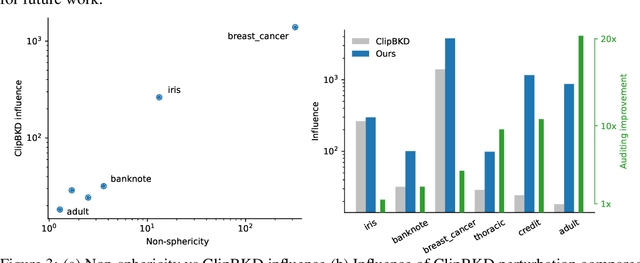
We present a framework to statistically audit the privacy guarantee conferred by a differentially private machine learner in practice. While previous works have taken steps toward evaluating privacy loss through poisoning attacks or membership inference, they have been tailored to specific models or have demonstrated low statistical power. Our work develops a general methodology to empirically evaluate the privacy of differentially private machine learning implementations, combining improved privacy search and verification methods with a toolkit of influence-based poisoning attacks. We demonstrate significantly improved auditing power over previous approaches on a variety of models including logistic regression, Naive Bayes, and random forest. Our method can be used to detect privacy violations due to implementation errors or misuse. When violations are not present, it can aid in understanding the amount of information that can be leaked from a given dataset, algorithm, and privacy specification.