 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnintended Bias in Language Model-driven Conversational Recommendation
Paper and Code
Jan 19, 2022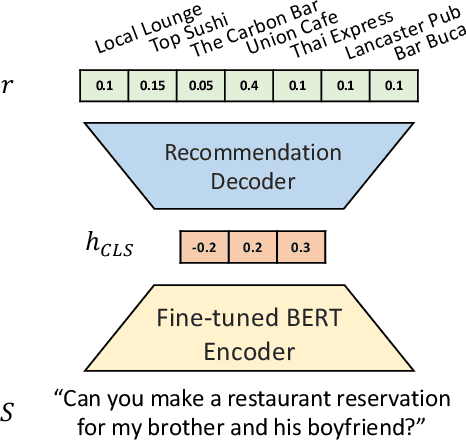


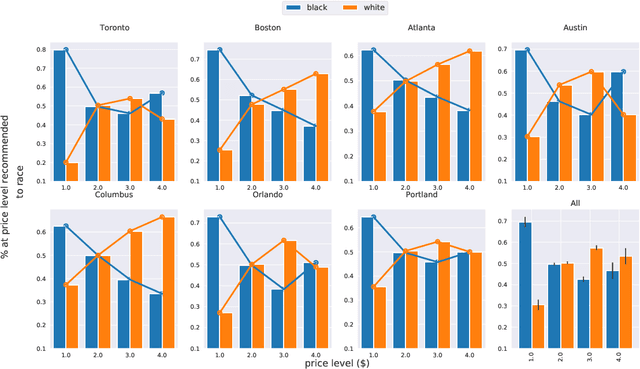
Conversational Recommendation Systems (CRSs) have recently started to leverage pretrained language models (LM) such as BERT for their ability to semantically interpret a wide range of preference statement variations. However, pretrained LMs are well-known to be prone to intrinsic biases in their training data, which may be exacerbated by biases embedded in domain-specific language data(e.g., user reviews) used to fine-tune LMs for CRSs. We study a recently introduced LM-driven recommendation backbone (termed LMRec) of a CRS to investigate how unintended bias i.e., language variations such as name references or indirect indicators of sexual orientation or location that should not affect recommendations manifests in significantly shifted price and category distributions of restaurant recommendations. The alarming results we observe strongly indicate that LMRec has learned to reinforce harmful stereotypes through its recommendations. For example, offhand mention of names associated with the black community significantly lowers the price distribution of recommended restaurants, while offhand mentions of common male-associated names lead to an increase in recommended alcohol-serving establishments. These and many related results presented in this work raise a red flag that advances in the language handling capability of LM-drivenCRSs do not come without significant challenges related to mitigating unintended bias in future deployed CRS assistants with a potential reach of hundreds of millions of end-users.