 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Hierarchical Anchoring for Audio-Visual Joint Representation: Resolving Information Allocation Ambiguity for Robust Cross-Modal Generalization
Feb 03, 2026Audio-visual joint representation learning under Cross-Modal Generalization (CMG) aims to transfer knowledge from a labeled source modality to an unlabeled target modality through a unified discrete representation space. Existing symmetric frameworks often suffer from information allocation ambiguity, where the absence of structural inductive bias leads to semantic-specific leakage across modalities. We propose Asymmetric Hierarchical Anchoring (AHA), which enforces directional information allocation by designating a structured semantic anchor within a shared hierarchy. In our instantiation, we exploit the hierarchical discrete representations induced by audio Residual Vector Quantization (RVQ) to guide video feature distillation into a shared semantic space. To ensure representational purity, we replace fragile mutual information estimators with a GRL-based adversarial decoupler that explicitly suppresses semantic leakage in modality-specific branches, and introduce Local Sliding Alignment (LSA) to encourage fine-grained temporal alignment across modalities. Extensive experiments on AVE and AVVP benchmarks demonstrate that AHA consistently outperforms symmetric baselines in cross-modal transfer. Additional analyses on talking-face disentanglement experiment further validate that the learned representations exhibit improved semantic consistency and disentanglement, indicating the broader applicability of the proposed framework.
Learning Explicit User Interest Boundary for Recommendation
Nov 22, 2021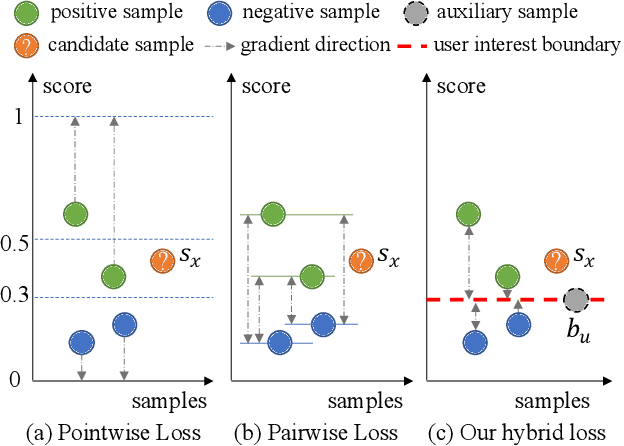

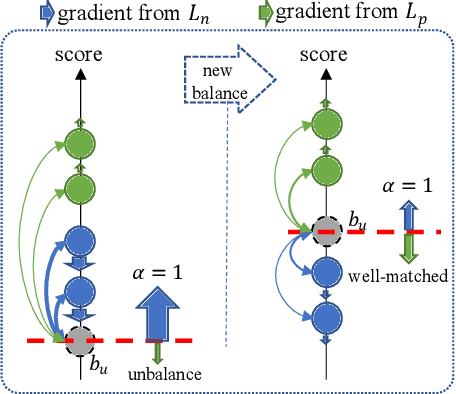

The core objective of modelling recommender systems from implicit feedback is to maximize the positive sample score $s_p$ and minimize the negative sample score $s_n$, which can usually be summarized into two paradigms: the pointwise and the pairwise. The pointwise approaches fit each sample with its label individually, which is flexible in weighting and sampling on instance-level but ignores the inherent ranking property. By qualitatively minimizing the relative score $s_n - s_p$, the pairwise approaches capture the ranking of samples naturally but suffer from training efficiency. Additionally, both approaches are hard to explicitly provide a personalized decision boundary to determine if users are interested in items unseen. To address those issues, we innovatively introduce an auxiliary score $b_u$ for each user to represent the User Interest Boundary(UIB) and individually penalize samples that cross the boundary with pairwise paradigms, i.e., the positive samples whose score is lower than $b_u$ and the negative samples whose score is higher than $b_u$. In this way, our approach successfully achieves a hybrid loss of the pointwise and the pairwise to combine the advantages of both. Analytically, we show that our approach can provide a personalized decision boundary and significantly improve the training efficiency without any special sampling strategy. Extensive results show that our approach achieves significant improvements on not only the classical pointwise or pairwise models but also state-of-the-art models with complex loss function and complicated feature encoding.