 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot 3D Shape Sketch View Similarity and Retrieval
Jun 14, 2023We conduct a detailed study of the ability of pretrained on pretext tasks ViT and ResNet feature layers to quantify the similarity between pairs of 2D sketch views of individual 3D shapes. We assess the performance in terms of the models' abilities to retrieve similar views and ground-truth 3D shapes. Going beyond naive zero-shot performance study, we investigate alternative fine-tuning strategies on one or several shape classes, and their generalization to other shape classes. Leveraging progress in NPR (Non-Photo Realistic) rendering, we generate synthetic sketch views in several styles which we use to fine-tune pretrained foundation models using contrastive learning. We study how the scale of an object in a sketch affects the similarity of features at different network layers. We observe that depending on the scale, different feature layers can be more indicative of shape similarities in sketch views. However, we find that similar object scales result in the best performance of ViT and ResNet. In summary, we show that careful selection of a fine-tuning strategy allows us to obtain consistent improvement in zero-shot shape retrieval accuracy. We believe that our work will have a significant impact on research in the sketch domain, providing insights and guidance on how to adopt large pretrained models as perceptual losses.
Learning the Space of Deep Models
Jun 10, 2022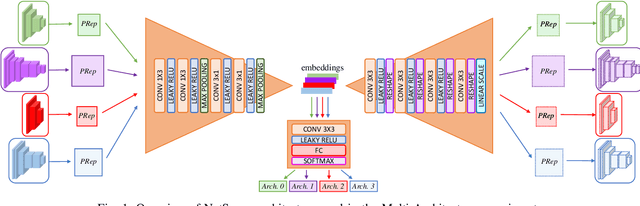
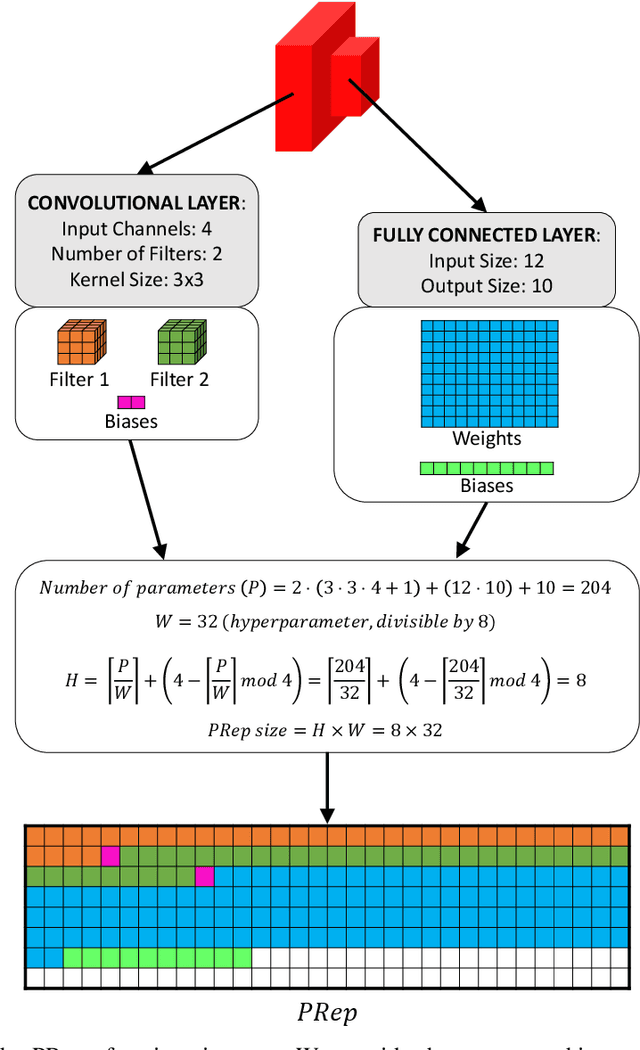
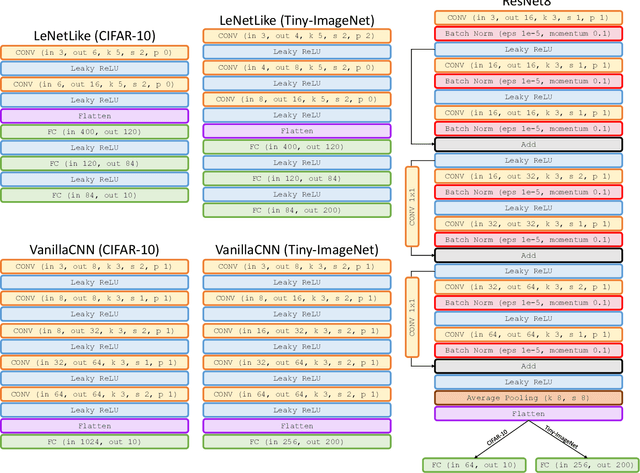
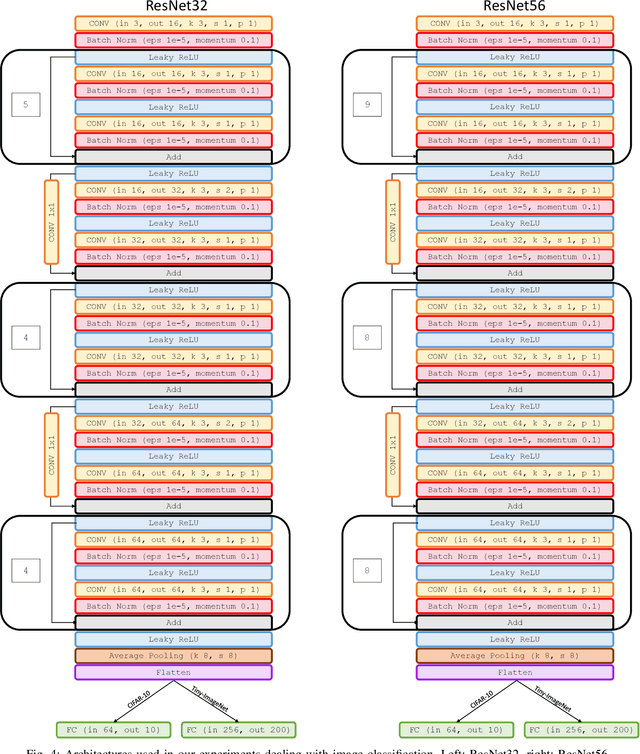
Embedding of large but redundant data, such as images or text, in a hierarchy of lower-dimensional spaces is one of the key features of representation learning approaches, which nowadays provide state-of-the-art solutions to problems once believed hard or impossible to solve. In this work, in a plot twist with a strong meta aftertaste, we show how trained deep models are as redundant as the data they are optimized to process, and how it is therefore possible to use deep learning models to embed deep learning models. In particular, we show that it is possible to use representation learning to learn a fixed-size, low-dimensional embedding space of trained deep models and that such space can be explored by interpolation or optimization to attain ready-to-use models. We find that it is possible to learn an embedding space of multiple instances of the same architecture and of multiple architectures. We address image classification and neural representation of signals, showing how our embedding space can be learnt so as to capture the notions of performance and 3D shape, respectively. In the Multi-Architecture setting we also show how an embedding trained only on a subset of architectures can learn to generate already-trained instances of architectures it never sees instantiated at training time.