 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Analysis of a Mass-Spring-Damper Deformable Linear Object Model in Robotic Simulation Frameworks
Apr 18, 2025The modelling of Deformable Linear Objects (DLOs) such as cables, wires, and strings presents significant challenges due to their flexible and deformable nature. In robotics, accurately simulating the dynamic behavior of DLOs is essential for automating tasks like wire handling and assembly. The presented study is a preliminary analysis aimed at force data collection through domain randomization (DR) for training a robot in simulation, using a Mass-Spring-Damper (MSD) system as the reference model. The study aims to assess the impact of model parameter variations on DLO dynamics, using Isaac Sim and Gazebo to validate the applicability of DR technique in these scenarios.
Real Time Collision Avoidance with GPU-Computed Distance Maps
Jul 02, 2024This paper presents reactive obstacle and self-collision avoidance of redundant robotic manipulators within real time kinematic feedback control using GPU-computed distance transform. The proposed framework utilizes discretized representation of the robot and the environment to calculate 3D Euclidean distance transform for task-priority based kinematic control. The environment scene is represented using a 3D GPU-voxel map created and updated from a live pointcloud data while the robotic link model is converted into a voxels offline and inserted into the voxel map according to the joint state of the robot to form the self-obstacle map. The proposed approach is evaluated using the Tiago robot, showing that all obstacle and self collision avoidance constraints are respected within one framework even with fast moving obstacles while the robot performs end-effector pose tracking in real time. A comparison of related works that depend on GPU and CPU computed distance fields is also presented to highlight the time performance as well as accuracy of the GPU distance field.
Passivizing learned policies and learning passive policies with virtual energy tanks in robotics
Jan 31, 2023Within a robotic context, we merge the techniques of passivity-based control (PBC) and reinforcement learning (RL) with the goal of eliminating some of their reciprocal weaknesses, as well as inducing novel promising features in the resulting framework. We frame our contribution in a scenario where PBC is implemented by means of virtual energy tanks, a control technique developed to achieve closed-loop passivity for any arbitrary control input. Albeit the latter result is heavily used, we discuss why its practical application at its current stage remains rather limited, which makes contact with the highly debated claim that passivity-based techniques are associated to a loss of performance. The use of RL allows to learn a control policy which can be passivized using the energy tank architecture, combining the versatility of learning approaches and the system theoretic properties which can be inferred due to the energy tanks. Simulations show the validity of the approach, as well as novel interesting research directions in energy-aware robotics.
Symplectic Integration for Multivariate Dynamic Spline-Based Model of Deformable Linear Objects
Aug 19, 2021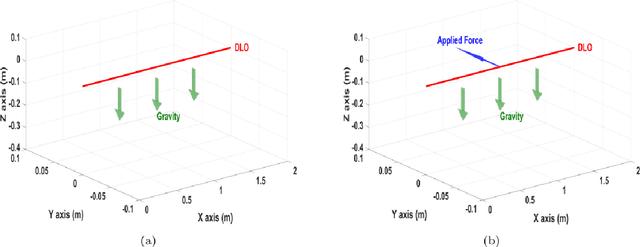

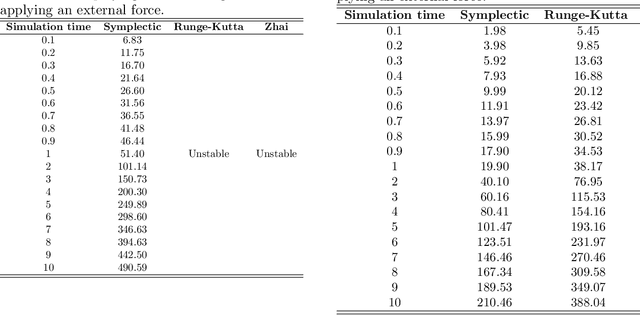
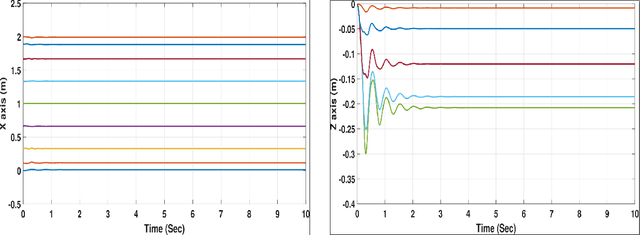
Deformable Linear Objects (DLOs) such as ropes, cables, and surgical sutures have a wide variety of uses in automotive engineering, surgery, and electromechanical industries. Therefore, modeling of DLOs as well as a computationally efficient way to predict the DLO behavior are of great importance, in particular to enable robotic manipulation of DLOs. The main motivation of this work is to enable efficient prediction of the DLO behavior during robotic manipulation. In this paper, the DLO is modeled by a multivariate dynamic spline, while a symplectic integration method is used to solve the model iteratively by interpolating the DLO shape during the manipulation process. Comparisons between the symplectic, Runge-Kutta and Zhai integrators are reported. The presented results show the capabilities of the symplectic integrator to overcome other integration methods in predicting the DLO behavior. Moreover, the results obtained with different sets of model parameters integrated by means of the symplectic method are reported to show how they influence the DLO behavior estimation.
Effective Deployment of CNNs for 3DoF Pose Estimation and Grasping in Industrial Settings
Dec 24, 2020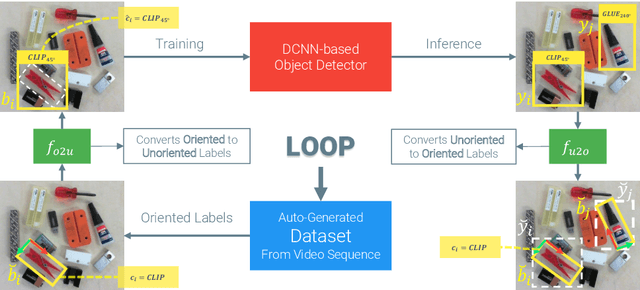
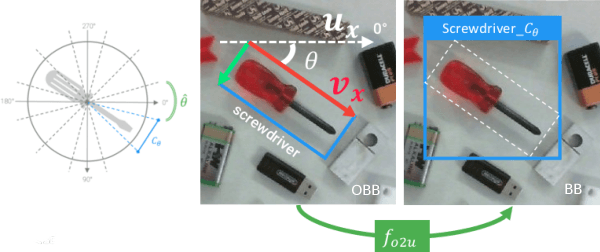
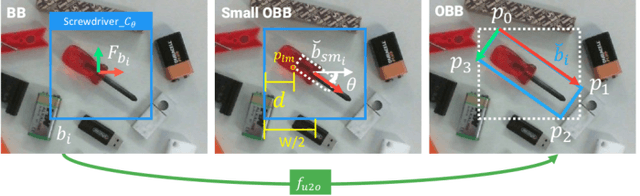
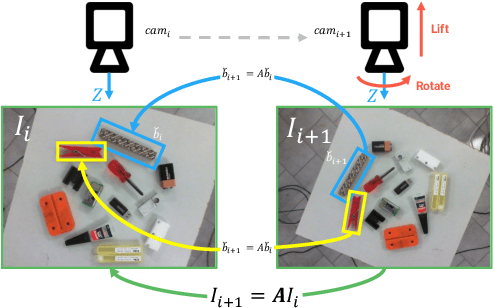
In this paper we investigate how to effectively deploy deep learning in practical industrial settings, such as robotic grasping applications. When a deep-learning based solution is proposed, usually lacks of any simple method to generate the training data. In the industrial field, where automation is the main goal, not bridging this gap is one of the main reasons why deep learning is not as widespread as it is in the academic world. For this reason, in this work we developed a system composed by a 3-DoF Pose Estimator based on Convolutional Neural Networks (CNNs) and an effective procedure to gather massive amounts of training images in the field with minimal human intervention. By automating the labeling stage, we also obtain very robust systems suitable for production-level usage. An open source implementation of our solution is provided, alongside with the dataset used for the experimental evaluation.
Semi-Automatic Labeling for Deep Learning in Robotics
Aug 05, 2019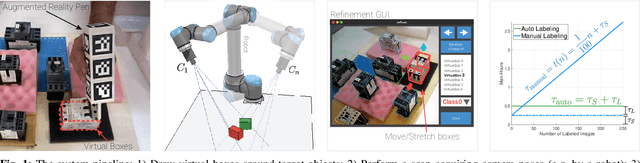
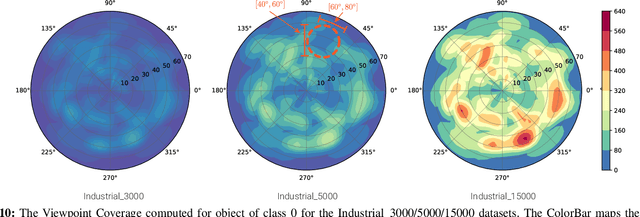
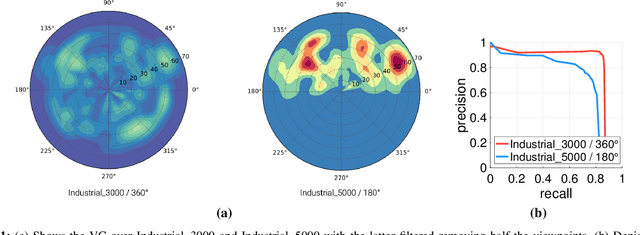
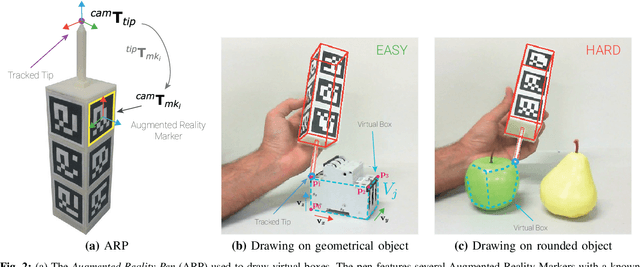
In this paper, we propose Augmented Reality Semi-automatic labeling (ARS), a semi-automatic method which leverages on moving a 2D camera by means of a robot, proving precise camera tracking, and an augmented reality pen to define initial object bounding box, to create large labeled datasets with minimal human intervention. By removing the burden of generating annotated data from humans, we make the Deep Learning technique applied to computer vision, that typically requires very large datasets, truly automated and reliable. With the ARS pipeline, we created effortlessly two novel datasets, one on electromechanical components (industrial scenario) and one on fruits (daily-living scenario), and trained robustly two state-of-the-art object detectors, based on convolutional neural networks, such as YOLO and SSD. With respect to the conventional manual annotation of 1000 frames that takes us slightly more than 10 hours, the proposed approach based on ARS allows annotating 9 sequences of about 35000 frames in less than one hour, with a gain factor of about 450. Moreover, both the precision and recall of object detection is increased by about 15\% with respect to manual labeling. All our software is available as a ROS package in a public repository alongside the novel annotated datasets.
Let's take a Walk on Superpixels Graphs: Deformable Linear Objects Segmentation and Model Estimation
Oct 10, 2018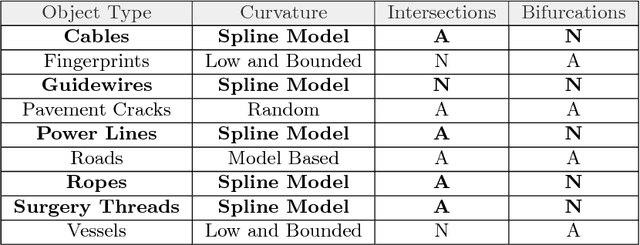
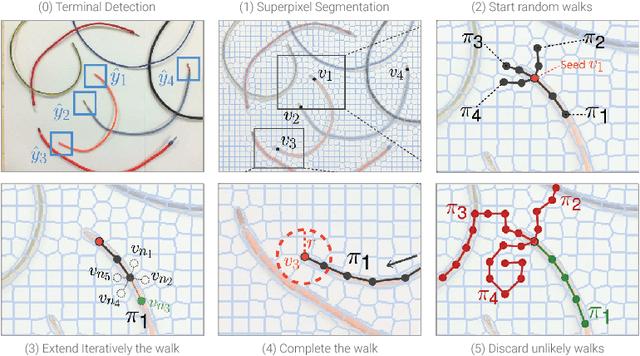
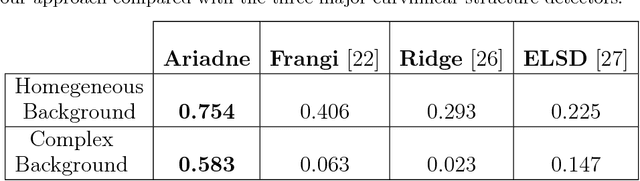
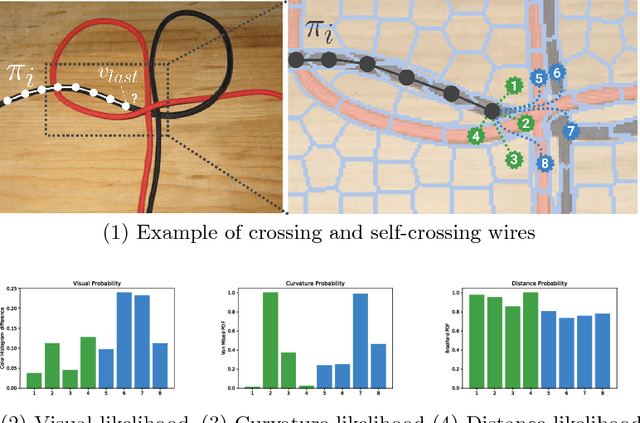
While robotic manipulation of rigid objects is quite straightforward, coping with deformable objects is an open issue. More specifically, tasks like tying a knot, wiring a connector or even surgical suturing deal with the domain of Deformable Linear Objects (DLOs). In particular the detection of a DLO is a non-trivial problem especially under clutter and occlusions (as well as self-occlusions). The pose estimation of a DLO results into the identification of its parameters related to a designed model, e.g. a basis spline. It follows that the stand-alone segmentation of a DLO might not be sufficient to conduct a full manipulation task. This is why we propose a novel framework able to perform both a semantic segmentation and b-spline modeling of multiple deformable linear objects simultaneously without strict requirements about environment (i.e. the background). The core algorithm is based on biased random walks over the Region Adiacency Graph built on a superpixel oversegmentation of the source image. The algorithm is initialized by a Convolutional Neural Networks that detects the DLO's endcaps. An open source implementation of the proposed approach is also provided to easy the reproduction of the whole detection pipeline along with a novel cables dataset in order to encourage further experiments.