 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSabiá: Um Chatbot de Inteligência Artificial Generativa para Suporte no Dia a Dia do Ensino Superior
Nov 13, 2025Students often report difficulties in accessing day-to-day academic information, which is usually spread across numerous institutional documents and websites. This fragmentation results in a lack of clarity and causes confusion about routine university information. This project proposes the development of a chatbot using Generative Artificial Intelligence (GenAI) and Retrieval-Augmented Generation (RAG) to simplify access to such information. Several GenAI models were tested and evaluated based on quality metrics and the LLM-as-a-Judge approach. Among them, Gemini 2.0 Flash stood out for its quality and speed, and Gemma 3n for its good performance and open-source nature.
An automated approach to mitigate transcription errors in braille texts for the Portuguese language
Mar 05, 2021

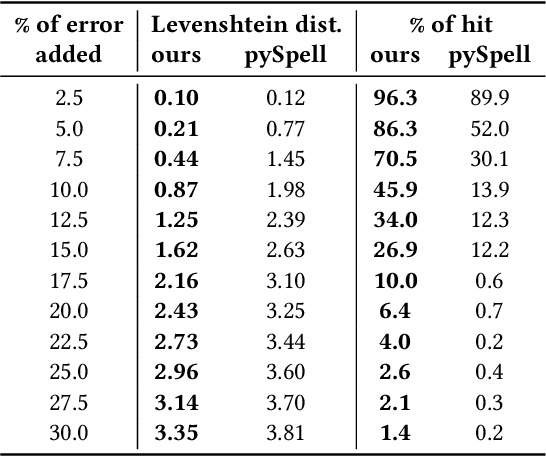
The quota system in Brazil made it possible to include blind students in higher education. Teachers' lack of knowledge about the braille system can represent a barrier between them and students who use it for writing and reading. Computer-vision-based transcription solutions represent mechanisms for reducing understanding restrictions on this system. However, such tools face nuisances inherent to image processing systems, e.g., illumination, noise, and scale, harming the result. This paper presents an automated approach to mitigate transcription errors in braille texts for the Portuguese language. We propose a selection function, combined with dictionaries, that provides the best correspondence of words based on their braille representation. We validated our proposal on a dataset of synthetic images by submitting them to different noise levels and testing the proposal's robustness. Experimental results confirm the effectiveness of the solution compared to a standard approach. As a contribution of this paper, we expect to provide a method to support robust and adaptable solutions to real use conditions.
Towards real-time object recognition and pose estimation in point clouds
Nov 27, 2020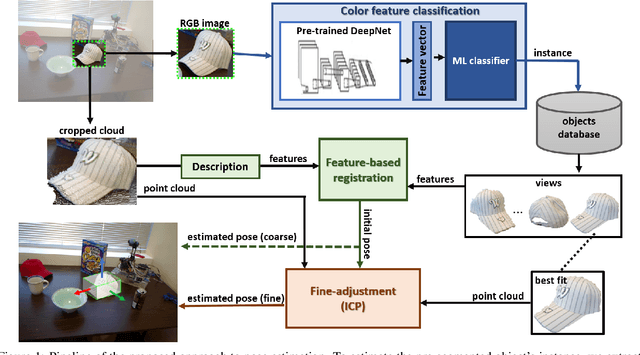
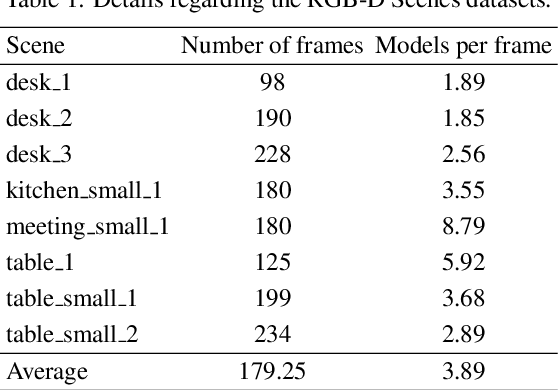

Object recognition and 6DoF pose estimation are quite challenging tasks in computer vision applications. Despite efficiency in such tasks, standard methods deliver far from real-time processing rates. This paper presents a novel pipeline to estimate a fine 6DoF pose of objects, applied to realistic scenarios in real-time. We split our proposal into three main parts. Firstly, a Color feature classification leverages the use of pre-trained CNN color features trained on the ImageNet for object detection. A Feature-based registration module conducts a coarse pose estimation, and finally, a Fine-adjustment step performs an ICP-based dense registration. Our proposal achieves, in the best case, an accuracy performance of almost 83\% on the RGB-D Scenes dataset. Regarding processing time, the object detection task is done at a frame processing rate up to 90 FPS, and the pose estimation at almost 14 FPS in a full execution strategy. We discuss that due to the proposal's modularity, we could let the full execution occurs only when necessary and perform a scheduled execution that unlocks real-time processing, even for multitask situations.
Learning to Orient Surfaces by Self-supervised Spherical CNNs
Nov 13, 2020
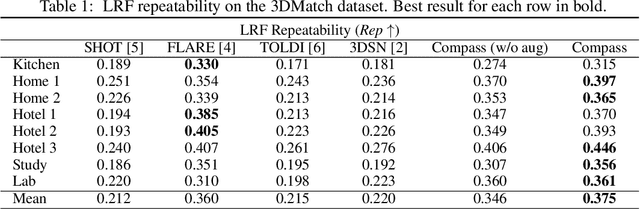
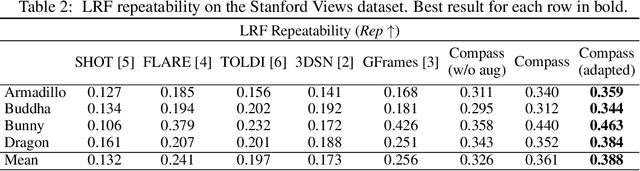
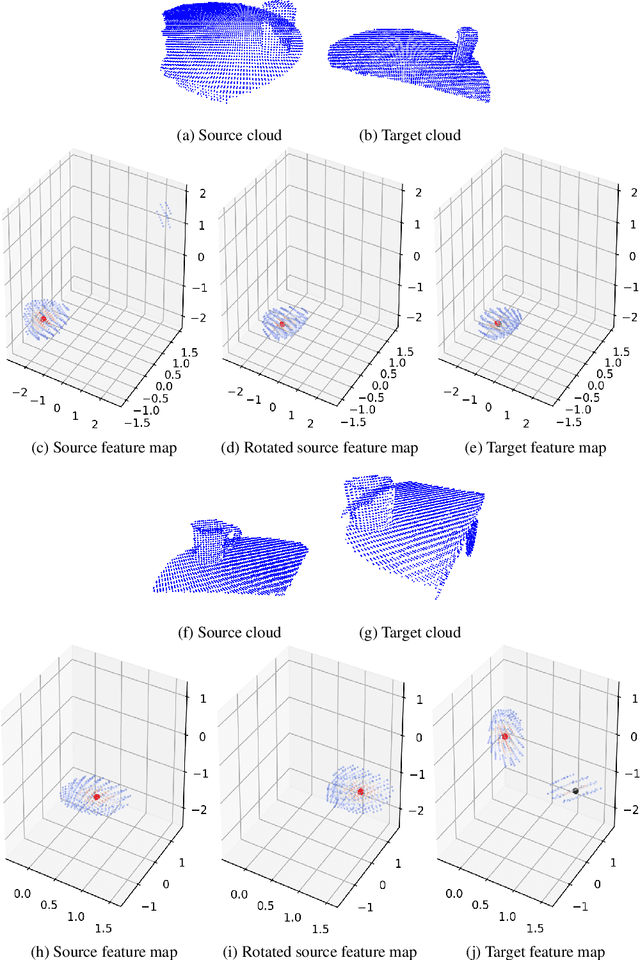
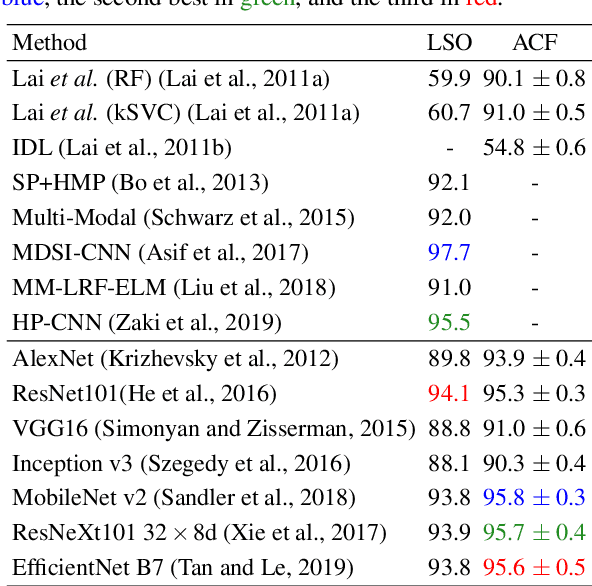
Defining and reliably finding a canonical orientation for 3D surfaces is key to many Computer Vision and Robotics applications. This task is commonly addressed by handcrafted algorithms exploiting geometric cues deemed as distinctive and robust by the designer. Yet, one might conjecture that humans learn the notion of the inherent orientation of 3D objects from experience and that machines may do so alike. In this work, we show the feasibility of learning a robust canonical orientation for surfaces represented as point clouds. Based on the observation that the quintessential property of a canonical orientation is equivariance to 3D rotations, we propose to employ Spherical CNNs, a recently introduced machinery that can learn equivariant representations defined on the Special Orthogonal group SO(3). Specifically, spherical correlations compute feature maps whose elements define 3D rotations. Our method learns such feature maps from raw data by a self-supervised training procedure and robustly selects a rotation to transform the input point cloud into a learned canonical orientation. Thereby, we realize the first end-to-end learning approach to define and extract the canonical orientation of 3D shapes, which we aptly dub Compass. Experiments on several public datasets prove its effectiveness at orienting local surface patches as well as whole objects.
Boosting Object Recognition in Point Clouds by Saliency Detection
Nov 06, 2019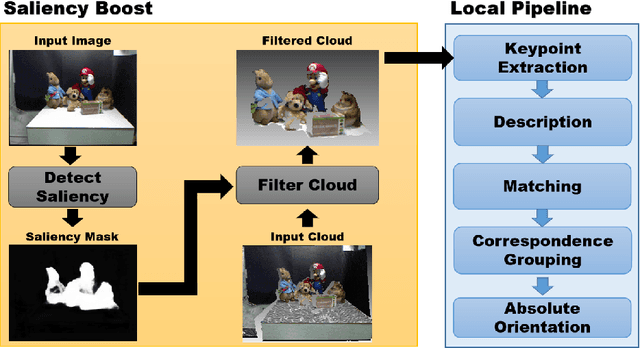


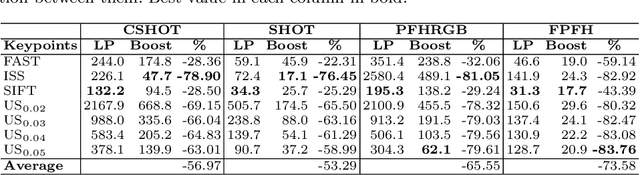
Object recognition in 3D point clouds is a challenging task, mainly when time is an important factor to deal with, such as in industrial applications. Local descriptors are an amenable choice whenever the 6 DoF pose of recognized objects should also be estimated. However, the pipeline for this kind of descriptors is highly time-consuming. In this work, we propose an update to the traditional pipeline, by adding a preliminary filtering stage referred to as saliency boost. We perform tests on a standard object recognition benchmark by considering four keypoint detectors and four local descriptors, in order to compare time and recognition performance between the traditional pipeline and the boosted one. Results on time show that the boosted pipeline could turn out up to 5 times faster, with the recognition rate improving in most of the cases and exhibiting only a slight decrease in the others. These results suggest that the boosted pipeline can speed-up processing time substantially with limited impacts or even benefits in recognition accuracy.