 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn automated approach to mitigate transcription errors in braille texts for the Portuguese language
Paper and Code


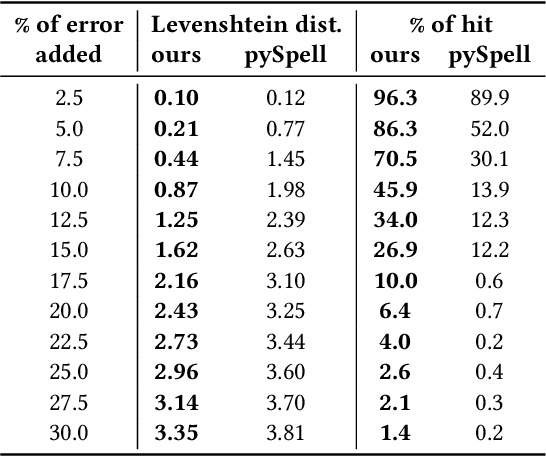
The quota system in Brazil made it possible to include blind students in higher education. Teachers' lack of knowledge about the braille system can represent a barrier between them and students who use it for writing and reading. Computer-vision-based transcription solutions represent mechanisms for reducing understanding restrictions on this system. However, such tools face nuisances inherent to image processing systems, e.g., illumination, noise, and scale, harming the result. This paper presents an automated approach to mitigate transcription errors in braille texts for the Portuguese language. We propose a selection function, combined with dictionaries, that provides the best correspondence of words based on their braille representation. We validated our proposal on a dataset of synthetic images by submitting them to different noise levels and testing the proposal's robustness. Experimental results confirm the effectiveness of the solution compared to a standard approach. As a contribution of this paper, we expect to provide a method to support robust and adaptable solutions to real use conditions.