 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranSpeech: Speech-to-Speech Translation With Bilateral Perturbation
Paper and Code
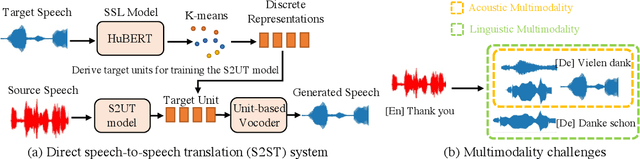

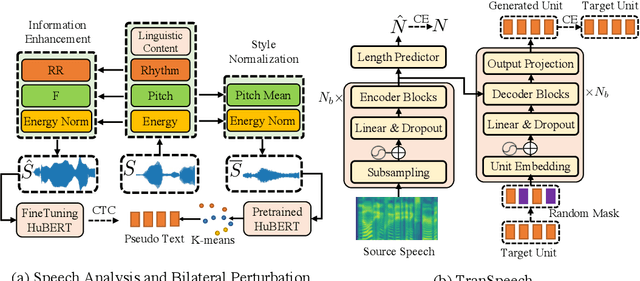

Direct speech-to-speech translation (S2ST) systems leverage recent progress in speech representation learning, where a sequence of discrete representations (units) derived in a self-supervised manner, are predicted from the model and passed to a vocoder for speech synthesis, still facing the following challenges: 1) Acoustic multimodality: the discrete units derived from speech with same content could be indeterministic due to the acoustic property (e.g., rhythm, pitch, and energy), which causes deterioration of translation accuracy; 2) high latency: current S2ST systems utilize autoregressive models which predict each unit conditioned on the sequence previously generated, failing to take full advantage of parallelism. In this work, we propose TranSpeech, a speech-to-speech translation model with bilateral perturbation. To alleviate the acoustic multimodal problem, we propose bilateral perturbation, which consists of the style normalization and information enhancement stages, to learn only the linguistic information from speech samples and generate more deterministic representations. With reduced multimodality, we step forward and become the first to establish a non-autoregressive S2ST technique, which repeatedly masks and predicts unit choices and produces high-accuracy results in just a few cycles. Experimental results on three language pairs demonstrate the state-of-the-art results by up to 2.5 BLEU points over the best publicly-available textless S2ST baseline. Moreover, TranSpeech shows a significant improvement in inference latency, enabling speedup up to 21.4x than autoregressive technique. Audio samples are available at \url{https://TranSpeech.github.io/}