 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Modality Adaptation to Sequential Recommendation via Correlation Supervision
Paper and Code
Jan 14, 2024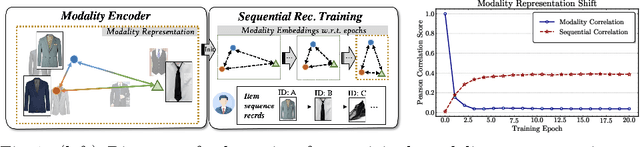
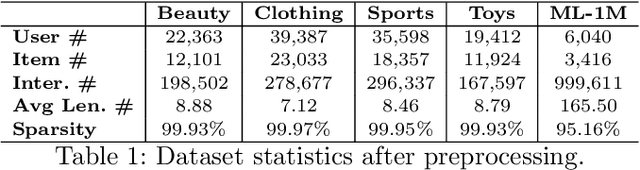
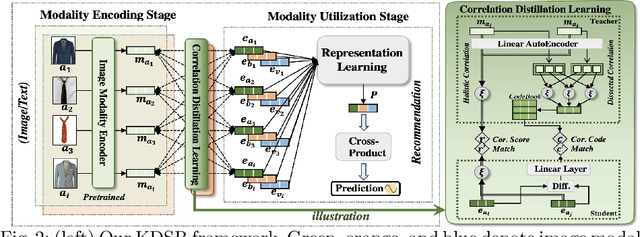
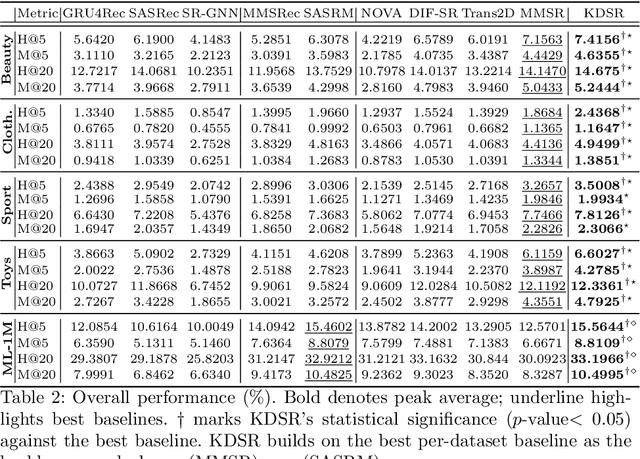
In Sequential Recommenders (SR), encoding and utilizing modalities in an end-to-end manner is costly in terms of modality encoder sizes. Two-stage approaches can mitigate such concerns, but they suffer from poor performance due to modality forgetting, where the sequential objective overshadows modality representation. We propose a lightweight knowledge distillation solution that preserves both merits: retaining modality information and maintaining high efficiency. Specifically, we introduce a novel method that enhances the learning of embeddings in SR through the supervision of modality correlations. The supervision signals are distilled from the original modality representations, including both (1) holistic correlations, which quantify their overall associations, and (2) dissected correlation types, which refine their relationship facets (honing in on specific aspects like color or shape consistency). To further address the issue of modality forgetting, we propose an asynchronous learning step, allowing the original information to be retained longer for training the representation learning module. Our approach is compatible with various backbone architectures and outperforms the top baselines by 6.8% on average. We empirically demonstrate that preserving original feature associations from modality encoders significantly boosts task-specific recommendation adaptation. Additionally, we find that larger modality encoders (e.g., Large Language Models) contain richer feature sets which necessitate more fine-grained modeling to reach their full performance potential.