 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Unknown Interdependencies for Decentralized Root Cause Analysis in Nonlinear Dynamical Systems
Feb 25, 2026Root cause analysis (RCA) in networked industrial systems, such as supply chains and power networks, is notoriously difficult due to unknown and dynamically evolving interdependencies among geographically distributed clients. These clients represent heterogeneous physical processes and industrial assets equipped with sensors that generate large volumes of nonlinear, high-dimensional, and heterogeneous IoT data. Classical RCA methods require partial or full knowledge of the system's dependency graph, which is rarely available in these complex networks. While federated learning (FL) offers a natural framework for decentralized settings, most existing FL methods assume homogeneous feature spaces and retrainable client models. These assumptions are not compatible with our problem setting. Different clients have different data features and often run fixed, proprietary models that cannot be modified. This paper presents a federated cross-client interdependency learning methodology for feature-partitioned, nonlinear time-series data, without requiring access to raw sensor streams or modifying proprietary client models. Each proprietary local client model is augmented with a Machine Learning (ML) model that encodes cross-client interdependencies. These ML models are coordinated via a global server that enforces representation consistency while preserving privacy through calibrated differential privacy noise. RCA is performed using model residuals and anomaly flags. We establish theoretical convergence guarantees and validate our approach on extensive simulations and a real-world industrial cybersecurity dataset.
Federated Causal Representation Learning in State-Space Systems for Decentralized Counterfactual Reasoning
Feb 23, 2026Networks of interdependent industrial assets (clients) are tightly coupled through physical processes and control inputs, raising a key question: how would the output of one client change if another client were operated differently? This is difficult to answer because client-specific data are high-dimensional and private, making centralization of raw data infeasible. Each client also maintains proprietary local models that cannot be modified. We propose a federated framework for causal representation learning in state-space systems that captures interdependencies among clients under these constraints. Each client maps high-dimensional observations into low-dimensional latent states that disentangle intrinsic dynamics from control-driven influences. A central server estimates the global state-transition and control structure. This enables decentralized counterfactual reasoning where clients predict how outputs would change under alternative control inputs at others while only exchanging compact latent states. We prove convergence to a centralized oracle and provide privacy guarantees. Our experiments demonstrate scalability, and accurate cross-client counterfactual inference on synthetic and real-world industrial control system datasets.
Uncertainty in Federated Granger Causality: From Origins to Systemic Consequences
Feb 13, 2026Granger Causality (GC) provides a rigorous framework for learning causal structures from time-series data. Recent federated variants of GC have targeted distributed infrastructure applications (e.g., smart grids) with distributed clients that generate high-dimensional data bound by data-sovereignty constraints. However, Federated GC algorithms only yield deterministic point estimates of causality and neglect uncertainty. This paper establishes the first methodology for rigorously quantifying uncertainty and its propagation within federated GC frameworks. We systematically classify sources of uncertainty, explicitly differentiating aleatoric (data noise) from epistemic (model variability) effects. We derive closed-form recursions that model the evolution of uncertainty through client-server interactions and identify four novel cross-covariance components that couple data uncertainties with model parameter uncertainties across the federated architecture. We also define rigorous convergence conditions for these uncertainty recursions and obtain explicit steady-state variances for both server and client model parameters. Our convergence analysis demonstrates that steady-state variances depend exclusively on client data statistics, thus eliminating dependence on initial epistemic priors and enhancing robustness. Empirical evaluations on synthetic benchmarks and real-world industrial datasets demonstrate that explicitly characterizing uncertainty significantly improves the reliability and interpretability of federated causal inference.
Federated Learning of Nonlinear Temporal Dynamics with Graph Attention-based Cross-Client Interpretability
Feb 13, 2026Networks of modern industrial systems are increasingly monitored by distributed sensors, where each system comprises multiple subsystems generating high dimensional time series data. These subsystems are often interdependent, making it important to understand how temporal patterns at one subsystem relate to others. This is challenging in decentralized settings where raw measurements cannot be shared and client observations are heterogeneous. In practical deployments each subsystem (client) operates a fixed proprietary model that cannot be modified or retrained, limiting existing approaches. Nonlinear dynamics further make cross client temporal interdependencies difficult to interpret because they are embedded in nonlinear state transition functions. We present a federated framework for learning temporal interdependencies across clients under these constraints. Each client maps high dimensional local observations to low dimensional latent states using a nonlinear state space model. A central server learns a graph structured neural state transition model over the communicated latent states using a Graph Attention Network. For interpretability we relate the Jacobian of the learned server side transition model to attention coefficients, providing the first interpretable characterization of cross client temporal interdependencies in decentralized nonlinear systems. We establish theoretical convergence guarantees to a centralized oracle and validate the framework through synthetic experiments demonstrating convergence, interpretability, scalability and privacy. Additional real world experiments show performance comparable to decentralized baselines.
Federated Granger Causality Learning for Interdependent Clients with State Space Representation
Jan 27, 2025



Advanced sensors and IoT devices have improved the monitoring and control of complex industrial enterprises. They have also created an interdependent fabric of geographically distributed process operations (clients) across these enterprises. Granger causality is an effective approach to detect and quantify interdependencies by examining how one client's state affects others over time. Understanding these interdependencies captures how localized events, such as faults and disruptions, can propagate throughout the system, possibly causing widespread operational impacts. However, the large volume and complexity of industrial data pose challenges in modeling these interdependencies. This paper develops a federated approach to learning Granger causality. We utilize a linear state space system framework that leverages low-dimensional state estimates to analyze interdependencies. This addresses bandwidth limitations and the computational burden commonly associated with centralized data processing. We propose augmenting the client models with the Granger causality information learned by the server through a Machine Learning (ML) function. We examine the co-dependence between the augmented client and server models and reformulate the framework as a standalone ML algorithm providing conditions for its sublinear and linear convergence rates. We also study the convergence of the framework to a centralized oracle model. Moreover, we include a differential privacy analysis to ensure data security while preserving causal insights. Using synthetic data, we conduct comprehensive experiments to demonstrate the robustness of our approach to perturbations in causality, the scalability to the size of communication, number of clients, and the dimensions of raw data. We also evaluate the performance on two real-world industrial control system datasets by reporting the volume of data saved by decentralization.
Prognostic Framework for Robotic Manipulators Operating Under Dynamic Task Severities
Nov 30, 2024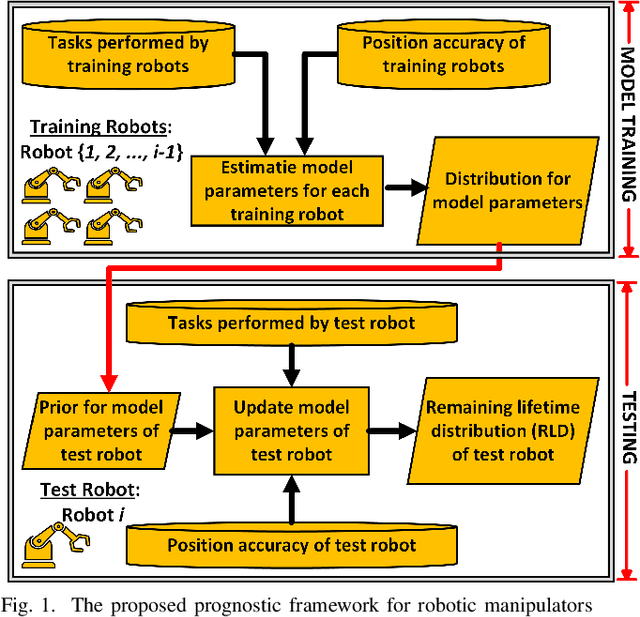
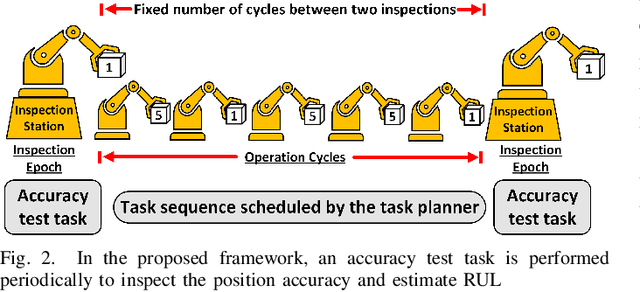
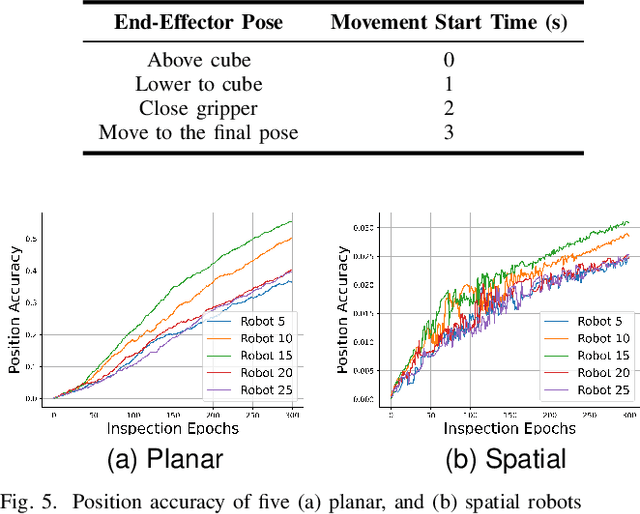
Robotic manipulators are critical in many applications but are known to degrade over time. This degradation is influenced by the nature of the tasks performed by the robot. Tasks with higher severity, such as handling heavy payloads, can accelerate the degradation process. One way this degradation is reflected is in the position accuracy of the robot's end-effector. In this paper, we present a prognostic modeling framework that predicts a robotic manipulator's Remaining Useful Life (RUL) while accounting for the effects of task severity. Our framework represents the robot's position accuracy as a Brownian motion process with a random drift parameter that is influenced by task severity. The dynamic nature of task severity is modeled using a continuous-time Markov chain (CTMC). To evaluate RUL, we discuss two approaches -- (1) a novel closed-form expression for Remaining Lifetime Distribution (RLD), and (2) Monte Carlo simulations, commonly used in prognostics literature. Theoretical results establish the equivalence between these RUL computation approaches. We validate our framework through experiments using two distinct physics-based simulators for planar and spatial robot fleets. Our findings show that robots in both fleets experience shorter RUL when handling a higher proportion of high-severity tasks.
Sensor-fusion based Prognostics Framework for Complex Engineering Systems Exhibiting Multiple Failure Modes
Nov 19, 2024Complex engineering systems are often subject to multiple failure modes. Developing a remaining useful life (RUL) prediction model that does not consider the failure mode causing degradation is likely to result in inaccurate predictions. However, distinguishing between causes of failure without manually inspecting the system is nontrivial. This challenge is increased when the causes of historically observed failures are unknown. Sensors, which are useful for monitoring the state-of-health of systems, can also be used for distinguishing between multiple failure modes as the presence of multiple failure modes results in discriminatory behavior of the sensor signals. When systems are equipped with multiple sensors, some sensors may exhibit behavior correlated with degradation, while other sensors do not. Furthermore, which sensors exhibit this behavior may differ for each failure mode. In this paper, we present a simultaneous clustering and sensor selection approach for unlabeled training datasets of systems exhibiting multiple failure modes. The cluster assignments and the selected sensors are then utilized in real-time to first diagnose the active failure mode and then to predict the system RUL. We validate the complete pipeline of the methodology using a simulated dataset of systems exhibiting two failure modes and on a turbofan degradation dataset from NASA.