 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure Modes of LLMs for Causal Reasoning on Narratives
Oct 31, 2024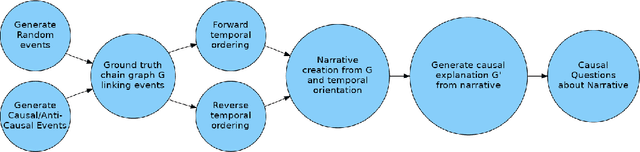

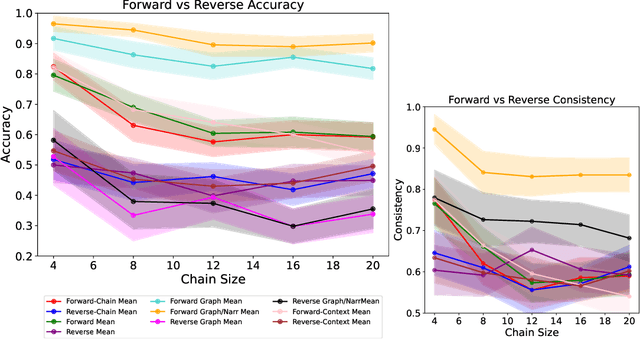
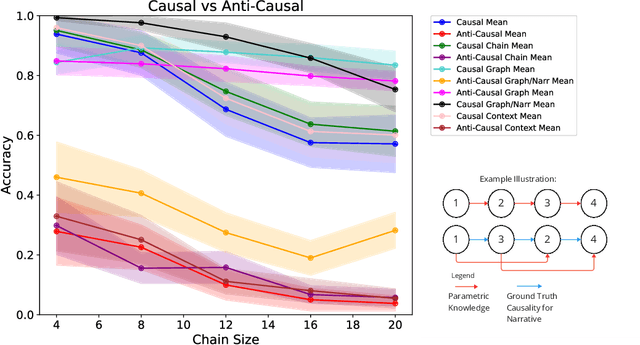
In this work, we investigate the causal reasoning abilities of large language models (LLMs) through the representative problem of inferring causal relationships from narratives. We find that even state-of-the-art language models rely on unreliable shortcuts, both in terms of the narrative presentation and their parametric knowledge. For example, LLMs tend to determine causal relationships based on the topological ordering of events (i.e., earlier events cause later ones), resulting in lower performance whenever events are not narrated in their exact causal order. Similarly, we demonstrate that LLMs struggle with long-term causal reasoning and often fail when the narratives are long and contain many events. Additionally, we show LLMs appear to rely heavily on their parametric knowledge at the expense of reasoning over the provided narrative. This degrades their abilities whenever the narrative opposes parametric knowledge. We extensively validate these failure modes through carefully controlled synthetic experiments, as well as evaluations on real-world narratives. Finally, we observe that explicitly generating a causal graph generally improves performance while naive chain-of-thought is ineffective. Collectively, our results distill precise failure modes of current state-of-the-art models and can pave the way for future techniques to enhance causal reasoning in LLMs.
A Generalized Acquisition Function for Preference-based Reward Learning
Mar 09, 2024

Preference-based reward learning is a popular technique for teaching robots and autonomous systems how a human user wants them to perform a task. Previous works have shown that actively synthesizing preference queries to maximize information gain about the reward function parameters improves data efficiency. The information gain criterion focuses on precisely identifying all parameters of the reward function. This can potentially be wasteful as many parameters may result in the same reward, and many rewards may result in the same behavior in the downstream tasks. Instead, we show that it is possible to optimize for learning the reward function up to a behavioral equivalence class, such as inducing the same ranking over behaviors, distribution over choices, or other related definitions of what makes two rewards similar. We introduce a tractable framework that can capture such definitions of similarity. Our experiments in a synthetic environment, an assistive robotics environment with domain transfer, and a natural language processing problem with real datasets demonstrate the superior performance of our querying method over the state-of-the-art information gain method.
The Effect of Modeling Human Rationality Level on Learning Rewards from Multiple Feedback Types
Aug 23, 2022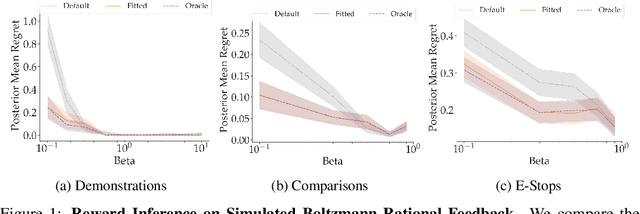

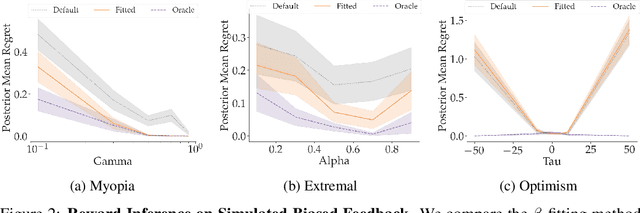
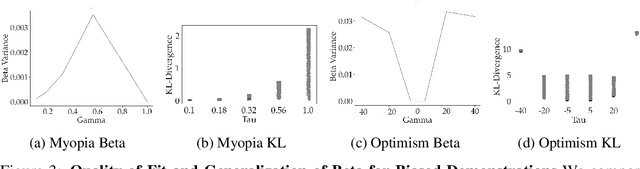
When inferring reward functions from human behavior (be it demonstrations, comparisons, physical corrections, or e-stops), it has proven useful to model the human as making noisy-rational choices, with a "rationality coefficient" capturing how much noise or entropy we expect to see in the human behavior. Many existing works have opted to fix this coefficient regardless of the type, or quality, of human feedback. However, in some settings, giving a demonstration may be much more difficult than answering a comparison query. In this case, we should expect to see more noise or suboptimality in demonstrations than in comparisons, and should interpret the feedback accordingly. In this work, we advocate that grounding the rationality coefficient in real data for each feedback type, rather than assuming a default value, has a significant positive effect on reward learning. We test this in experiments with both simulated feedback, as well a user study. We find that when learning from a single feedback type, overestimating human rationality can have dire effects on reward accuracy and regret. Further, we find that the rationality level affects the informativeness of each feedback type: surprisingly, demonstrations are not always the most informative -- when the human acts very suboptimally, comparisons actually become more informative, even when the rationality level is the same for both. Moreover, when the robot gets to decide which feedback type to ask for, it gets a large advantage from accurately modeling the rationality level of each type. Ultimately, our results emphasize the importance of paying attention to the assumed rationality level, not only when learning from a single feedback type, but especially when agents actively learn from multiple feedback types.
Multi-Modal Prototype Learning for Interpretable Multivariable Time Series Classification
Jun 17, 2021
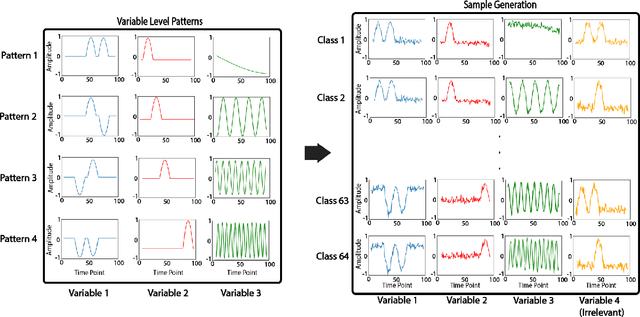
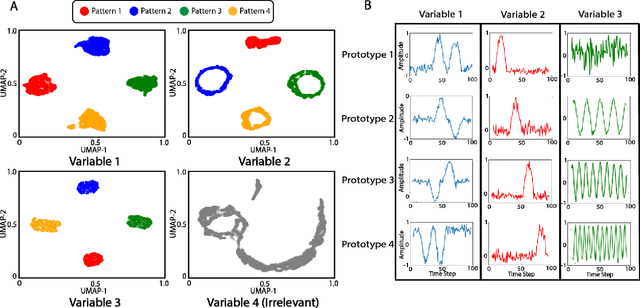
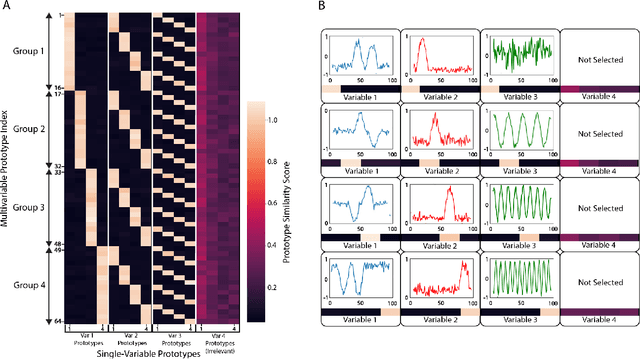
Multivariable time series classification problems are increasing in prevalence and complexity in a variety of domains, such as biology and finance. While deep learning methods are an effective tool for these problems, they often lack interpretability. In this work, we propose a novel modular prototype learning framework for multivariable time series classification. In the first stage of our framework, encoders extract features from each variable independently. Prototype layers identify single-variable prototypes in the resulting feature spaces. The next stage of our framework represents the multivariable time series sample points in terms of their similarity to these single-variable prototypes. This results in an inherently interpretable representation of multivariable patterns, on which prototype learning is applied to extract representative examples i.e. multivariable prototypes. Our framework is thus able to explicitly identify both informative patterns in the individual variables, as well as the relationships between the variables. We validate our framework on a simulated dataset with embedded patterns, as well as a real human activity recognition problem. Our framework attains comparable or superior classification performance to existing time series classification methods on these tasks. On the simulated dataset, we find that our model returns interpretations consistent with the embedded patterns. Moreover, the interpretations learned on the activity recognition dataset align with domain knowledge.