 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Act Like Rational Agents? Measuring Belief Coherence in Probabilistic Decision Making
Feb 06, 2026Large language models (LLMs) are increasingly deployed as agents in high-stakes domains where optimal actions depend on both uncertainty about the world and consideration of utilities of different outcomes, yet their decision logic remains difficult to interpret. We study whether LLMs are rational utility maximizers with coherent beliefs and stable preferences. We consider behaviors of models for diagnosis challenge problems. The results provide insights about the relationship of LLM inferences to ideal Bayesian utility maximization for elicited probabilities and observed actions. Our approach provides falsifiable conditions under which the reported probabilities \emph{cannot} correspond to the true beliefs of any rational agent. We apply this methodology to multiple medical diagnostic domains with evaluations across several LLMs. We discuss implications of the results and directions forward for uses of LLMs in guiding high-stakes decisions.
Predicting Language Models' Success at Zero-Shot Probabilistic Prediction
Sep 18, 2025Recent work has investigated the capabilities of large language models (LLMs) as zero-shot models for generating individual-level characteristics (e.g., to serve as risk models or augment survey datasets). However, when should a user have confidence that an LLM will provide high-quality predictions for their particular task? To address this question, we conduct a large-scale empirical study of LLMs' zero-shot predictive capabilities across a wide range of tabular prediction tasks. We find that LLMs' performance is highly variable, both on tasks within the same dataset and across different datasets. However, when the LLM performs well on the base prediction task, its predicted probabilities become a stronger signal for individual-level accuracy. Then, we construct metrics to predict LLMs' performance at the task level, aiming to distinguish between tasks where LLMs may perform well and where they are likely unsuitable. We find that some of these metrics, each of which are assessed without labeled data, yield strong signals of LLMs' predictive performance on new tasks.
Dependent Randomized Rounding for Budget Constrained Experimental Design
Jun 15, 2025Policymakers in resource-constrained settings require experimental designs that satisfy strict budget limits while ensuring precise estimation of treatment effects. We propose a framework that applies a dependent randomized rounding procedure to convert assignment probabilities into binary treatment decisions. Our proposed solution preserves the marginal treatment probabilities while inducing negative correlations among assignments, leading to improved estimator precision through variance reduction. We establish theoretical guarantees for the inverse propensity weighted and general linear estimators, and demonstrate through empirical studies that our approach yields efficient and accurate inference under fixed budget constraints.
Failure Modes of LLMs for Causal Reasoning on Narratives
Oct 31, 2024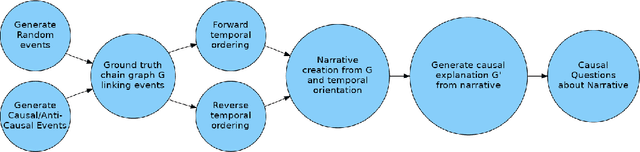

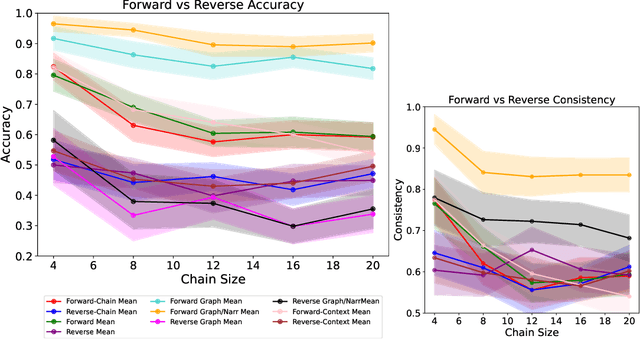
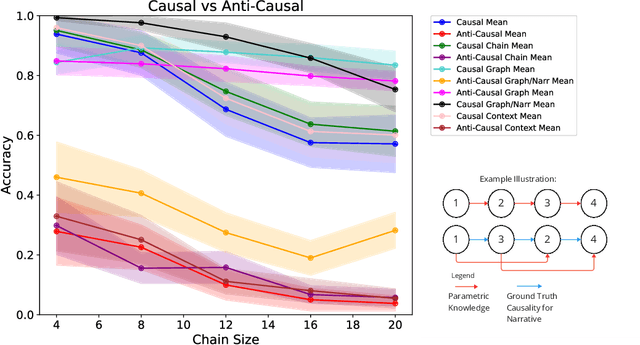
In this work, we investigate the causal reasoning abilities of large language models (LLMs) through the representative problem of inferring causal relationships from narratives. We find that even state-of-the-art language models rely on unreliable shortcuts, both in terms of the narrative presentation and their parametric knowledge. For example, LLMs tend to determine causal relationships based on the topological ordering of events (i.e., earlier events cause later ones), resulting in lower performance whenever events are not narrated in their exact causal order. Similarly, we demonstrate that LLMs struggle with long-term causal reasoning and often fail when the narratives are long and contain many events. Additionally, we show LLMs appear to rely heavily on their parametric knowledge at the expense of reasoning over the provided narrative. This degrades their abilities whenever the narrative opposes parametric knowledge. We extensively validate these failure modes through carefully controlled synthetic experiments, as well as evaluations on real-world narratives. Finally, we observe that explicitly generating a causal graph generally improves performance while naive chain-of-thought is ineffective. Collectively, our results distill precise failure modes of current state-of-the-art models and can pave the way for future techniques to enhance causal reasoning in LLMs.
Accounting for Missing Covariates in Heterogeneous Treatment Estimation
Oct 21, 2024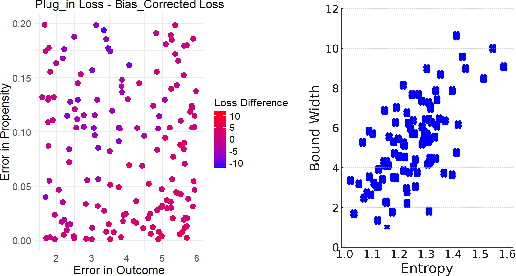
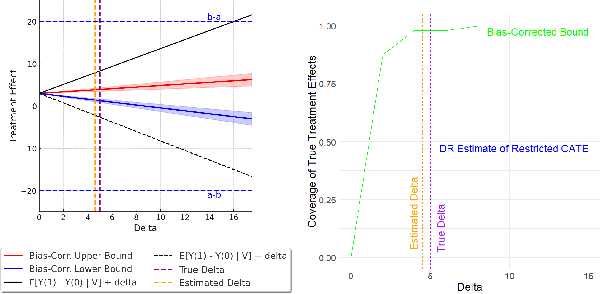
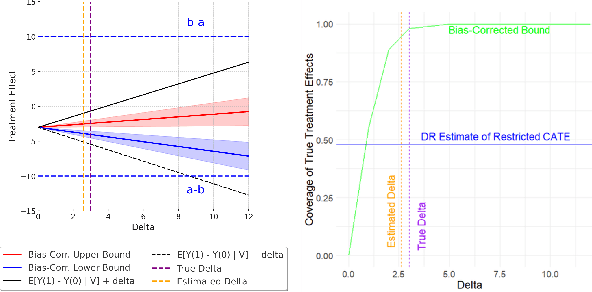
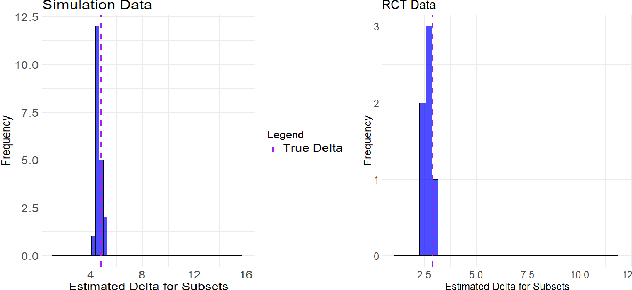
Many applications of causal inference require using treatment effects estimated on a study population to make decisions in a separate target population. We consider the challenging setting where there are covariates that are observed in the target population that were not seen in the original study. Our goal is to estimate the tightest possible bounds on heterogeneous treatment effects conditioned on such newly observed covariates. We introduce a novel partial identification strategy based on ideas from ecological inference; the main idea is that estimates of conditional treatment effects for the full covariate set must marginalize correctly when restricted to only the covariates observed in both populations. Furthermore, we introduce a bias-corrected estimator for these bounds and prove that it enjoys fast convergence rates and statistical guarantees (e.g., asymptotic normality). Experimental results on both real and synthetic data demonstrate that our framework can produce bounds that are much tighter than would otherwise be possible.
Novelty Detection for Election Fraud: A Case Study with Agent-Based Simulation Data
Nov 29, 2022



In this paper, we propose a robust election simulation model and independently developed election anomaly detection algorithm that demonstrates the simulation's utility. The simulation generates artificial elections with similar properties and trends as elections from the real world, while giving users control and knowledge over all the important components of the elections. We generate a clean election results dataset without fraud as well as datasets with varying degrees of fraud. We then measure how well the algorithm is able to successfully detect the level of fraud present. The algorithm determines how similar actual election results are as compared to the predicted results from polling and a regression model of other regions that have similar demographics. We use k-means to partition electoral regions into clusters such that demographic homogeneity is maximized among clusters. We then use a novelty detection algorithm implemented as a one-class Support Vector Machine where the clean data is provided in the form of polling predictions and regression predictions. The regression predictions are built from the actual data in such a way that the data supervises itself. We show both the effectiveness of the simulation technique and the machine learning model in its success in identifying fraudulent regions.
Online Detection Of Supply Chain Network Disruptions Using Sequential Change-Point Detection for Hawkes Processes
Nov 22, 2022
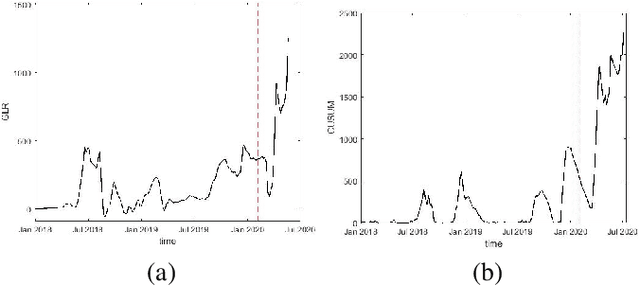


In this paper, we attempt to detect an inflection or change-point resulting from the Covid-19 pandemic on supply chain data received from a large furniture company. To accomplish this, we utilize a modified CUSUM (Cumulative Sum) procedure on the company's spatial-temporal order data as well as a GLR (Generalized Likelihood Ratio) based method. We model the order data using the Hawkes Process Network, a multi-dimensional self and mutually exciting point process, by discretizing the spatial data and treating each order as an event that has a corresponding node and time. We apply the methodologies on the company's most ordered item on a national scale and perform a deep dive into a single state. Because the item was ordered infrequently in the state compared to the nation, this approach allows us to show efficacy upon different degrees of data sparsity. Furthermore, it showcases use potential across differing levels of spatial detail.