 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Reinforcement Learning across Homotopy Classes
Paper and Code
Feb 11, 2021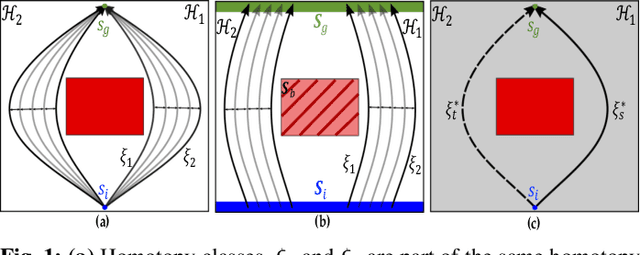
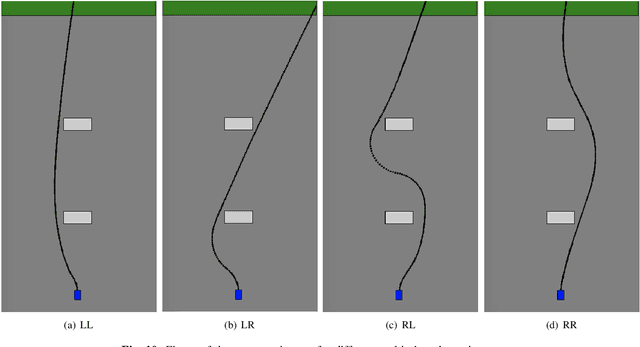
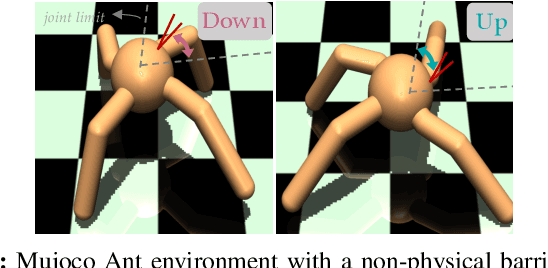
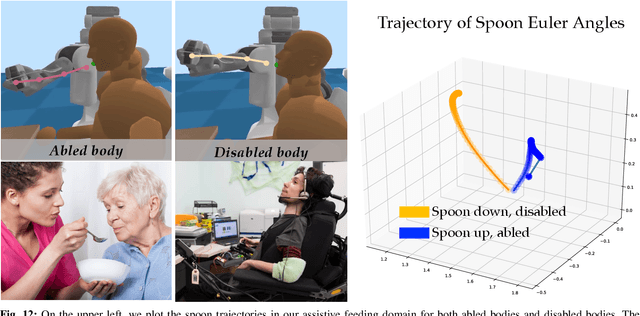
The ability for robots to transfer their learned knowledge to new tasks -- where data is scarce -- is a fundamental challenge for successful robot learning. While fine-tuning has been well-studied as a simple but effective transfer approach in the context of supervised learning, it is not as well-explored in the context of reinforcement learning. In this work, we study the problem of fine-tuning in transfer reinforcement learning when tasks are parameterized by their reward functions, which are known beforehand. We conjecture that fine-tuning drastically underperforms when source and target trajectories are part of different homotopy classes. We demonstrate that fine-tuning policy parameters across homotopy classes compared to fine-tuning within a homotopy class requires more interaction with the environment, and in certain cases is impossible. We propose a novel fine-tuning algorithm, Ease-In-Ease-Out fine-tuning, that consists of a relaxing stage and a curriculum learning stage to enable transfer learning across homotopy classes. Finally, we evaluate our approach on several robotics-inspired simulated environments and empirically verify that the Ease-In-Ease-Out fine-tuning method can successfully fine-tune in a sample-efficient way compared to existing baselines.