 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Heuristics to Analytics: Forecasting Effort and Progress in Online Learning
May 12, 2026Sustained effort is essential for realizing the benefits of intelligent tutoring systems (ITS), yet many learners disengage or underuse available practice time. We introduce engagement forecasting as a supervised prediction task based on ITS logs, targeting two outcomes central to effort and learning progress: minutes practiced per week and new skills mastered per week. Using interaction log data from 425 middle-school students over a school year, we benchmark fifteen predictors including regressions, decision trees, and neural networks. We show that these feature-based models reduce mean absolute error (MAE) by 22-33% relative to heuristic baselines, including fixed-percentile rules adapted from prior work in other behavioral domains. We find that percentile heuristics systematically overpredict, whereas feature-based models better track student practice trajectories across weeks. To support explainability, we analyze feature importance and ablations, revealing target-specific patterns: effort forecasting is driven mainly by recent activity features, while progress forecasting depends more on learner-state and content difficulty signals. Finally, in a semi-structured user interview case study with eight college tutors, we examine how tutors reasoned about system-generated predictive features when setting goals with students. We find that tutors reasoned differently about effort versus progress goals in ways that mirror our pattern analysis. Together, these results establish a reproducible benchmark for forecasting weekly effort and learning progress in ITS. By making patterns of sustained effort and progress visible at a weekly timescale, engagement forecasting offers a foundation for supporting tutor-learner goal setting and timely instructional decisions.
Evaluating a Data-Driven Redesign Process for Intelligent Tutoring Systems
Mar 31, 2026Past research has defined a general process for the data-driven redesign of educational technologies and has shown that in carefully-selected instances, this process can help make systems more effective. In the current work, we test the generality of the approach by applying it to four units of a middle-school mathematics intelligent tutoring system that were selected not based on suitability for redesign, as in previous work, but on topic. We tested whether the redesigned system was more effective than the original in a classroom study with 123 students. Although the learning gains did not differ between the conditions, students who used the Redesigned Tutor had more productive time-on-task, a larger number of skills practiced, and greater total knowledge mastery. The findings highlight the promise of data-driven redesign even when applied to instructional units *not* selected as likely to yield improvement, as evidence of the generality and wide applicability of the method.
Combining Large Language Models with Tutoring System Intelligence: A Case Study in Caregiver Homework Support
Dec 16, 2024



Caregivers (i.e., parents and members of a child's caring community) are underappreciated stakeholders in learning analytics. Although caregiver involvement can enhance student academic outcomes, many obstacles hinder involvement, most notably knowledge gaps with respect to modern school curricula. An emerging topic of interest in learning analytics is hybrid tutoring, which includes instructional and motivational support. Caregivers assert similar roles in homework, yet it is unknown how learning analytics can support them. Our past work with caregivers suggested that conversational support is a promising method of providing caregivers with the guidance needed to effectively support student learning. We developed a system that provides instructional support to caregivers through conversational recommendations generated by a Large Language Model (LLM). Addressing known instructional limitations of LLMs, we use instructional intelligence from tutoring systems while conducting prompt engineering experiments with the open-source Llama 3 LLM. This LLM generated message recommendations for caregivers supporting their child's math practice via chat. Few-shot prompting and combining real-time problem-solving context from tutoring systems with examples of tutoring practices yielded desirable message recommendations. These recommendations were evaluated with ten middle school caregivers, who valued recommendations facilitating content-level support and student metacognition through self-explanation. We contribute insights into how tutoring systems can best be merged with LLMs to support hybrid tutoring settings through conversational assistance, facilitating effective caregiver involvement in tutoring systems.
TRESTLE: A Model of Concept Formation in Structured Domains
Oct 14, 2024
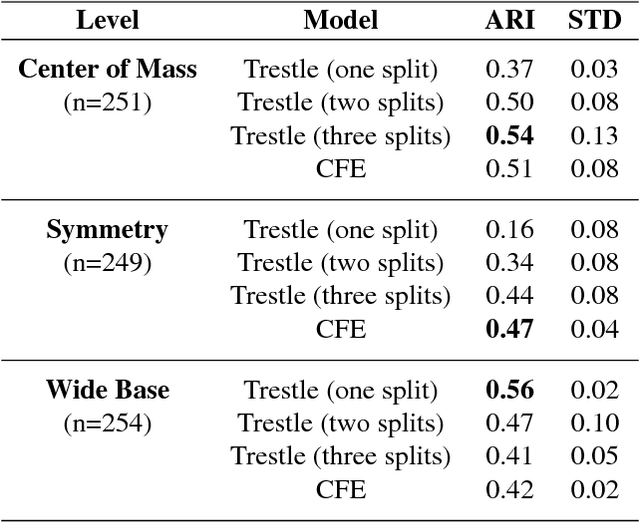


The literature on concept formation has demonstrated that humans are capable of learning concepts incrementally, with a variety of attribute types, and in both supervised and unsupervised settings. Many models of concept formation focus on a subset of these characteristics, but none account for all of them. In this paper, we present TRESTLE, an incremental account of probabilistic concept formation in structured domains that unifies prior concept learning models. TRESTLE works by creating a hierarchical categorization tree that can be used to predict missing attribute values and cluster sets of examples into conceptually meaningful groups. It updates its knowledge by partially matching novel structures and sorting them into its categorization tree. Finally, the system supports mixed-data representations, including nominal, numeric, relational, and component attributes. We evaluate TRESTLE's performance on a supervised learning task and an unsupervised clustering task. For both tasks, we compare it to a nonincremental model and to human participants. We find that this new categorization model is competitive with the nonincremental approach and more closely approximates human behavior on both tasks. These results serve as an initial demonstration of TRESTLE's capabilities and show that, by taking key characteristics of human learning into account, it can better model behavior than approaches that ignore them.
* 20 pages, 6 figures, 1 table
How Can I Get It Right? Using GPT to Rephrase Incorrect Trainee Responses
May 02, 2024



One-on-one tutoring is widely acknowledged as an effective instructional method, conditioned on qualified tutors. However, the high demand for qualified tutors remains a challenge, often necessitating the training of novice tutors (i.e., trainees) to ensure effective tutoring. Research suggests that providing timely explanatory feedback can facilitate the training process for trainees. However, it presents challenges due to the time-consuming nature of assessing trainee performance by human experts. Inspired by the recent advancements of large language models (LLMs), our study employed the GPT-4 model to build an explanatory feedback system. This system identifies trainees' responses in binary form (i.e., correct/incorrect) and automatically provides template-based feedback with responses appropriately rephrased by the GPT-4 model. We conducted our study on 410 responses from trainees across three training lessons: Giving Effective Praise, Reacting to Errors, and Determining What Students Know. Our findings indicate that: 1) using a few-shot approach, the GPT-4 model effectively identifies correct/incorrect trainees' responses from three training lessons with an average F1 score of 0.84 and an AUC score of 0.85; and 2) using the few-shot approach, the GPT-4 model adeptly rephrases incorrect trainees' responses into desired responses, achieving performance comparable to that of human experts.
Revealing Networks: Understanding Effective Teacher Practices in AI-Supported Classrooms using Transmodal Ordered Network Analysis
Dec 17, 2023


Learning analytics research increasingly studies classroom learning with AI-based systems through rich contextual data from outside these systems, especially student-teacher interactions. One key challenge in leveraging such data is generating meaningful insights into effective teacher practices. Quantitative ethnography bears the potential to close this gap by combining multimodal data streams into networks of co-occurring behavior that drive insight into favorable learning conditions. The present study uses transmodal ordered network analysis to understand effective teacher practices in relationship to traditional metrics of in-system learning in a mathematics classroom working with AI tutors. Incorporating teacher practices captured by position tracking and human observation codes into modeling significantly improved the inference of how efficiently students improved in the AI tutor beyond a model with tutor log data features only. Comparing teacher practices by student learning rates, we find that students with low learning rates exhibited more hint use after monitoring. However, after an extended visit, students with low learning rates showed learning behavior similar to their high learning rate peers, achieving repeated correct attempts in the tutor. Observation notes suggest conceptual and procedural support differences can help explain visit effectiveness. Taken together, offering early conceptual support to students with low learning rates could make classroom practice with AI tutors more effective. This study advances the scientific understanding of effective teacher practice in classrooms learning with AI tutors and methodologies to make such practices visible.
Using Think-Aloud Data to Understand Relations between Self-Regulation Cycle Characteristics and Student Performance in Intelligent Tutoring Systems
Dec 09, 2023



Numerous studies demonstrate the importance of self-regulation during learning by problem-solving. Recent work in learning analytics has largely examined students' use of SRL concerning overall learning gains. Limited research has related SRL to in-the-moment performance differences among learners. The present study investigates SRL behaviors in relationship to learners' moment-by-moment performance while working with intelligent tutoring systems for stoichiometry chemistry. We demonstrate the feasibility of labeling SRL behaviors based on AI-generated think-aloud transcripts, identifying the presence or absence of four SRL categories (processing information, planning, enacting, and realizing errors) in each utterance. Using the SRL codes, we conducted regression analyses to examine how the use of SRL in terms of presence, frequency, cyclical characteristics, and recency relate to student performance on subsequent steps in multi-step problems. A model considering students' SRL cycle characteristics outperformed a model only using in-the-moment SRL assessment. In line with theoretical predictions, students' actions during earlier, process-heavy stages of SRL cycles exhibited lower moment-by-moment correctness during problem-solving than later SRL cycle stages. We discuss system re-design opportunities to add SRL support during stages of processing and paths forward for using machine learning to speed research depending on the assessment of SRL based on transcription of think-aloud data.
Comparative Analysis of GPT-4 and Human Graders in Evaluating Praise Given to Students in Synthetic Dialogues
Jul 05, 2023


Research suggests that providing specific and timely feedback to human tutors enhances their performance. However, it presents challenges due to the time-consuming nature of assessing tutor performance by human evaluators. Large language models, such as the AI-chatbot ChatGPT, hold potential for offering constructive feedback to tutors in practical settings. Nevertheless, the accuracy of AI-generated feedback remains uncertain, with scant research investigating the ability of models like ChatGPT to deliver effective feedback. In this work-in-progress, we evaluate 30 dialogues generated by GPT-4 in a tutor-student setting. We use two different prompting approaches, the zero-shot chain of thought and the few-shot chain of thought, to identify specific components of effective praise based on five criteria. These approaches are then compared to the results of human graders for accuracy. Our goal is to assess the extent to which GPT-4 can accurately identify each praise criterion. We found that both zero-shot and few-shot chain of thought approaches yield comparable results. GPT-4 performs moderately well in identifying instances when the tutor offers specific and immediate praise. However, GPT-4 underperforms in identifying the tutor's ability to deliver sincere praise, particularly in the zero-shot prompting scenario where examples of sincere tutor praise statements were not provided. Future work will focus on enhancing prompt engineering, developing a more general tutoring rubric, and evaluating our method using real-life tutoring dialogues.
Designing for human-AI complementarity in K-12 education
Apr 02, 2021
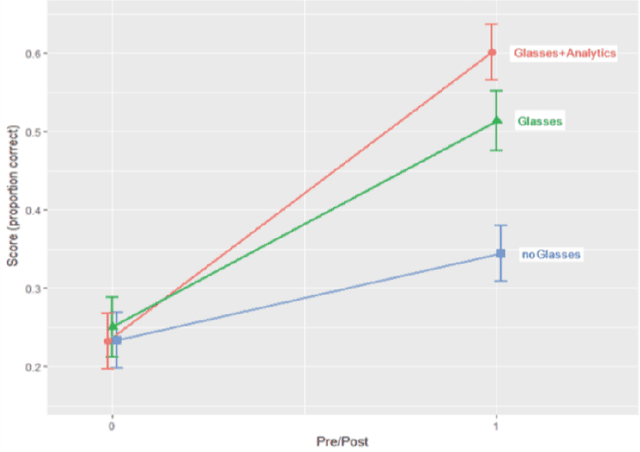
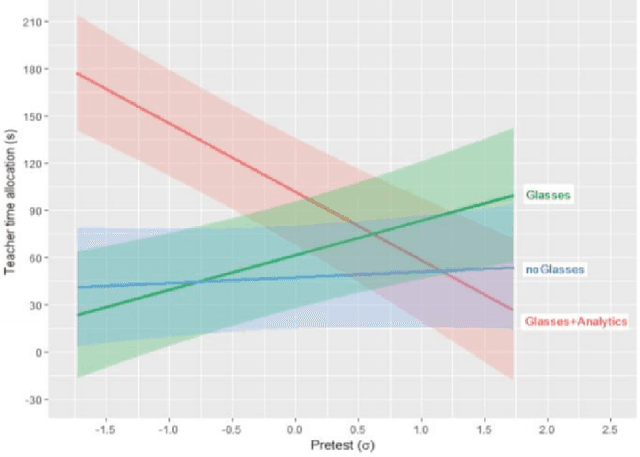
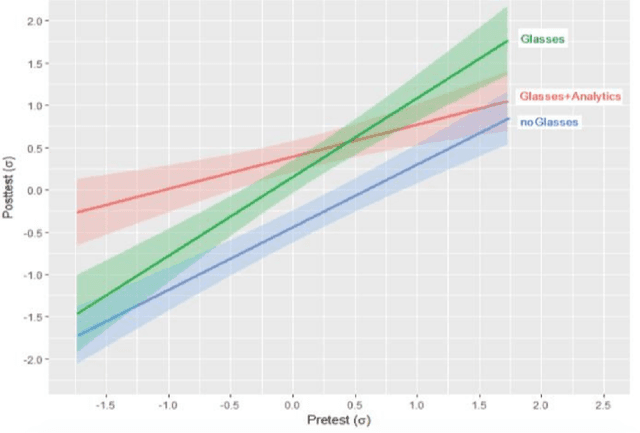
Recent work has explored how complementary strengths of humans and artificial intelligence (AI) systems might be productively combined. However, successful forms of human-AI partnership have rarely been demonstrated in real-world settings. We present the iterative design and evaluation of Lumilo, smart glasses that help teachers help their students in AI-supported classrooms by presenting real-time analytics about students' learning, metacognition, and behavior. Results from a field study conducted in K-12 classrooms indicate that students learn more when teachers and AI tutors work together during class. We discuss implications for the design of human-AI partnerships, arguing for participatory approaches to research in this area, and for principled approaches to studying human-AI decision-making in real-world contexts.