 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI2T: Building Trustable AI Tutors by Interactively Teaching a Self-Aware Learning Agent
Nov 26, 2024AI2T is an interactively teachable AI for authoring intelligent tutoring systems (ITSs). Authors tutor AI2T by providing a few step-by-step solutions and then grading AI2T's own problem-solving attempts. From just 20-30 minutes of interactive training, AI2T can induce robust rules for step-by-step solution tracking (i.e., model-tracing). As AI2T learns it can accurately estimate its certainty of performing correctly on unseen problem steps using STAND: a self-aware precondition learning algorithm that outperforms state-of-the-art methods like XGBoost. Our user study shows that authors can use STAND's certainty heuristic to estimate when AI2T has been trained on enough diverse problems to induce correct and complete model-tracing programs. AI2T-induced programs are more reliable than hallucination-prone LLMs and prior authoring-by-tutoring approaches. With its self-aware induction of hierarchical rules, AI2T offers a path toward trustable data-efficient authoring-by-tutoring for complex ITSs that normally require as many as 200-300 hours of programming per hour of instruction.
TRESTLE: A Model of Concept Formation in Structured Domains
Oct 14, 2024The literature on concept formation has demonstrated that humans are capable of learning concepts incrementally, with a variety of attribute types, and in both supervised and unsupervised settings. Many models of concept formation focus on a subset of these characteristics, but none account for all of them. In this paper, we present TRESTLE, an incremental account of probabilistic concept formation in structured domains that unifies prior concept learning models. TRESTLE works by creating a hierarchical categorization tree that can be used to predict missing attribute values and cluster sets of examples into conceptually meaningful groups. It updates its knowledge by partially matching novel structures and sorting them into its categorization tree. Finally, the system supports mixed-data representations, including nominal, numeric, relational, and component attributes. We evaluate TRESTLE's performance on a supervised learning task and an unsupervised clustering task. For both tasks, we compare it to a nonincremental model and to human participants. We find that this new categorization model is competitive with the nonincremental approach and more closely approximates human behavior on both tasks. These results serve as an initial demonstration of TRESTLE's capabilities and show that, by taking key characteristics of human learning into account, it can better model behavior than approaches that ignore them.
* 20 pages, 6 figures, 1 table
Leveraging Cluster Analysis to Understand Educational Game Player Experiences and Support Design
Oct 18, 2022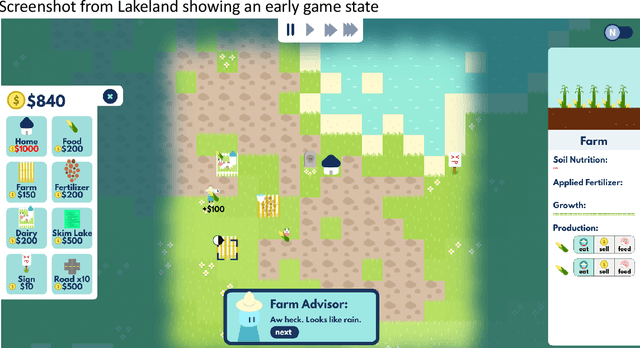
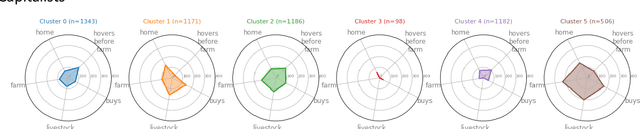

The ability for an educational game designer to understand their audience's play styles and resulting experience is an essential tool for improving their game's design. As a game is subjected to large-scale player testing, the designers require inexpensive, automated methods for categorizing patterns of player-game interactions. In this paper we present a simple, reusable process using best practices for data clustering, feasible for use within a small educational game studio. We utilize the method to analyze a real-time strategy game, processing game telemetry data to determine categories of players based on their in-game actions, the feedback they received, and their progress through the game. An interpretive analysis of these clusters results in actionable insights for the game's designers.
Decomposed Inductive Procedure Learning
Oct 25, 2021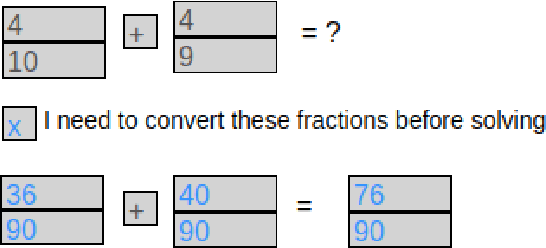
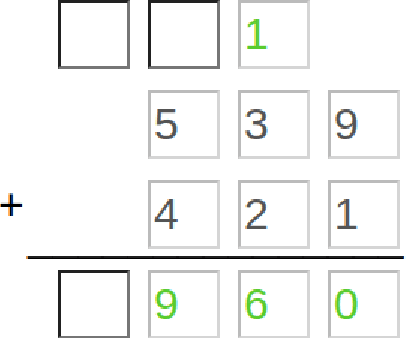
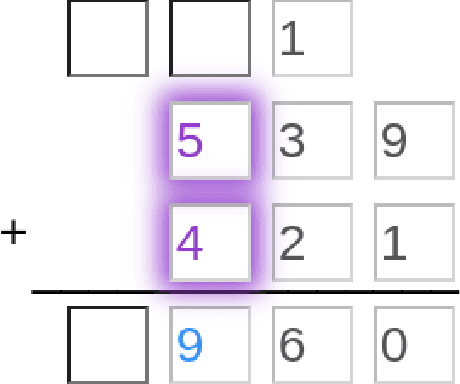
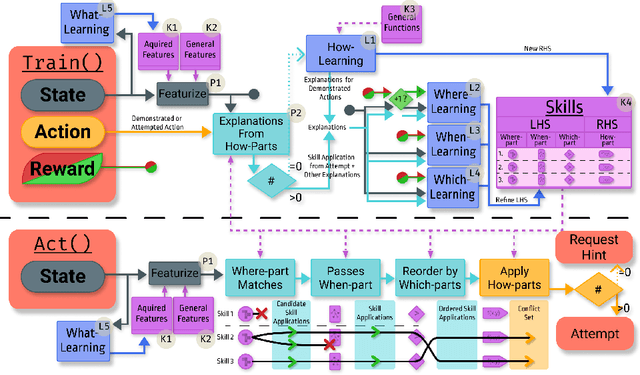
Recent advances in machine learning have made it possible to train artificially intelligent agents that perform with super-human accuracy on a great diversity of complex tasks. However, the process of training these capabilities often necessitates millions of annotated examples -- far more than humans typically need in order to achieve a passing level of mastery on similar tasks. Thus, while contemporary methods in machine learning can produce agents that exhibit super-human performance, their rate of learning per opportunity in many domains is decidedly lower than human-learning. In this work we formalize a theory of Decomposed Inductive Procedure Learning (DIPL) that outlines how different forms of inductive symbolic learning can be used in combination to build agents that learn educationally relevant tasks such as mathematical, and scientific procedures, at a rate similar to human learners. We motivate the construction of this theory along Marr's concepts of the computational, algorithmic, and implementation levels of cognitive modeling, and outline at the computational-level six learning capacities that must be achieved to accurately model human learning. We demonstrate that agents built along the DIPL theory are amenable to satisfying these capacities, and demonstrate, both empirically and theoretically, that DIPL enables the creation of agents that exhibit human-like learning performance.