 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORGI: Efficient Pattern Matching With Quadratic Guarantees
Nov 17, 2025Rule-based systems must solve complex matching problems within tight time constraints to be effective in real-time applications, such as planning and reactive control for AI agents, as well as low-latency relational database querying. Pattern-matching systems can encounter issues where exponential time and space are required to find matches for rules with many underconstrained variables, or which produce combinatorial intermediate partial matches (but are otherwise well-constrained). When online AI systems automatically generate rules from example-driven induction or code synthesis, they can easily produce worst-case matching patterns that slow or halt program execution by exceeding available memory. In our own work with cognitive systems that learn from example, we've found that aggressive forms of anti-unification-based generalization can easily produce these circumstances. To make these systems practical without hand-engineering constraints or succumbing to unpredictable failure modes, we introduce a new matching algorithm called CORGI (Collection-Oriented Relational Graph Iteration). Unlike RETE-based approaches, CORGI offers quadratic time and space guarantees for finding single satisficing matches, and the ability to iteratively stream subsequent matches without committing entire conflict sets to memory. CORGI differs from RETE in that it does not have a traditional $β$-memory for collecting partial matches. Instead, CORGI takes a two-step approach: a graph of grounded relations is built/maintained in a forward pass, and an iterator generates matches as needed by working backward through the graph. This approach eliminates the high-latency delays and memory overflows that can result from populating full conflict sets. In a performance evaluation, we demonstrate that CORGI significantly outperforms RETE implementations from SOAR and OPS5 on a simple combinatorial matching task.
TutorGym: A Testbed for Evaluating AI Agents as Tutors and Students
May 02, 2025Recent improvements in large language model (LLM) performance on academic benchmarks, such as MATH and GSM8K, have emboldened their use as standalone tutors and as simulations of human learning. However, these new applications require more than evaluations of final solution generation. We introduce TutorGym to evaluate these applications more directly. TutorGym is a standard interface for testing artificial intelligence (AI) agents within existing intelligent tutoring systems (ITS) that have been tested and refined in classroom studies, including Cognitive Tutors (CTAT), Apprentice Tutors, and OATutors. TutorGym is more than a simple problem-solution benchmark, it situates AI agents within the interactive interfaces of existing ITSs. At each step of problem-solving, AI agents are asked what they would do as a tutor or as a learner. As tutors, AI agents are prompted to provide tutoring support -- such as generating examples, hints, and step-level correctness feedback -- which can be evaluated directly against the adaptive step-by-step support provided by existing ITSs. As students, agents directly learn from ITS instruction, and their mistakes and learning trajectories can be compared to student data. TutorGym establishes a common framework for training and evaluating diverse AI agents, including LLMs, computational models of learning, and reinforcement learning agents, within a growing suite of learning environments. Currently, TutorGym includes 223 different tutor domains. In an initial evaluation, we find that current LLMs are poor at tutoring -- none did better than chance at labeling incorrect actions, and next-step actions were correct only ~52-70% of the time -- but they could produce remarkably human-like learning curves when trained as students with in-context learning.
AI2T: Building Trustable AI Tutors by Interactively Teaching a Self-Aware Learning Agent
Nov 26, 2024AI2T is an interactively teachable AI for authoring intelligent tutoring systems (ITSs). Authors tutor AI2T by providing a few step-by-step solutions and then grading AI2T's own problem-solving attempts. From just 20-30 minutes of interactive training, AI2T can induce robust rules for step-by-step solution tracking (i.e., model-tracing). As AI2T learns it can accurately estimate its certainty of performing correctly on unseen problem steps using STAND: a self-aware precondition learning algorithm that outperforms state-of-the-art methods like XGBoost. Our user study shows that authors can use STAND's certainty heuristic to estimate when AI2T has been trained on enough diverse problems to induce correct and complete model-tracing programs. AI2T-induced programs are more reliable than hallucination-prone LLMs and prior authoring-by-tutoring approaches. With its self-aware induction of hierarchical rules, AI2T offers a path toward trustable data-efficient authoring-by-tutoring for complex ITSs that normally require as many as 200-300 hours of programming per hour of instruction.
STAND: Data-Efficient and Self-Aware Precondition Induction for Interactive Task Learning
Sep 11, 2024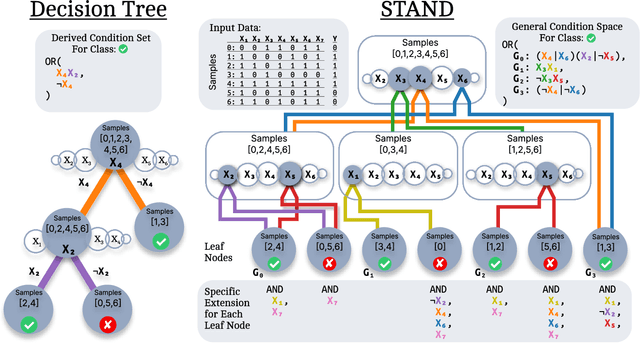

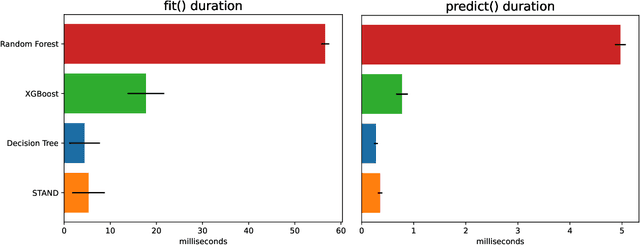
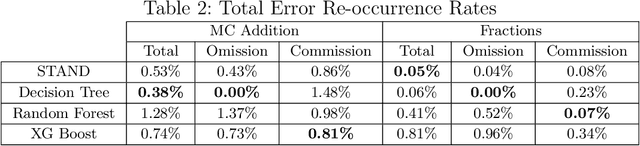
STAND is a data-efficient and computationally efficient machine learning approach that produces better classification accuracy than popular approaches like XGBoost on small-data tabular classification problems like learning rule preconditions from interactive training. STAND accounts for a complete set of good candidate generalizations instead of selecting a single generalization by breaking ties randomly. STAND can use any greedy concept construction strategy, like decision tree learning or sequential covering, and build a structure that approximates a version space over disjunctive normal logical statements. Unlike candidate elimination approaches to version-space learning, STAND does not suffer from issues of version-space collapse from noisy data nor is it restricted to learning strictly conjunctive concepts. More importantly, STAND can produce a measure called instance certainty that can predict increases in holdout set performance and has high utility as an active-learning heuristic. Instance certainty enables STAND to be self-aware of its own learning: it knows when it learns and what example will help it learn the most. We illustrate that instance certainty has desirable properties that can help users select next training problems, and estimate when training is complete in applications where users interactively teach an AI a complex program.
Decomposed Inductive Procedure Learning
Oct 25, 2021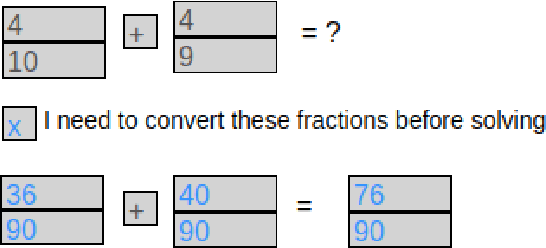
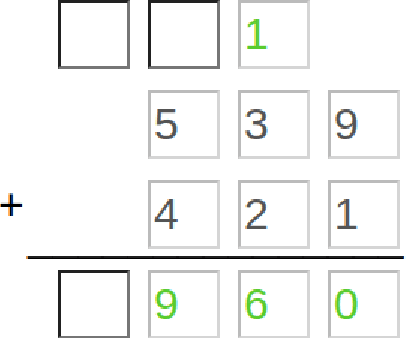
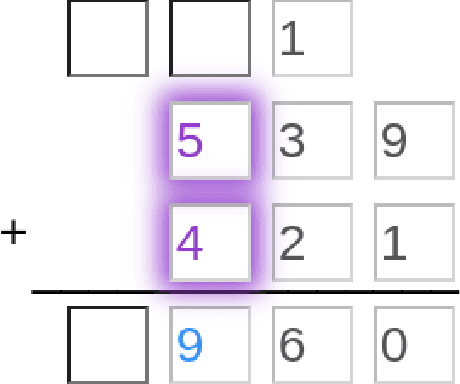
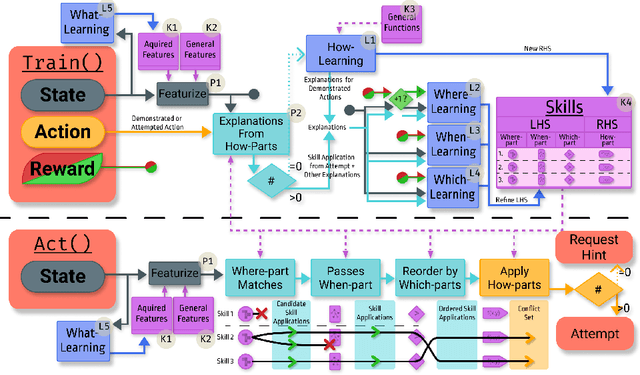
Recent advances in machine learning have made it possible to train artificially intelligent agents that perform with super-human accuracy on a great diversity of complex tasks. However, the process of training these capabilities often necessitates millions of annotated examples -- far more than humans typically need in order to achieve a passing level of mastery on similar tasks. Thus, while contemporary methods in machine learning can produce agents that exhibit super-human performance, their rate of learning per opportunity in many domains is decidedly lower than human-learning. In this work we formalize a theory of Decomposed Inductive Procedure Learning (DIPL) that outlines how different forms of inductive symbolic learning can be used in combination to build agents that learn educationally relevant tasks such as mathematical, and scientific procedures, at a rate similar to human learners. We motivate the construction of this theory along Marr's concepts of the computational, algorithmic, and implementation levels of cognitive modeling, and outline at the computational-level six learning capacities that must be achieved to accurately model human learning. We demonstrate that agents built along the DIPL theory are amenable to satisfying these capacities, and demonstrate, both empirically and theoretically, that DIPL enables the creation of agents that exhibit human-like learning performance.